 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMix from Failure: Confusion-Pairing Mixup for Long-Tailed Recognition
Nov 12, 2024



Long-tailed image recognition is a computer vision problem considering a real-world class distribution rather than an artificial uniform. Existing methods typically detour the problem by i) adjusting a loss function, ii) decoupling classifier learning, or iii) proposing a new multi-head architecture called experts. In this paper, we tackle the problem from a different perspective to augment a training dataset to enhance the sample diversity of minority classes. Specifically, our method, namely Confusion-Pairing Mixup (CP-Mix), estimates the confusion distribution of the model and handles the data deficiency problem by augmenting samples from confusion pairs in real-time. In this way, CP-Mix trains the model to mitigate its weakness and distinguish a pair of classes it frequently misclassifies. In addition, CP-Mix utilizes a novel mixup formulation to handle the bias in decision boundaries that originated from the imbalanced dataset. Extensive experiments demonstrate that CP-Mix outperforms existing methods for long-tailed image recognition and successfully relieves the confusion of the classifier.
Collaborative Transformers for Grounded Situation Recognition
Mar 30, 2022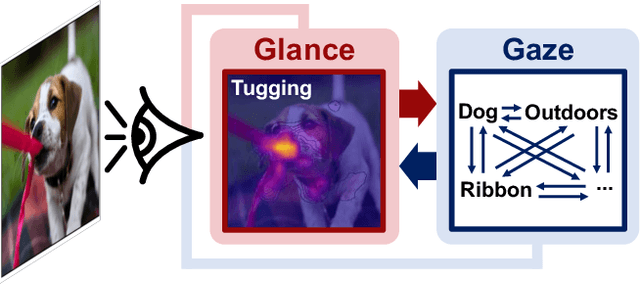
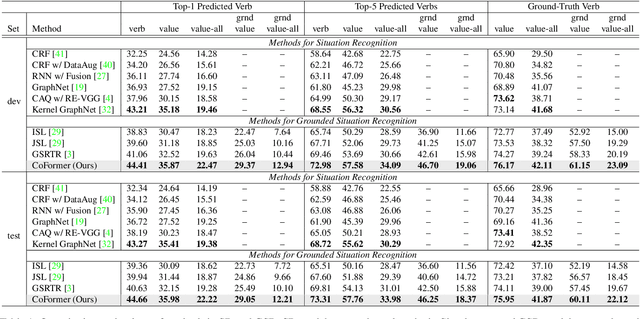
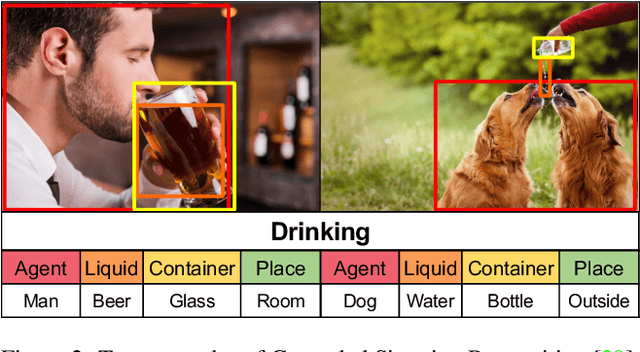
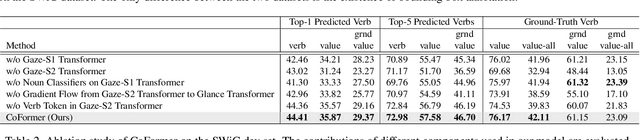
Grounded situation recognition is the task of predicting the main activity, entities playing certain roles within the activity, and bounding-box groundings of the entities in the given image. To effectively deal with this challenging task, we introduce a novel approach where the two processes for activity classification and entity estimation are interactive and complementary. To implement this idea, we propose Collaborative Glance-Gaze TransFormer (CoFormer) that consists of two modules: Glance transformer for activity classification and Gaze transformer for entity estimation. Glance transformer predicts the main activity with the help of Gaze transformer that analyzes entities and their relations, while Gaze transformer estimates the grounded entities by focusing only on the entities relevant to the activity predicted by Glance transformer. Our CoFormer achieves the state of the art in all evaluation metrics on the SWiG dataset. Training code and model weights are available at https://github.com/jhcho99/CoFormer.
Grounded Situation Recognition with Transformers
Nov 19, 2021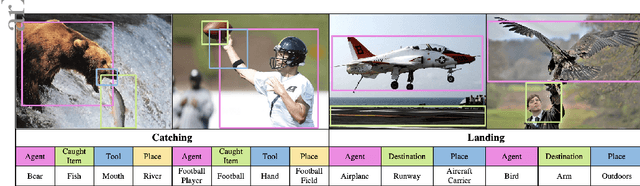
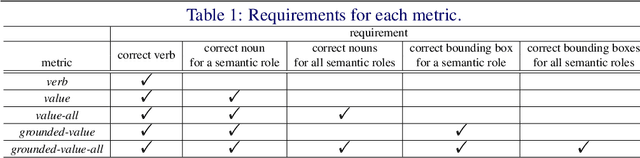
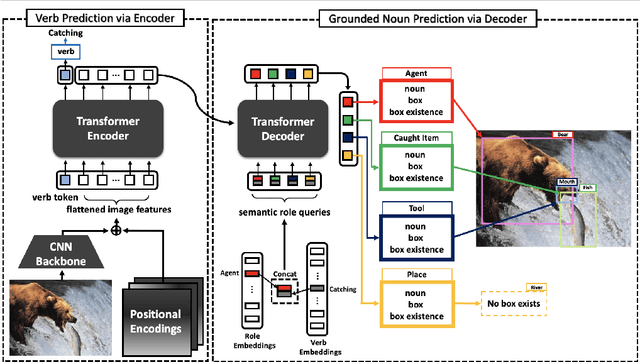

Grounded Situation Recognition (GSR) is the task that not only classifies a salient action (verb), but also predicts entities (nouns) associated with semantic roles and their locations in the given image. Inspired by the remarkable success of Transformers in vision tasks, we propose a GSR model based on a Transformer encoder-decoder architecture. The attention mechanism of our model enables accurate verb classification by capturing high-level semantic feature of an image effectively, and allows the model to flexibly deal with the complicated and image-dependent relations between entities for improved noun classification and localization. Our model is the first Transformer architecture for GSR, and achieves the state of the art in every evaluation metric on the SWiG benchmark. Our code is available at https://github.com/jhcho99/gsrtr .