 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeTraceAct: Visibility-Aware Latent Planning from Cross-Embodiment Demonstration Videos
Jun 01, 2026Vision-language-action models (VLAs) are promising general-purpose robot policies, but adapting them to new tasks typically requires costly task-specific teleoperation data. As an alternative, we study one-shot demo-conditioned VLAs, where a robot policy is conditioned on a single demonstration video of an unseen task. We find that existing end-to-end approaches often struggle when successful execution requires precisely localizing small target regions. To address this limitation, we propose SeeTraceAct, a demo-conditioned VLA framework that encourages precise spatial grounding through visibility-aware prediction of future end-effector traces. To enable reproducible evaluation with cross-embodiment demonstrations, we introduce and release RoboCasa-DC, a demo-conditioned extension of RoboCasa with episode-paired humanoid videos. Experiments on RoboCasa-DC and a real-world benchmark, where a Franka Panda arm is conditioned on human demonstrations, show that SeeTraceAct outperforms baselines, achieving the best success rate across all four RoboCasa-DC settings and improving real-world average success by 12.5 percentage points.
Distilling Reinforcement Learning Algorithms for In-Context Model-Based Planning
Feb 26, 2025Recent studies have shown that Transformers can perform in-context reinforcement learning (RL) by imitating existing RL algorithms, enabling sample-efficient adaptation to unseen tasks without parameter updates. However, these models also inherit the suboptimal behaviors of the RL algorithms they imitate. This issue primarily arises due to the gradual update rule employed by those algorithms. Model-based planning offers a promising solution to this limitation by allowing the models to simulate potential outcomes before taking action, providing an additional mechanism to deviate from the suboptimal behavior. Rather than learning a separate dynamics model, we propose Distillation for In-Context Planning (DICP), an in-context model-based RL framework where Transformers simultaneously learn environment dynamics and improve policy in-context. We evaluate DICP across a range of discrete and continuous environments, including Darkroom variants and Meta-World. Our results show that DICP achieves state-of-the-art performance while requiring significantly fewer environment interactions than baselines, which include both model-free counterparts and existing meta-RL methods.
Learning to Continually Learn with the Bayesian Principle
May 29, 2024In the present era of deep learning, continual learning research is mainly focused on mitigating forgetting when training a neural network with stochastic gradient descent on a non-stationary stream of data. On the other hand, in the more classical literature of statistical machine learning, many models have sequential Bayesian update rules that yield the same learning outcome as the batch training, i.e., they are completely immune to catastrophic forgetting. However, they are often overly simple to model complex real-world data. In this work, we adopt the meta-learning paradigm to combine the strong representational power of neural networks and simple statistical models' robustness to forgetting. In our novel meta-continual learning framework, continual learning takes place only in statistical models via ideal sequential Bayesian update rules, while neural networks are meta-learned to bridge the raw data and the statistical models. Since the neural networks remain fixed during continual learning, they are protected from catastrophic forgetting. This approach not only achieves significantly improved performance but also exhibits excellent scalability. Since our approach is domain-agnostic and model-agnostic, it can be applied to a wide range of problems and easily integrated with existing model architectures.
When Meta-Learning Meets Online and Continual Learning: A Survey
Nov 09, 2023
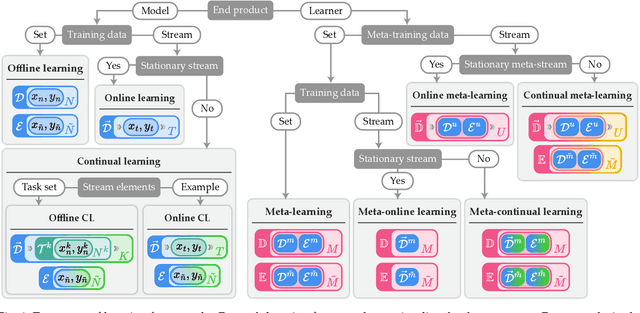
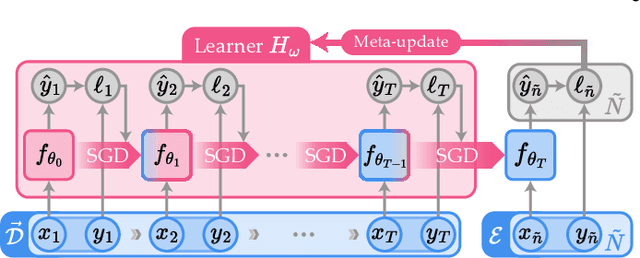

Over the past decade, deep neural networks have demonstrated significant success using the training scheme that involves mini-batch stochastic gradient descent on extensive datasets. Expanding upon this accomplishment, there has been a surge in research exploring the application of neural networks in other learning scenarios. One notable framework that has garnered significant attention is meta-learning. Often described as "learning to learn," meta-learning is a data-driven approach to optimize the learning algorithm. Other branches of interest are continual learning and online learning, both of which involve incrementally updating a model with streaming data. While these frameworks were initially developed independently, recent works have started investigating their combinations, proposing novel problem settings and learning algorithms. However, due to the elevated complexity and lack of unified terminology, discerning differences between the learning frameworks can be challenging even for experienced researchers. To facilitate a clear understanding, this paper provides a comprehensive survey that organizes various problem settings using consistent terminology and formal descriptions. By offering an overview of these learning paradigms, our work aims to foster further advancements in this promising area of research.
Recasting Continual Learning as Sequence Modeling
Oct 18, 2023



In this work, we aim to establish a strong connection between two significant bodies of machine learning research: continual learning and sequence modeling. That is, we propose to formulate continual learning as a sequence modeling problem, allowing advanced sequence models to be utilized for continual learning. Under this formulation, the continual learning process becomes the forward pass of a sequence model. By adopting the meta-continual learning (MCL) framework, we can train the sequence model at the meta-level, on multiple continual learning episodes. As a specific example of our new formulation, we demonstrate the application of Transformers and their efficient variants as MCL methods. Our experiments on seven benchmarks, covering both classification and regression, show that sequence models can be an attractive solution for general MCL.