 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObject-Centric Domain Randomization for 3D Shape Reconstruction in the Wild
Mar 21, 2024One of the biggest challenges in single-view 3D shape reconstruction in the wild is the scarcity of <3D shape, 2D image>-paired data from real-world environments. Inspired by remarkable achievements via domain randomization, we propose ObjectDR which synthesizes such paired data via a random simulation of visual variations in object appearances and backgrounds. Our data synthesis framework exploits a conditional generative model (e.g., ControlNet) to generate images conforming to spatial conditions such as 2.5D sketches, which are obtainable through a rendering process of 3D shapes from object collections (e.g., Objaverse-XL). To simulate diverse variations while preserving object silhouettes embedded in spatial conditions, we also introduce a disentangled framework which leverages an initial object guidance. After synthesizing a wide range of data, we pre-train a model on them so that it learns to capture a domain-invariant geometry prior which is consistent across various domains. We validate its effectiveness by substantially improving 3D shape reconstruction models on a real-world benchmark. In a scale-up evaluation, our pre-training achieves 23.6% superior results compared with the pre-training on high-quality computer graphics renderings.
PromptStyler: Prompt-driven Style Generation for Source-free Domain Generalization
Aug 15, 2023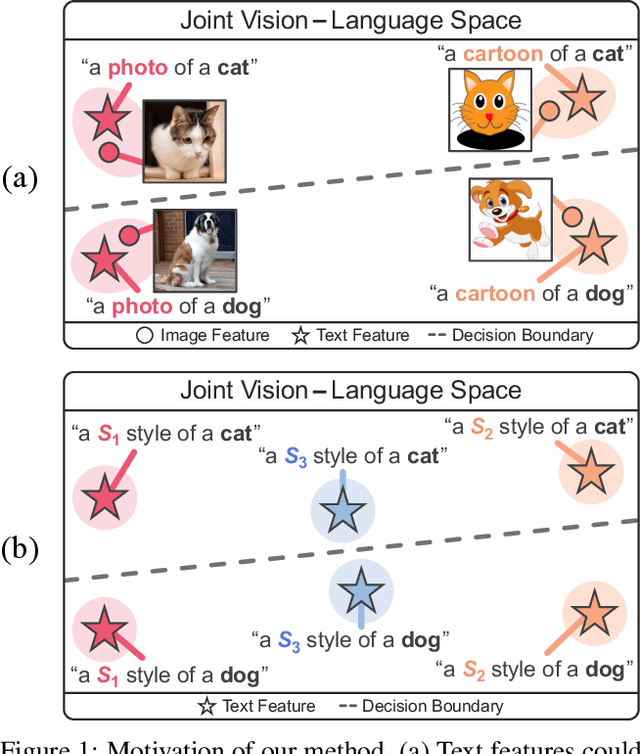
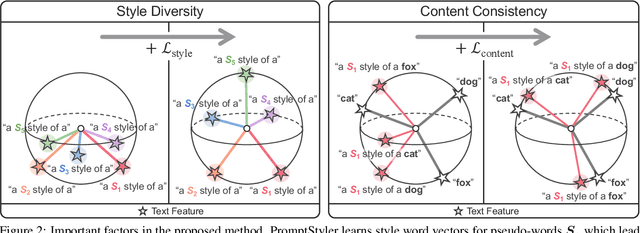
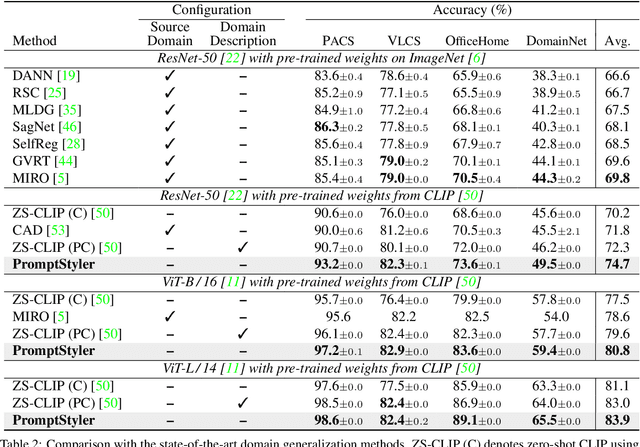
In a joint vision-language space, a text feature (e.g., from "a photo of a dog") could effectively represent its relevant image features (e.g., from dog photos). Also, a recent study has demonstrated the cross-modal transferability phenomenon of this joint space. From these observations, we propose PromptStyler which simulates various distribution shifts in the joint space by synthesizing diverse styles via prompts without using any images to deal with source-free domain generalization. The proposed method learns to generate a variety of style features (from "a S* style of a") via learnable style word vectors for pseudo-words S*. To ensure that learned styles do not distort content information, we force style-content features (from "a S* style of a [class]") to be located nearby their corresponding content features (from "[class]") in the joint vision-language space. After learning style word vectors, we train a linear classifier using synthesized style-content features. PromptStyler achieves the state of the art on PACS, VLCS, OfficeHome and DomainNet, even though it does not require any images for training.
