 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal Few-Shot Spatial Control for Diffusion Models
Sep 09, 2025



Spatial conditioning in pretrained text-to-image diffusion models has significantly improved fine-grained control over the structure of generated images. However, existing control adapters exhibit limited adaptability and incur high training costs when encountering novel spatial control conditions that differ substantially from the training tasks. To address this limitation, we propose Universal Few-Shot Control (UFC), a versatile few-shot control adapter capable of generalizing to novel spatial conditions. Given a few image-condition pairs of an unseen task and a query condition, UFC leverages the analogy between query and support conditions to construct task-specific control features, instantiated by a matching mechanism and an update on a small set of task-specific parameters. Experiments on six novel spatial control tasks show that UFC, fine-tuned with only 30 annotated examples of novel tasks, achieves fine-grained control consistent with the spatial conditions. Notably, when fine-tuned with 0.1% of the full training data, UFC achieves competitive performance with the fully supervised baselines in various control tasks. We also show that UFC is applicable agnostically to various diffusion backbones and demonstrate its effectiveness on both UNet and DiT architectures. Code is available at https://github.com/kietngt00/UFC.
HyperFlow: Gradient-Free Emulation of Few-Shot Fine-Tuning
Apr 21, 2025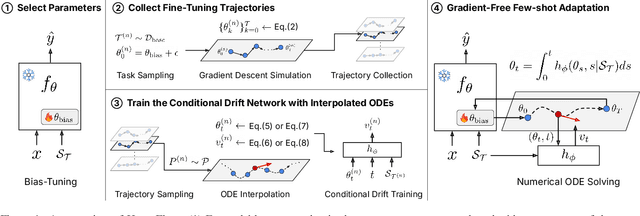



While test-time fine-tuning is beneficial in few-shot learning, the need for multiple backpropagation steps can be prohibitively expensive in real-time or low-resource scenarios. To address this limitation, we propose an approach that emulates gradient descent without computing gradients, enabling efficient test-time adaptation. Specifically, we formulate gradient descent as an Euler discretization of an ordinary differential equation (ODE) and train an auxiliary network to predict the task-conditional drift using only the few-shot support set. The adaptation then reduces to a simple numerical integration (e.g., via the Euler method), which requires only a few forward passes of the auxiliary network -- no gradients or forward passes of the target model are needed. In experiments on cross-domain few-shot classification using the Meta-Dataset and CDFSL benchmarks, our method significantly improves out-of-domain performance over the non-fine-tuned baseline while incurring only 6\% of the memory cost and 0.02\% of the computation time of standard fine-tuning, thus establishing a practical middle ground between direct transfer and fully fine-tuned approaches.
AdaRank: Adaptive Rank Pruning for Enhanced Model Merging
Mar 28, 2025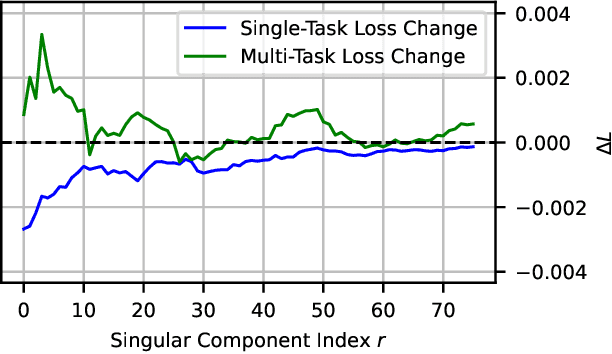
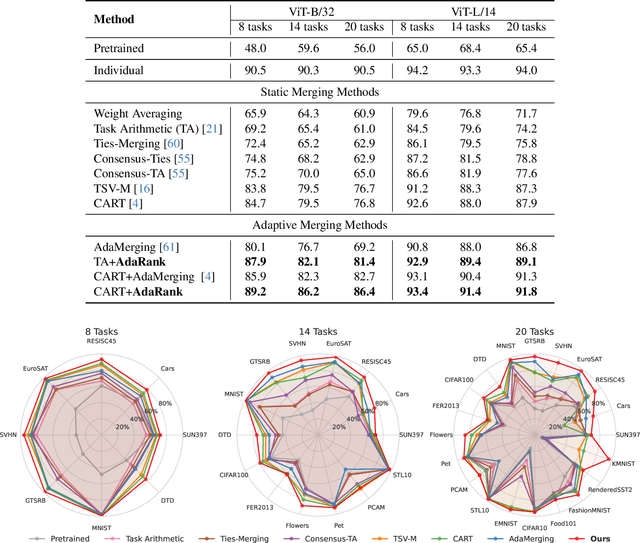
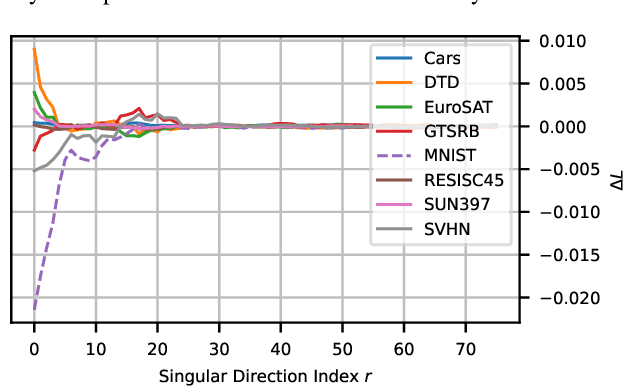
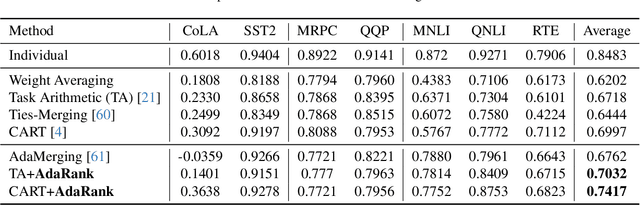
Model merging has emerged as a promising approach for unifying independently fine-tuned models into an integrated framework, significantly enhancing computational efficiency in multi-task learning. Recently, several SVD-based techniques have been introduced to exploit low-rank structures for enhanced merging, but their reliance on such manually designed rank selection often leads to cross-task interference and suboptimal performance. In this paper, we propose AdaRank, a novel model merging framework that adaptively selects the most beneficial singular directions of task vectors to merge multiple models. We empirically show that the dominant singular components of task vectors can cause critical interference with other tasks, and that naive truncation across tasks and layers degrades performance. In contrast, AdaRank dynamically prunes the singular components that cause interference and offers an optimal amount of information to each task vector by learning to prune ranks during test-time via entropy minimization. Our analysis demonstrates that such method mitigates detrimental overlaps among tasks, while empirical results show that AdaRank consistently achieves state-of-the-art performance with various backbones and number of tasks, reducing the performance gap between fine-tuned models to nearly 1%.
