 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Move Your Dragon: Text-to-Motion Synthesis for Large-Vocabulary Objects
Mar 06, 2025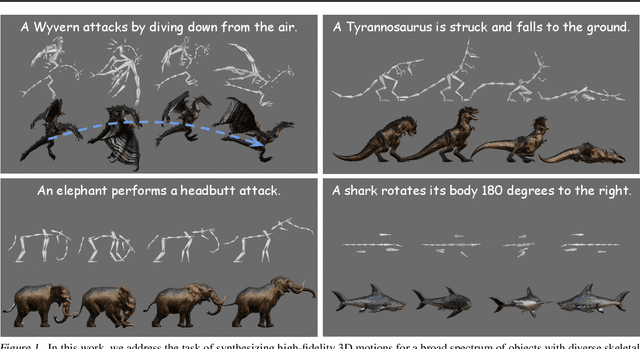

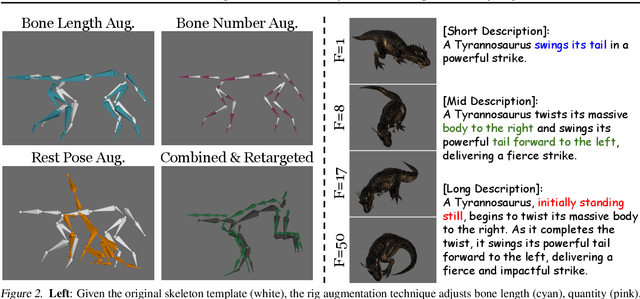
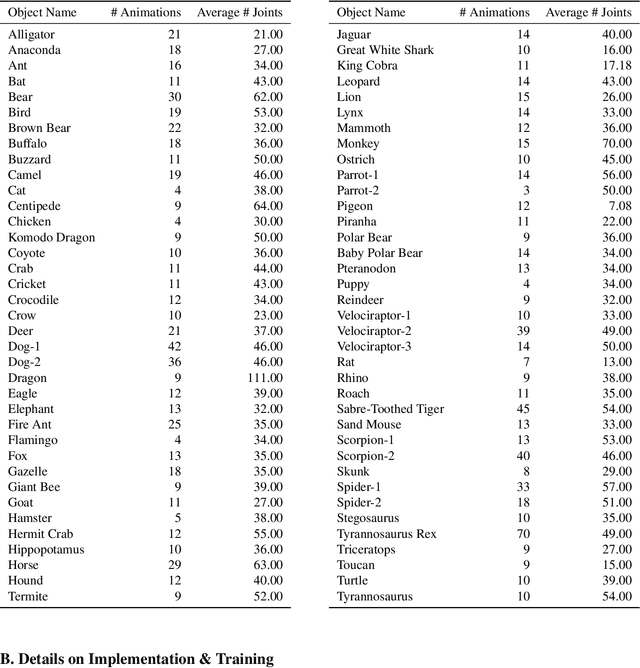
Motion synthesis for diverse object categories holds great potential for 3D content creation but remains underexplored due to two key challenges: (1) the lack of comprehensive motion datasets that include a wide range of high-quality motions and annotations, and (2) the absence of methods capable of handling heterogeneous skeletal templates from diverse objects. To address these challenges, we contribute the following: First, we augment the Truebones Zoo dataset, a high-quality animal motion dataset covering over 70 species, by annotating it with detailed text descriptions, making it suitable for text-based motion synthesis. Second, we introduce rig augmentation techniques that generate diverse motion data while preserving consistent dynamics, enabling models to adapt to various skeletal configurations. Finally, we redesign existing motion diffusion models to dynamically adapt to arbitrary skeletal templates, enabling motion synthesis for a diverse range of objects with varying structures. Experiments show that our method learns to generate high-fidelity motions from textual descriptions for diverse and even unseen objects, setting a strong foundation for motion synthesis across diverse object categories and skeletal templates. Qualitative results are available on this link: t2m4lvo.github.io
Efficient Generative Modeling with Residual Vector Quantization-Based Tokens
Dec 13, 2024We explore the use of Residual Vector Quantization (RVQ) for high-fidelity generation in vector-quantized generative models. This quantization technique maintains higher data fidelity by employing more in-depth tokens. However, increasing the token number in generative models leads to slower inference speeds. To this end, we introduce ResGen, an efficient RVQ-based discrete diffusion model that generates high-fidelity samples without compromising sampling speed. Our key idea is a direct prediction of vector embedding of collective tokens rather than individual ones. Moreover, we demonstrate that our proposed token masking and multi-token prediction method can be formulated within a principled probabilistic framework using a discrete diffusion process and variational inference. We validate the efficacy and generalizability of the proposed method on two challenging tasks across different modalities: conditional image generation} on ImageNet 256x256 and zero-shot text-to-speech synthesis. Experimental results demonstrate that ResGen outperforms autoregressive counterparts in both tasks, delivering superior performance without compromising sampling speed. Furthermore, as we scale the depth of RVQ, our generative models exhibit enhanced generation fidelity or faster sampling speeds compared to similarly sized baseline models. The project page can be found at https://resgen-genai.github.io