Cross-Attention of Disentangled Modalities for 3D Human Mesh Recovery with Transformers
Jul 27, 2022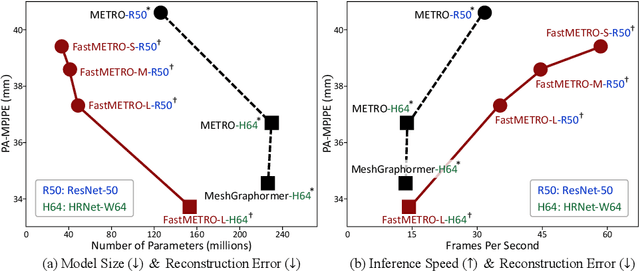

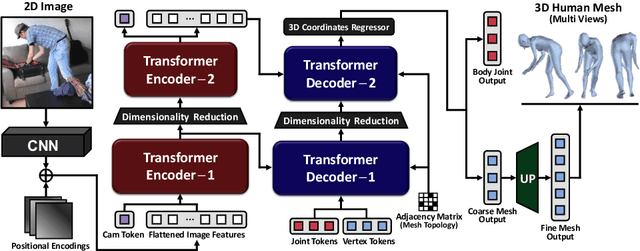
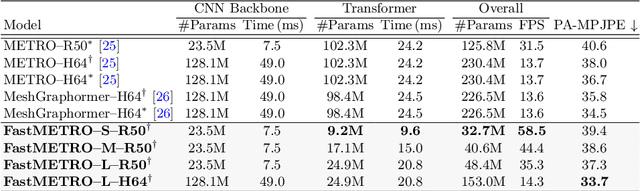
Transformer encoder architectures have recently achieved state-of-the-art results on monocular 3D human mesh reconstruction, but they require a substantial number of parameters and expensive computations. Due to the large memory overhead and slow inference speed, it is difficult to deploy such models for practical use. In this paper, we propose a novel transformer encoder-decoder architecture for 3D human mesh reconstruction from a single image, called FastMETRO. We identify the performance bottleneck in the encoder-based transformers is caused by the token design which introduces high complexity interactions among input tokens. We disentangle the interactions via an encoder-decoder architecture, which allows our model to demand much fewer parameters and shorter inference time. In addition, we impose the prior knowledge of human body's morphological relationship via attention masking and mesh upsampling operations, which leads to faster convergence with higher accuracy. Our FastMETRO improves the Pareto-front of accuracy and efficiency, and clearly outperforms image-based methods on Human3.6M and 3DPW. Furthermore, we validate its generalizability on FreiHAND.
