 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-time prediction of breast cancer sites using deformation-aware graph neural network
Nov 17, 2025Early diagnosis of breast cancer is crucial, enabling the establishment of appropriate treatment plans and markedly enhancing patient prognosis. While direct magnetic resonance imaging-guided biopsy demonstrates promising performance in detecting cancer lesions, its practical application is limited by prolonged procedure times and high costs. To overcome these issues, an indirect MRI-guided biopsy that allows the procedure to be performed outside of the MRI room has been proposed, but it still faces challenges in creating an accurate real-time deformable breast model. In our study, we tackled this issue by developing a graph neural network (GNN)-based model capable of accurately predicting deformed breast cancer sites in real time during biopsy procedures. An individual-specific finite element (FE) model was developed by incorporating magnetic resonance (MR) image-derived structural information of the breast and tumor to simulate deformation behaviors. A GNN model was then employed, designed to process surface displacement and distance-based graph data, enabling accurate prediction of overall tissue displacement, including the deformation of the tumor region. The model was validated using phantom and real patient datasets, achieving an accuracy within 0.2 millimeters (mm) for cancer node displacement (RMSE) and a dice similarity coefficient (DSC) of 0.977 for spatial overlap with actual cancerous regions. Additionally, the model enabled real-time inference and achieved a speed-up of over 4,000 times in computational cost compared to conventional FE simulations. The proposed deformation-aware GNN model offers a promising solution for real-time tumor displacement prediction in breast biopsy, with high accuracy and real-time capability. Its integration with clinical procedures could significantly enhance the precision and efficiency of breast cancer diagnosis.
Learning to Control Camera Exposure via Reinforcement Learning
Apr 02, 2024



Adjusting camera exposure in arbitrary lighting conditions is the first step to ensure the functionality of computer vision applications. Poorly adjusted camera exposure often leads to critical failure and performance degradation. Traditional camera exposure control methods require multiple convergence steps and time-consuming processes, making them unsuitable for dynamic lighting conditions. In this paper, we propose a new camera exposure control framework that rapidly controls camera exposure while performing real-time processing by exploiting deep reinforcement learning. The proposed framework consists of four contributions: 1) a simplified training ground to simulate real-world's diverse and dynamic lighting changes, 2) flickering and image attribute-aware reward design, along with lightweight state design for real-time processing, 3) a static-to-dynamic lighting curriculum to gradually improve the agent's exposure-adjusting capability, and 4) domain randomization techniques to alleviate the limitation of the training ground and achieve seamless generalization in the wild.As a result, our proposed method rapidly reaches a desired exposure level within five steps with real-time processing (1 ms). Also, the acquired images are well-exposed and show superiority in various computer vision tasks, such as feature extraction and object detection.
Complementary Random Masking for RGB-Thermal Semantic Segmentation
Mar 30, 2023



RGB-thermal semantic segmentation is one potential solution to achieve reliable semantic scene understanding in adverse weather and lighting conditions. However, the previous studies mostly focus on designing a multi-modal fusion module without consideration of the nature of multi-modality inputs. Therefore, the networks easily become over-reliant on a single modality, making it difficult to learn complementary and meaningful representations for each modality. This paper proposes 1) a complementary random masking strategy of RGB-T images and 2) self-distillation loss between clean and masked input modalities. The proposed masking strategy prevents over-reliance on a single modality. It also improves the accuracy and robustness of the neural network by forcing the network to segment and classify objects even when one modality is partially available. Also, the proposed self-distillation loss encourages the network to extract complementary and meaningful representations from a single modality or complementary masked modalities. Based on the proposed method, we achieve state-of-the-art performance over three RGB-T semantic segmentation benchmarks. Our source code is available at https://github.com/UkcheolShin/CRM_RGBTSeg.
DRL-ISP: Multi-Objective Camera ISP with Deep Reinforcement Learning
Jul 07, 2022



In this paper, we propose a multi-objective camera ISP framework that utilizes Deep Reinforcement Learning (DRL) and camera ISP toolbox that consist of network-based and conventional ISP tools. The proposed DRL-based camera ISP framework iteratively selects a proper tool from the toolbox and applies it to the image to maximize a given vision task-specific reward function. For this purpose, we implement total 51 ISP tools that include exposure correction, color-and-tone correction, white balance, sharpening, denoising, and the others. We also propose an efficient DRL network architecture that can extract the various aspects of an image and make a rigid mapping relationship between images and a large number of actions. Our proposed DRL-based ISP framework effectively improves the image quality according to each vision task such as RAW-to-RGB image restoration, 2D object detection, and monocular depth estimation.
Maximizing Self-supervision from Thermal Image for Effective Self-supervised Learning of Depth and Ego-motion
Jan 12, 2022


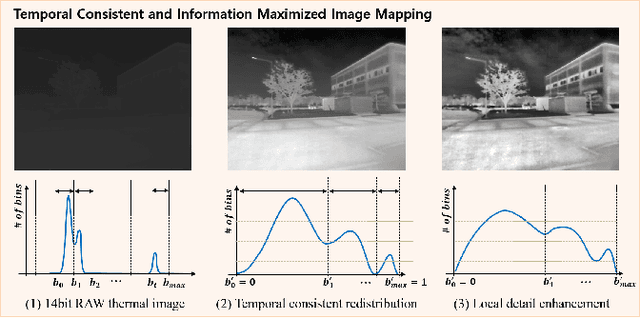
Recently, self-supervised learning of depth and ego-motion from thermal images shows strong robustness and reliability under challenging scenarios. However, the inherent thermal image properties such as weak contrast, blurry edges, and noise hinder to generate effective self-supervision from thermal images. Therefore, most research relies on additional self-supervision sources such as well-lit RGB images, generative models, and Lidar information. In this paper, we conduct an in-depth analysis of thermal image characteristics that degenerates self-supervision from thermal images. Based on the analysis, we propose an effective thermal image mapping method that significantly increases image information, such as overall structure, contrast, and details, while preserving temporal consistency. The proposed method shows outperformed depth and pose results than previous state-of-the-art networks without leveraging additional RGB guidance.
Depth Completion using Plane-Residual Representation
Apr 15, 2021