Rare-to-Frequent: Unlocking Compositional Generation Power of Diffusion Models on Rare Concepts with LLM Guidance
Oct 29, 2024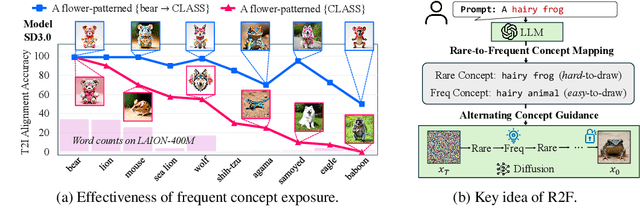
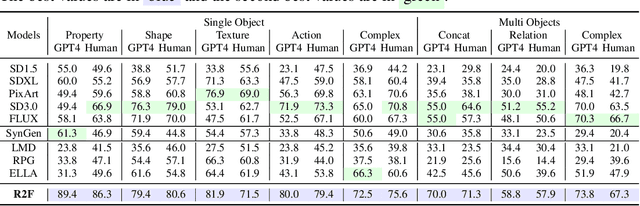
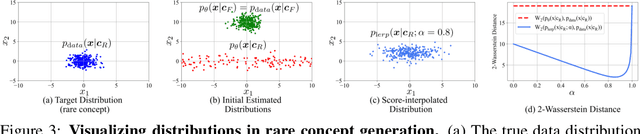
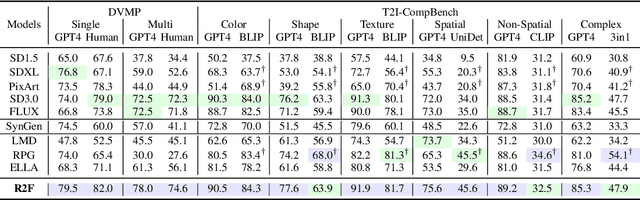
State-of-the-art text-to-image (T2I) diffusion models often struggle to generate rare compositions of concepts, e.g., objects with unusual attributes. In this paper, we show that the compositional generation power of diffusion models on such rare concepts can be significantly enhanced by the Large Language Model (LLM) guidance. We start with empirical and theoretical analysis, demonstrating that exposing frequent concepts relevant to the target rare concepts during the diffusion sampling process yields more accurate concept composition. Based on this, we propose a training-free approach, R2F, that plans and executes the overall rare-to-frequent concept guidance throughout the diffusion inference by leveraging the abundant semantic knowledge in LLMs. Our framework is flexible across any pre-trained diffusion models and LLMs, and can be seamlessly integrated with the region-guided diffusion approaches. Extensive experiments on three datasets, including our newly proposed benchmark, RareBench, containing various prompts with rare compositions of concepts, R2F significantly surpasses existing models including SD3.0 and FLUX by up to 28.1%p in T2I alignment. Code is available at https://github.com/krafton-ai/Rare2Frequent.
A Simple Early Exiting Framework for Accelerated Sampling in Diffusion Models
Aug 12, 2024Diffusion models have shown remarkable performance in generation problems over various domains including images, videos, text, and audio. A practical bottleneck of diffusion models is their sampling speed, due to the repeated evaluation of score estimation networks during the inference. In this work, we propose a novel framework capable of adaptively allocating compute required for the score estimation, thereby reducing the overall sampling time of diffusion models. We observe that the amount of computation required for the score estimation may vary along the time step for which the score is estimated. Based on this observation, we propose an early-exiting scheme, where we skip the subset of parameters in the score estimation network during the inference, based on a time-dependent exit schedule. Using the diffusion models for image synthesis, we show that our method could significantly improve the sampling throughput of the diffusion models without compromising image quality. Furthermore, we also demonstrate that our method seamlessly integrates with various types of solvers for faster sampling, capitalizing on their compatibility to enhance overall efficiency. The source code and our experiments are available at \url{https://github.com/taehong-moon/ee-diffusion}
HyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.