Collaborative Transformers for Grounded Situation Recognition
Mar 30, 2022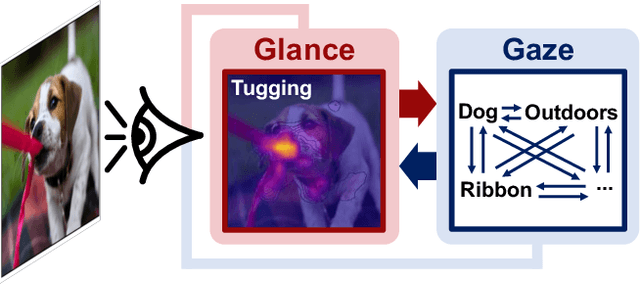
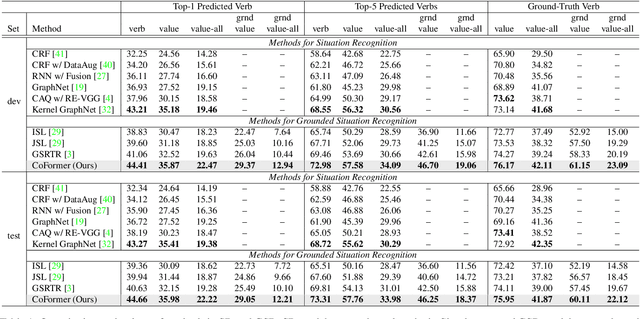
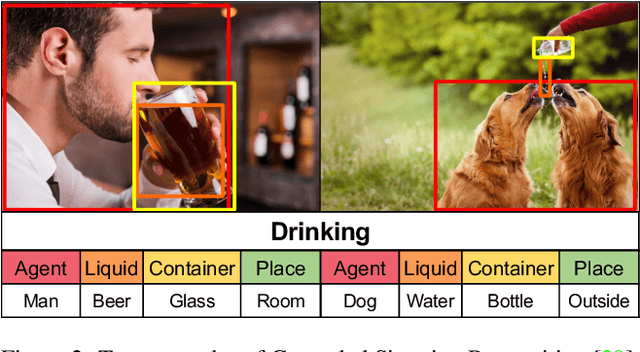
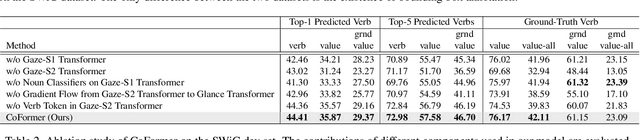
Grounded situation recognition is the task of predicting the main activity, entities playing certain roles within the activity, and bounding-box groundings of the entities in the given image. To effectively deal with this challenging task, we introduce a novel approach where the two processes for activity classification and entity estimation are interactive and complementary. To implement this idea, we propose Collaborative Glance-Gaze TransFormer (CoFormer) that consists of two modules: Glance transformer for activity classification and Gaze transformer for entity estimation. Glance transformer predicts the main activity with the help of Gaze transformer that analyzes entities and their relations, while Gaze transformer estimates the grounded entities by focusing only on the entities relevant to the activity predicted by Glance transformer. Our CoFormer achieves the state of the art in all evaluation metrics on the SWiG dataset. Training code and model weights are available at https://github.com/jhcho99/CoFormer.
Grounded Situation Recognition with Transformers
Nov 19, 2021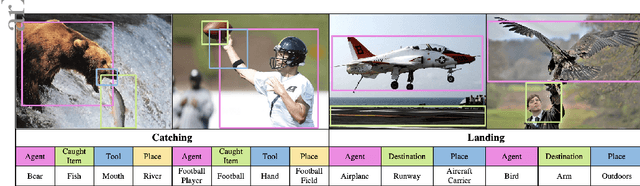
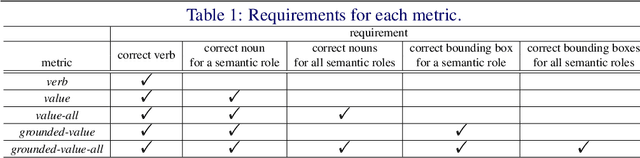
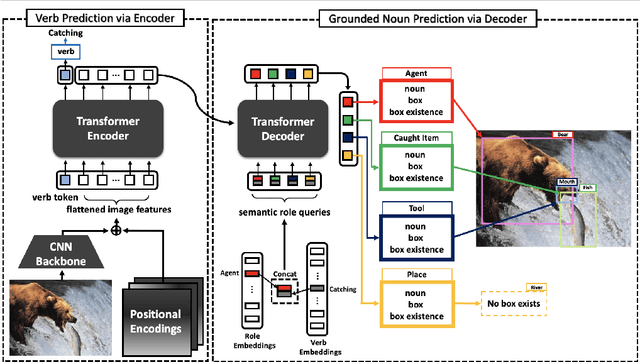

Grounded Situation Recognition (GSR) is the task that not only classifies a salient action (verb), but also predicts entities (nouns) associated with semantic roles and their locations in the given image. Inspired by the remarkable success of Transformers in vision tasks, we propose a GSR model based on a Transformer encoder-decoder architecture. The attention mechanism of our model enables accurate verb classification by capturing high-level semantic feature of an image effectively, and allows the model to flexibly deal with the complicated and image-dependent relations between entities for improved noun classification and localization. Our model is the first Transformer architecture for GSR, and achieves the state of the art in every evaluation metric on the SWiG benchmark. Our code is available at https://github.com/jhcho99/gsrtr .