 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMV-MLM: Bridging Multi-View Mammography and Language for Breast Cancer Diagnosis and Risk Prediction
Oct 30, 2025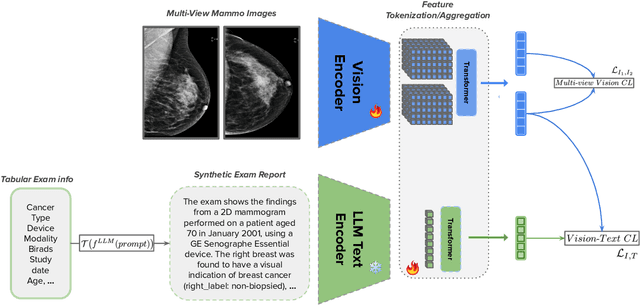
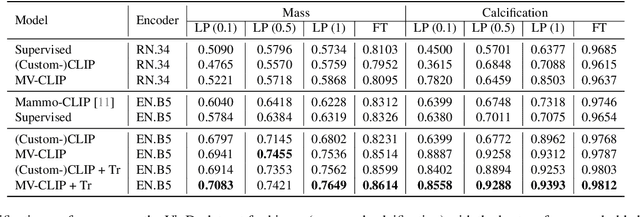


Large annotated datasets are essential for training robust Computer-Aided Diagnosis (CAD) models for breast cancer detection or risk prediction. However, acquiring such datasets with fine-detailed annotation is both costly and time-consuming. Vision-Language Models (VLMs), such as CLIP, which are pre-trained on large image-text pairs, offer a promising solution by enhancing robustness and data efficiency in medical imaging tasks. This paper introduces a novel Multi-View Mammography and Language Model for breast cancer classification and risk prediction, trained on a dataset of paired mammogram images and synthetic radiology reports. Our MV-MLM leverages multi-view supervision to learn rich representations from extensive radiology data by employing cross-modal self-supervision across image-text pairs. This includes multiple views and the corresponding pseudo-radiology reports. We propose a novel joint visual-textual learning strategy to enhance generalization and accuracy performance over different data types and tasks to distinguish breast tissues or cancer characteristics(calcification, mass) and utilize these patterns to understand mammography images and predict cancer risk. We evaluated our method on both private and publicly available datasets, demonstrating that the proposed model achieves state-of-the-art performance in three classification tasks: (1) malignancy classification, (2) subtype classification, and (3) image-based cancer risk prediction. Furthermore, the model exhibits strong data efficiency, outperforming existing fully supervised or VLM baselines while trained on synthetic text reports and without the need for actual radiology reports.
Dual Mixture-of-Experts Framework for Discrete-Time Survival Analysis
Oct 29, 2025Survival analysis is a task to model the time until an event of interest occurs, widely used in clinical and biomedical research. A key challenge is to model patient heterogeneity while also adapting risk predictions to both individual characteristics and temporal dynamics. We propose a dual mixture-of-experts (MoE) framework for discrete-time survival analysis. Our approach combines a feature-encoder MoE for subgroup-aware representation learning with a hazard MoE that leverages patient features and time embeddings to capture temporal dynamics. This dual-MoE design flexibly integrates with existing deep learning based survival pipelines. On METABRIC and GBSG breast cancer datasets, our method consistently improves performance, boosting the time-dependent C-index up to 0.04 on the test sets, and yields further gains when incorporated into the Consurv framework.
Extreme Point Supervised Instance Segmentation
Jun 04, 2024This paper introduces a novel approach to learning instance segmentation using extreme points, i.e., the topmost, leftmost, bottommost, and rightmost points, of each object. These points are readily available in the modern bounding box annotation process while offering strong clues for precise segmentation, and thus allows to improve performance at the same annotation cost with box-supervised methods. Our work considers extreme points as a part of the true instance mask and propagates them to identify potential foreground and background points, which are all together used for training a pseudo label generator. Then pseudo labels given by the generator are in turn used for supervised learning of our final model. On three public benchmarks, our method significantly outperforms existing box-supervised methods, further narrowing the gap with its fully supervised counterpart. In particular, our model generates high-quality masks when a target object is separated into multiple parts, where previous box-supervised methods often fail.
Grounded Situation Recognition with Transformers
Nov 19, 2021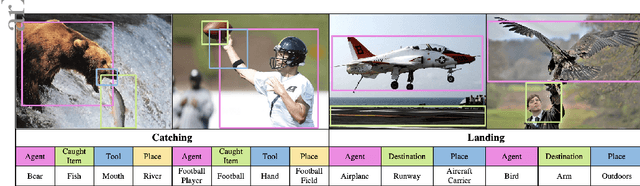
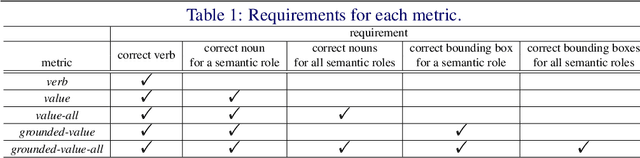
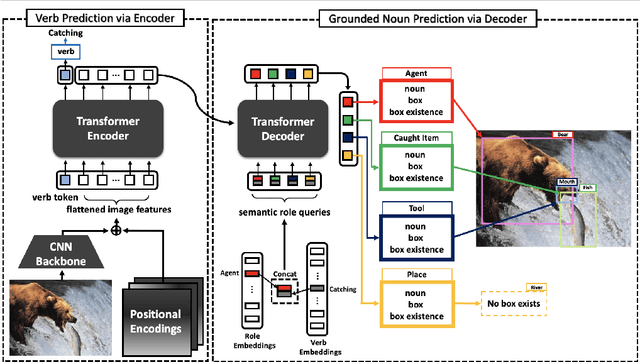

Grounded Situation Recognition (GSR) is the task that not only classifies a salient action (verb), but also predicts entities (nouns) associated with semantic roles and their locations in the given image. Inspired by the remarkable success of Transformers in vision tasks, we propose a GSR model based on a Transformer encoder-decoder architecture. The attention mechanism of our model enables accurate verb classification by capturing high-level semantic feature of an image effectively, and allows the model to flexibly deal with the complicated and image-dependent relations between entities for improved noun classification and localization. Our model is the first Transformer architecture for GSR, and achieves the state of the art in every evaluation metric on the SWiG benchmark. Our code is available at https://github.com/jhcho99/gsrtr .