Revisiting Weight Averaging for Model Merging
Dec 11, 2024Model merging aims to build a multi-task learner by combining the parameters of individually fine-tuned models without additional training. While a straightforward approach is to average model parameters across tasks, this often results in suboptimal performance due to interference among parameters across tasks. In this paper, we present intriguing results that weight averaging implicitly induces task vectors centered around the weight averaging itself and that applying a low-rank approximation to these centered task vectors significantly improves merging performance. Our analysis shows that centering the task vectors effectively separates core task-specific knowledge and nuisance noise within the fine-tuned parameters into the top and lower singular vectors, respectively, allowing us to reduce inter-task interference through its low-rank approximation. We evaluate our method on eight image classification tasks, demonstrating that it outperforms prior methods by a significant margin, narrowing the performance gap with traditional multi-task learning to within 1-3%
Meta-Controller: Few-Shot Imitation of Unseen Embodiments and Tasks in Continuous Control
Dec 10, 2024



Generalizing across robot embodiments and tasks is crucial for adaptive robotic systems. Modular policy learning approaches adapt to new embodiments but are limited to specific tasks, while few-shot imitation learning (IL) approaches often focus on a single embodiment. In this paper, we introduce a few-shot behavior cloning framework to simultaneously generalize to unseen embodiments and tasks using a few (\emph{e.g.,} five) reward-free demonstrations. Our framework leverages a joint-level input-output representation to unify the state and action spaces of heterogeneous embodiments and employs a novel structure-motion state encoder that is parameterized to capture both shared knowledge across all embodiments and embodiment-specific knowledge. A matching-based policy network then predicts actions from a few demonstrations, producing an adaptive policy that is robust to over-fitting. Evaluated in the DeepMind Control suite, our framework termed \modelname{} demonstrates superior few-shot generalization to unseen embodiments and tasks over modular policy learning and few-shot IL approaches. Codes are available at \href{https://github.com/SeongwoongCho/meta-controller}{https://github.com/SeongwoongCho/meta-controller}.
Chameleon: A Data-Efficient Generalist for Dense Visual Prediction in the Wild
Apr 29, 2024



Large language models have evolved data-efficient generalists, benefiting from the universal language interface and large-scale pre-training. However, constructing a data-efficient generalist for dense visual prediction presents a distinct challenge due to the variation in label structures across different tasks. Consequently, generalization to unseen dense prediction tasks in the low-data regime is not straightforward and has received less attention from previous vision generalists. In this study, we explore a universal model that can flexibly adapt to unseen dense label structures with a few examples, enabling it to serve as a data-efficient vision generalist in diverse real-world scenarios. To this end, we base our method on a powerful meta-learning framework and explore several axes to improve its performance and versatility for real-world problems, such as flexible adaptation mechanisms and scalability. We evaluate our model across a spectrum of unseen real-world scenarios where low-shot learning is desirable, including video, 3D, medical, biological, and user-interactive tasks. Equipped with a generic architecture and an effective adaptation mechanism, our model flexibly adapts to all of these tasks with at most 50 labeled images, showcasing a significant advancement over existing data-efficient generalist approaches. Codes are available at https://github.com/GitGyun/chameleon.
