 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Reliable Test-Time Adaptation: Style Invariance as a Correctness Likelihood
Dec 08, 2025Test-time adaptation (TTA) enables efficient adaptation of deployed models, yet it often leads to poorly calibrated predictive uncertainty - a critical issue in high-stakes domains such as autonomous driving, finance, and healthcare. Existing calibration methods typically assume fixed models or static distributions, resulting in degraded performance under real-world, dynamic test conditions. To address these challenges, we introduce Style Invariance as a Correctness Likelihood (SICL), a framework that leverages style-invariance for robust uncertainty estimation. SICL estimates instance-wise correctness likelihood by measuring prediction consistency across style-altered variants, requiring only the model's forward pass. This makes it a plug-and-play, backpropagation-free calibration module compatible with any TTA method. Comprehensive evaluations across four baselines, five TTA methods, and two realistic scenarios with three model architecture demonstrate that SICL reduces calibration error by an average of 13 percentage points compared to conventional calibration approaches.
PromptStyler: Prompt-driven Style Generation for Source-free Domain Generalization
Aug 15, 2023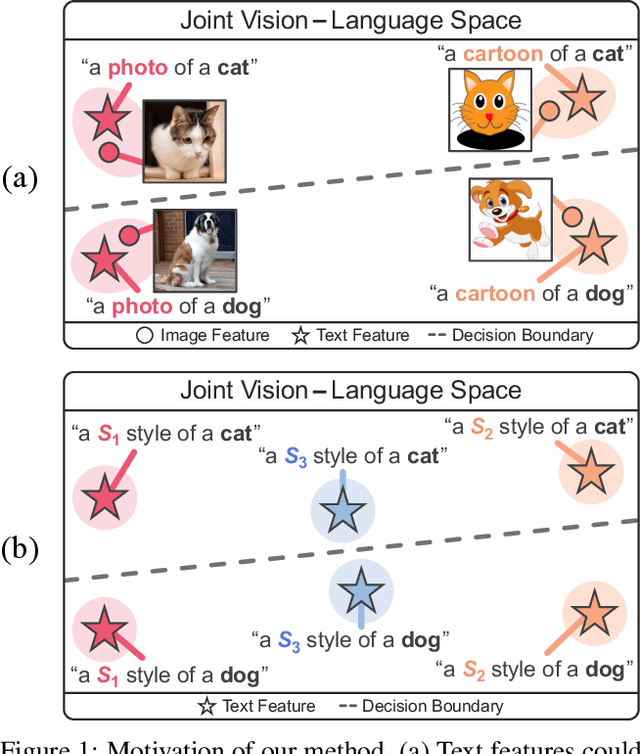
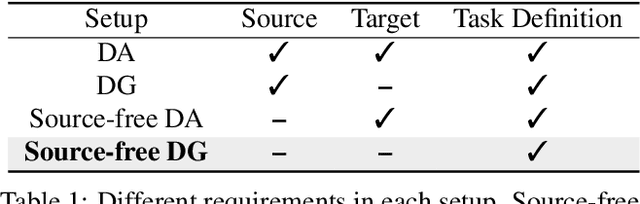
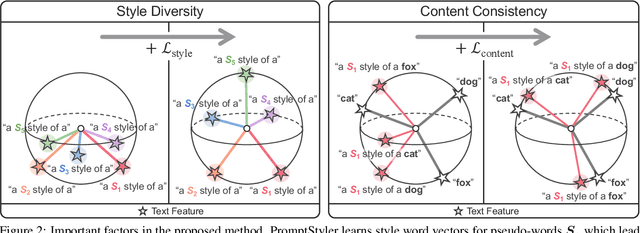
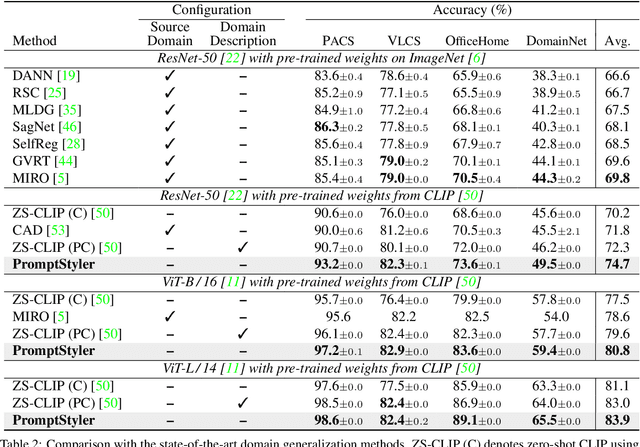
In a joint vision-language space, a text feature (e.g., from "a photo of a dog") could effectively represent its relevant image features (e.g., from dog photos). Also, a recent study has demonstrated the cross-modal transferability phenomenon of this joint space. From these observations, we propose PromptStyler which simulates various distribution shifts in the joint space by synthesizing diverse styles via prompts without using any images to deal with source-free domain generalization. The proposed method learns to generate a variety of style features (from "a S* style of a") via learnable style word vectors for pseudo-words S*. To ensure that learned styles do not distort content information, we force style-content features (from "a S* style of a [class]") to be located nearby their corresponding content features (from "[class]") in the joint vision-language space. After learning style word vectors, we train a linear classifier using synthesized style-content features. PromptStyler achieves the state of the art on PACS, VLCS, OfficeHome and DomainNet, even though it does not require any images for training.
