 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSee It All: Contextualized Late Aggregation for 3D Dense Captioning
Paper and Code
Aug 14, 2024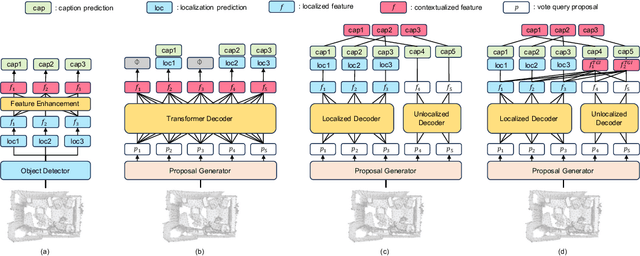
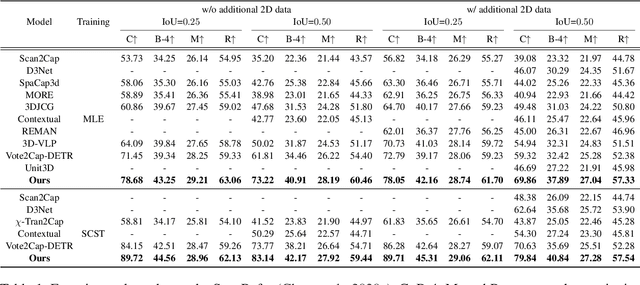
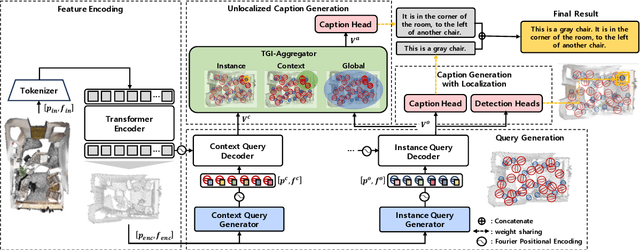
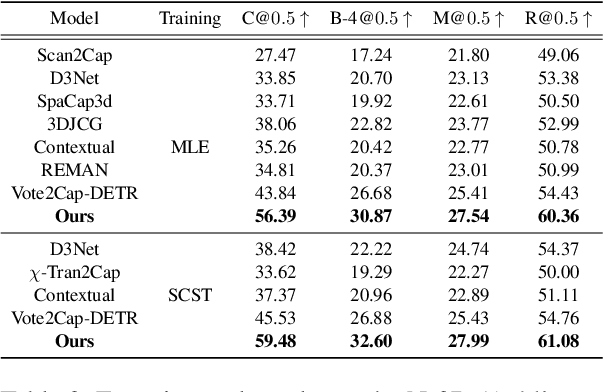
3D dense captioning is a task to localize objects in a 3D scene and generate descriptive sentences for each object. Recent approaches in 3D dense captioning have adopted transformer encoder-decoder frameworks from object detection to build an end-to-end pipeline without hand-crafted components. However, these approaches struggle with contradicting objectives where a single query attention has to simultaneously view both the tightly localized object regions and contextual environment. To overcome this challenge, we introduce SIA (See-It-All), a transformer pipeline that engages in 3D dense captioning with a novel paradigm called late aggregation. SIA simultaneously decodes two sets of queries-context query and instance query. The instance query focuses on localization and object attribute descriptions, while the context query versatilely captures the region-of-interest of relationships between multiple objects or with the global scene, then aggregated afterwards (i.e., late aggregation) via simple distance-based measures. To further enhance the quality of contextualized caption generation, we design a novel aggregator to generate a fully informed caption based on the surrounding context, the global environment, and object instances. Extensive experiments on two of the most widely-used 3D dense captioning datasets demonstrate that our proposed method achieves a significant improvement over prior methods.