Universal Few-shot Learning of Dense Prediction Tasks with Visual Token Matching
Mar 27, 2023



Dense prediction tasks are a fundamental class of problems in computer vision. As supervised methods suffer from high pixel-wise labeling cost, a few-shot learning solution that can learn any dense task from a few labeled images is desired. Yet, current few-shot learning methods target a restricted set of tasks such as semantic segmentation, presumably due to challenges in designing a general and unified model that is able to flexibly and efficiently adapt to arbitrary tasks of unseen semantics. We propose Visual Token Matching (VTM), a universal few-shot learner for arbitrary dense prediction tasks. It employs non-parametric matching on patch-level embedded tokens of images and labels that encapsulates all tasks. Also, VTM flexibly adapts to any task with a tiny amount of task-specific parameters that modulate the matching algorithm. We implement VTM as a powerful hierarchical encoder-decoder architecture involving ViT backbones where token matching is performed at multiple feature hierarchies. We experiment VTM on a challenging variant of Taskonomy dataset and observe that it robustly few-shot learns various unseen dense prediction tasks. Surprisingly, it is competitive with fully supervised baselines using only 10 labeled examples of novel tasks (0.004% of full supervision) and sometimes outperforms using 0.1% of full supervision. Codes are available at https://github.com/GitGyun/visual_token_matching.
Multi-Task Processes
Oct 29, 2021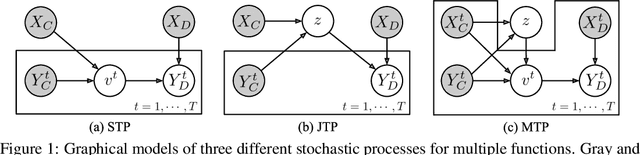
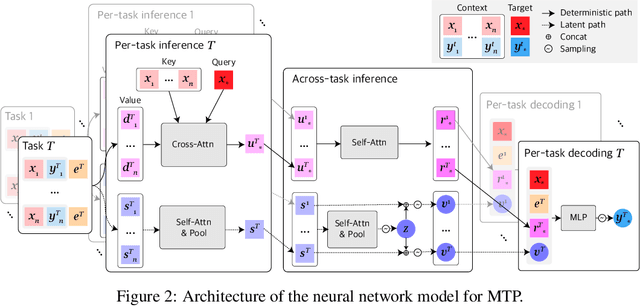
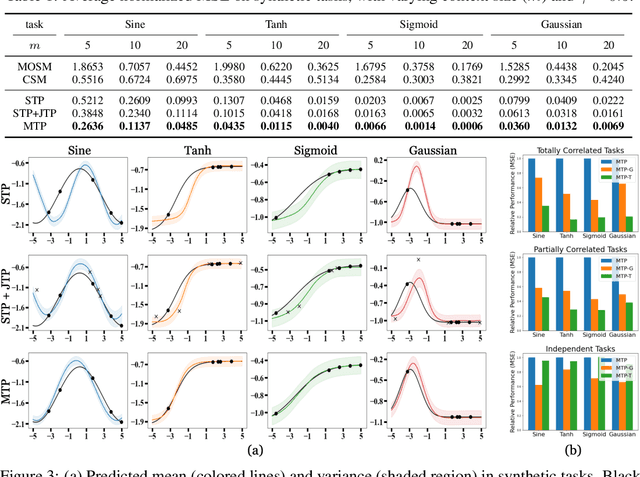
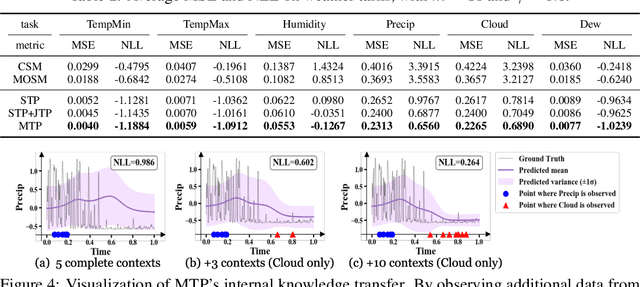
Neural Processes (NPs) consider a task as a function realized from a stochastic process and flexibly adapt to unseen tasks through inference on functions. However, naive NPs can model data from only a single stochastic process and are designed to infer each task independently. Since many real-world data represent a set of correlated tasks from multiple sources (e.g., multiple attributes and multi-sensor data), it is beneficial to infer them jointly and exploit the underlying correlation to improve the predictive performance. To this end, we propose Multi-Task Processes (MTPs), an extension of NPs designed to jointly infer tasks realized from multiple stochastic processes. We build our MTPs in a hierarchical manner such that inter-task correlation is considered by conditioning all per-task latent variables on a single global latent variable. In addition, we further design our MTPs so that they can address multi-task settings with incomplete data (i.e., not all tasks share the same set of input points), which has high practical demands in various applications. Experiments demonstrate that MTPs can successfully model multiple tasks jointly by discovering and exploiting their correlations in various real-world data such as time series of weather attributes and pixel-aligned visual modalities.
