 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaRank: Adaptive Rank Pruning for Enhanced Model Merging
Mar 28, 2025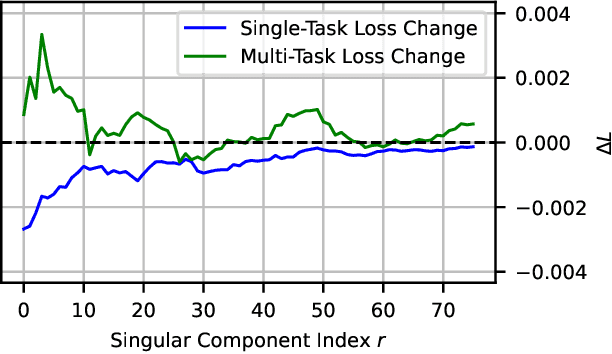
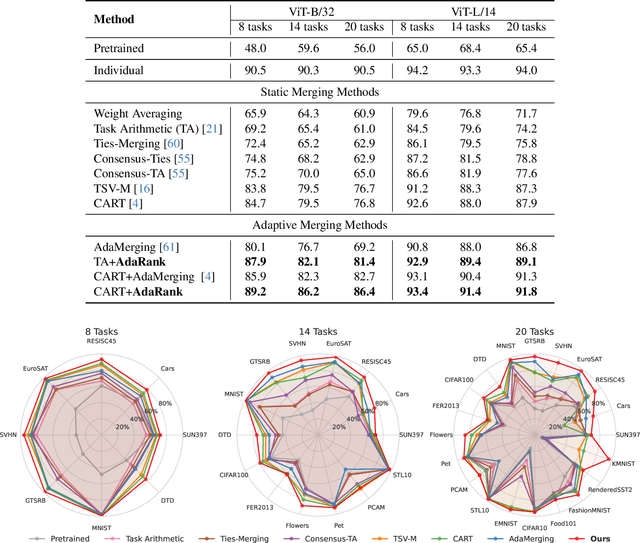
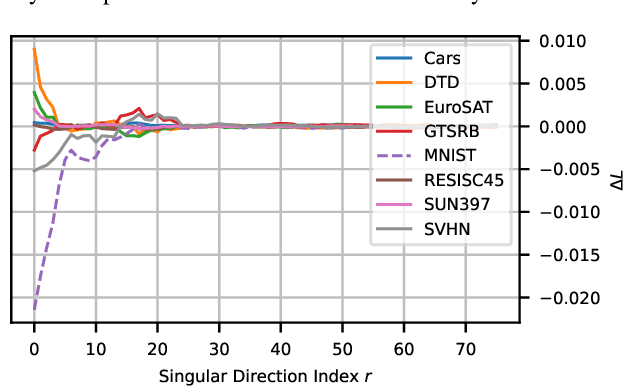
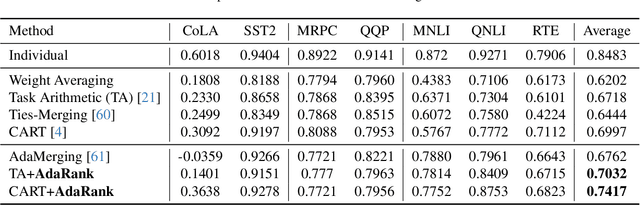
Model merging has emerged as a promising approach for unifying independently fine-tuned models into an integrated framework, significantly enhancing computational efficiency in multi-task learning. Recently, several SVD-based techniques have been introduced to exploit low-rank structures for enhanced merging, but their reliance on such manually designed rank selection often leads to cross-task interference and suboptimal performance. In this paper, we propose AdaRank, a novel model merging framework that adaptively selects the most beneficial singular directions of task vectors to merge multiple models. We empirically show that the dominant singular components of task vectors can cause critical interference with other tasks, and that naive truncation across tasks and layers degrades performance. In contrast, AdaRank dynamically prunes the singular components that cause interference and offers an optimal amount of information to each task vector by learning to prune ranks during test-time via entropy minimization. Our analysis demonstrates that such method mitigates detrimental overlaps among tasks, while empirical results show that AdaRank consistently achieves state-of-the-art performance with various backbones and number of tasks, reducing the performance gap between fine-tuned models to nearly 1%.
Revisiting Weight Averaging for Model Merging
Dec 11, 2024Model merging aims to build a multi-task learner by combining the parameters of individually fine-tuned models without additional training. While a straightforward approach is to average model parameters across tasks, this often results in suboptimal performance due to interference among parameters across tasks. In this paper, we present intriguing results that weight averaging implicitly induces task vectors centered around the weight averaging itself and that applying a low-rank approximation to these centered task vectors significantly improves merging performance. Our analysis shows that centering the task vectors effectively separates core task-specific knowledge and nuisance noise within the fine-tuned parameters into the top and lower singular vectors, respectively, allowing us to reduce inter-task interference through its low-rank approximation. We evaluate our method on eight image classification tasks, demonstrating that it outperforms prior methods by a significant margin, narrowing the performance gap with traditional multi-task learning to within 1-3%