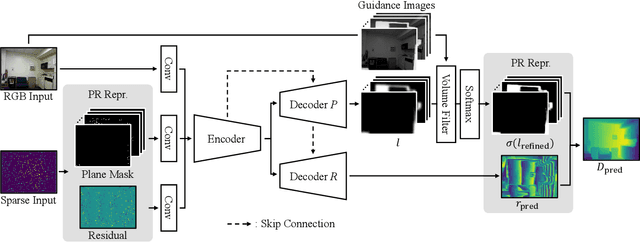

The basic framework of depth completion is to predict a pixel-wise dense depth map using very sparse input data. In this paper, we try to solve this problem in a more effective way, by reformulating the regression-based depth estimation problem into a combination of depth plane classification and residual regression. Our proposed approach is to initially densify sparse depth information by figuring out which plane a pixel should lie among a number of discretized depth planes, and then calculate the final depth value by predicting the distance from the specified plane. This will help the network to lessen the burden of directly regressing the absolute depth information from none, and to effectively obtain more accurate depth prediction result with less computation power and inference time. To do so, we firstly introduce a novel way of interpreting depth information with the closest depth plane label $p$ and a residual value $r$, as we call it, Plane-Residual (PR) representation. We also propose a depth completion network utilizing PR representation consisting of a shared encoder and two decoders, where one classifies the pixel's depth plane label, while the other one regresses the normalized distance from the classified depth plane. By interpreting depth information in PR representation and using our corresponding depth completion network, we were able to acquire improved depth completion performance with faster computation, compared to previous approaches.
Unsupervised Depth and Ego-motion Estimation for Monocular Thermal Video using Multi-spectral Consistency Loss
Mar 03, 2021
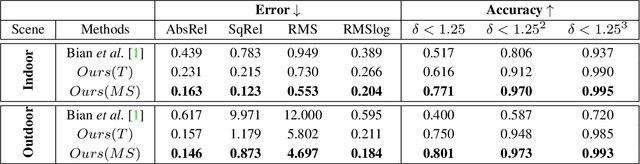

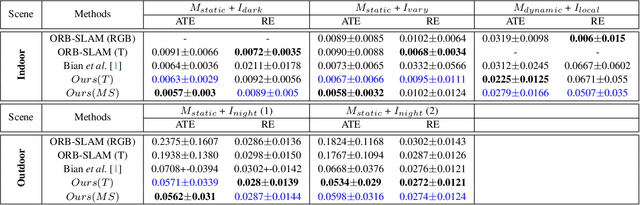
Most of the deep-learning based depth and ego-motion networks have been designed for visible cameras. However, visible cameras heavily rely on the presence of an external light source. Therefore, it is challenging to use them under low-light conditions such as night scenes, tunnels, and other harsh conditions. A thermal camera is one solution to compensate for this problem because it detects Long Wave Infrared Radiation(LWIR) regardless of any external light sources. However, despite this advantage, both depth and ego-motion estimation research for the thermal camera are not actively explored until so far. In this paper, we propose an unsupervised learning method for the all-day depth and ego-motion estimation. The proposed method exploits multi-spectral consistency loss to gives complementary supervision for the networks by reconstructing visible and thermal images with the depth and pose estimated from thermal images. The networks trained with the proposed method robustly estimate the depth and pose from monocular thermal video under low-light and even zero-light conditions. To the best of our knowledge, this is the first work to simultaneously estimate both depth and ego-motion from the monocular thermal video in an unsupervised manner.
An Efficient Asynchronous Method for Integrating Evolutionary and Gradient-based Policy Search
Jan 06, 2021

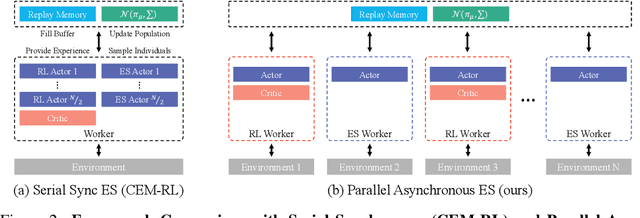

Deep reinforcement learning (DRL) algorithms and evolution strategies (ES) have been applied to various tasks, showing excellent performances. These have the opposite properties, with DRL having good sample efficiency and poor stability, while ES being vice versa. Recently, there have been attempts to combine these algorithms, but these methods fully rely on synchronous update scheme, making it not ideal to maximize the benefits of the parallelism in ES. To solve this challenge, asynchronous update scheme was introduced, which is capable of good time-efficiency and diverse policy exploration. In this paper, we introduce an Asynchronous Evolution Strategy-Reinforcement Learning (AES-RL) that maximizes the parallel efficiency of ES and integrates it with policy gradient methods. Specifically, we propose 1) a novel framework to merge ES and DRL asynchronously and 2) various asynchronous update methods that can take all advantages of asynchronism, ES, and DRL, which are exploration and time efficiency, stability, and sample efficiency, respectively. The proposed framework and update methods are evaluated in continuous control benchmark work, showing superior performance as well as time efficiency compared to the previous methods.