 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Fidelity Synthesis with Disentangled Representation
Paper and Code
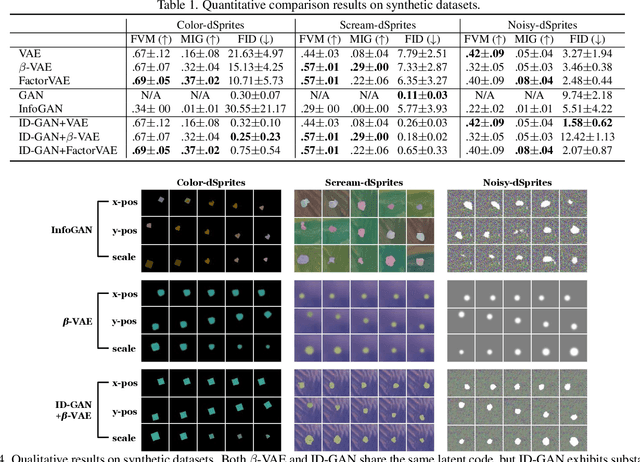
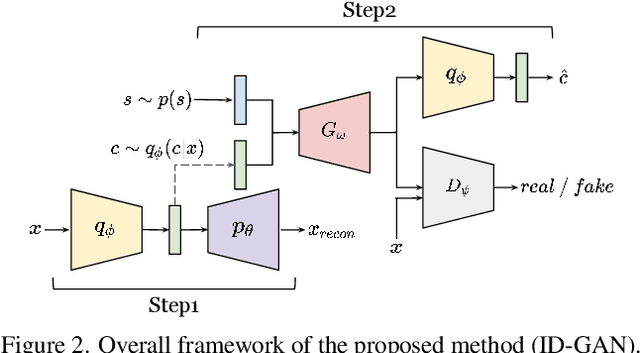
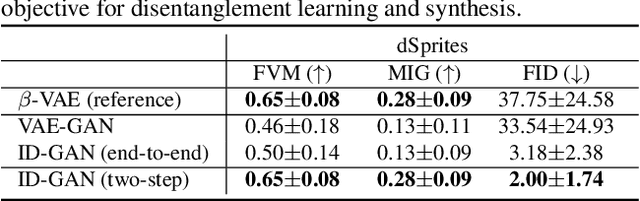
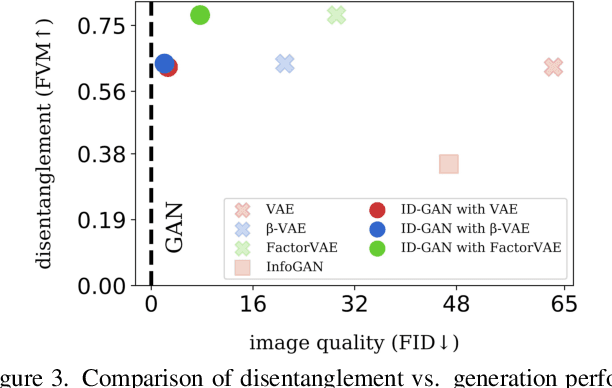
Learning disentangled representation of data without supervision is an important step towards improving the interpretability of generative models. Despite recent advances in disentangled representation learning, existing approaches often suffer from the trade-off between representation learning and generation performance i.e. improving generation quality sacrifices disentanglement performance). We propose an Information-Distillation Generative Adversarial Network (ID-GAN), a simple yet generic framework that easily incorporates the existing state-of-the-art models for both disentanglement learning and high-fidelity synthesis. Our method learns disentangled representation using VAE-based models, and distills the learned representation with an additional nuisance variable to the separate GAN-based generator for high-fidelity synthesis. To ensure that both generative models are aligned to render the same generative factors, we further constrain the GAN generator to maximize the mutual information between the learned latent code and the output. Despite the simplicity, we show that the proposed method is highly effective, achieving comparable image generation quality to the state-of-the-art methods using the disentangled representation. We also show that the proposed decomposition leads to an efficient and stable model design, and we demonstrate photo-realistic high-resolution image synthesis results (1024x1024 pixels) for the first time using the disentangled representations.