GCISG: Guided Causal Invariant Learning for Improved Syn-to-real Generalization
Aug 22, 2022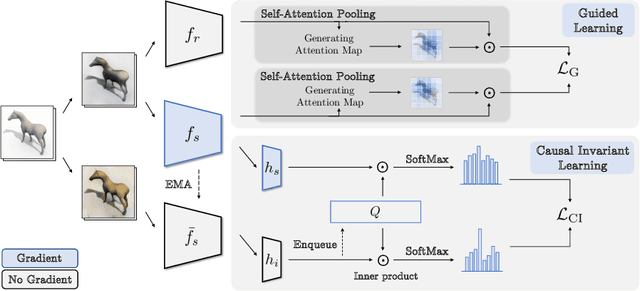
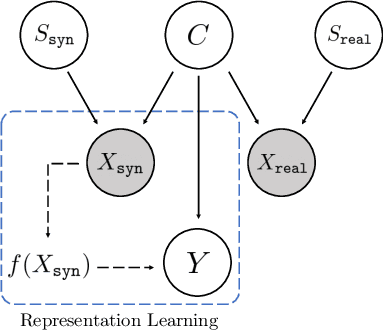
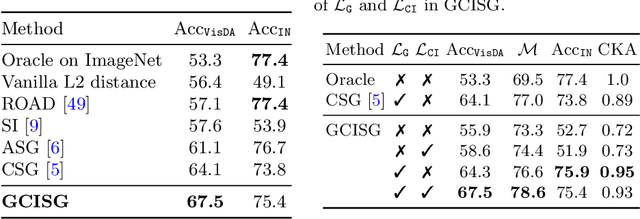
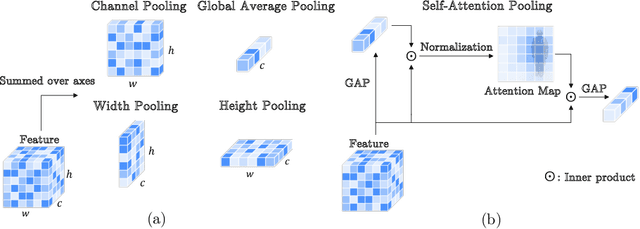
Training a deep learning model with artificially generated data can be an alternative when training data are scarce, yet it suffers from poor generalization performance due to a large domain gap. In this paper, we characterize the domain gap by using a causal framework for data generation. We assume that the real and synthetic data have common content variables but different style variables. Thus, a model trained on synthetic dataset might have poor generalization as the model learns the nuisance style variables. To that end, we propose causal invariance learning which encourages the model to learn a style-invariant representation that enhances the syn-to-real generalization. Furthermore, we propose a simple yet effective feature distillation method that prevents catastrophic forgetting of semantic knowledge of the real domain. In sum, we refer to our method as Guided Causal Invariant Syn-to-real Generalization that effectively improves the performance of syn-to-real generalization. We empirically verify the validity of proposed methods, and especially, our method achieves state-of-the-art on visual syn-to-real domain generalization tasks such as image classification and semantic segmentation.