High-Fidelity Synthesis with Disentangled Representation
Jan 13, 2020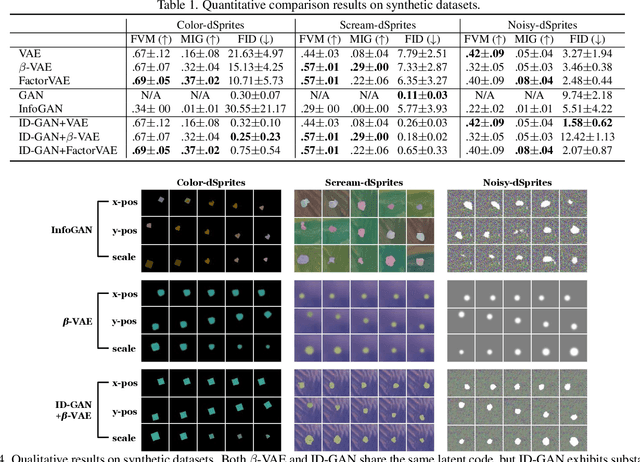
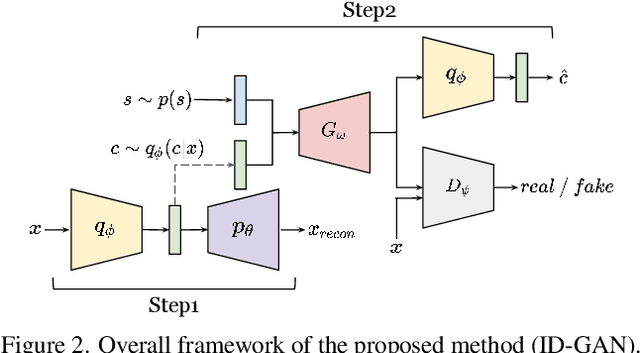
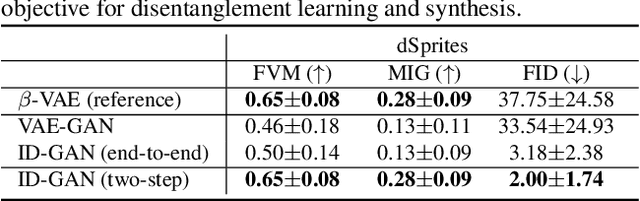
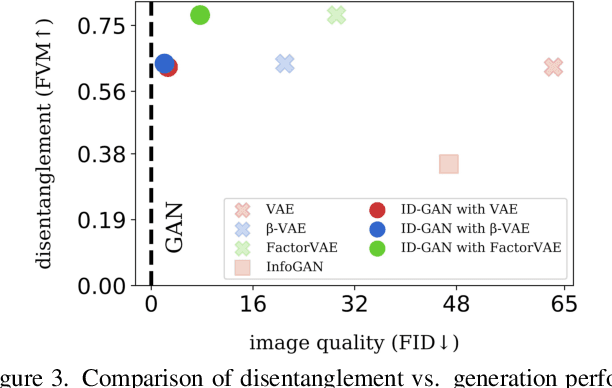
Learning disentangled representation of data without supervision is an important step towards improving the interpretability of generative models. Despite recent advances in disentangled representation learning, existing approaches often suffer from the trade-off between representation learning and generation performance i.e. improving generation quality sacrifices disentanglement performance). We propose an Information-Distillation Generative Adversarial Network (ID-GAN), a simple yet generic framework that easily incorporates the existing state-of-the-art models for both disentanglement learning and high-fidelity synthesis. Our method learns disentangled representation using VAE-based models, and distills the learned representation with an additional nuisance variable to the separate GAN-based generator for high-fidelity synthesis. To ensure that both generative models are aligned to render the same generative factors, we further constrain the GAN generator to maximize the mutual information between the learned latent code and the output. Despite the simplicity, we show that the proposed method is highly effective, achieving comparable image generation quality to the state-of-the-art methods using the disentangled representation. We also show that the proposed decomposition leads to an efficient and stable model design, and we demonstrate photo-realistic high-resolution image synthesis results (1024x1024 pixels) for the first time using the disentangled representations.