 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-dimensional Preference Alignment by Conditioning Reward Itself
Dec 11, 2025Reinforcement Learning from Human Feedback has emerged as a standard for aligning diffusion models. However, we identify a fundamental limitation in the standard DPO formulation because it relies on the Bradley-Terry model to aggregate diverse evaluation axes like aesthetic quality and semantic alignment into a single scalar reward. This aggregation creates a reward conflict where the model is forced to unlearn desirable features of a specific dimension if they appear in a globally non-preferred sample. To address this issue, we propose Multi Reward Conditional DPO (MCDPO). This method resolves reward conflicts by introducing a disentangled Bradley-Terry objective. MCDPO explicitly injects a preference outcome vector as a condition during training, which allows the model to learn the correct optimization direction for each reward axis independently within a single network. We further introduce dimensional reward dropout to ensure balanced optimization across dimensions. Extensive experiments on Stable Diffusion 1.5 and SDXL demonstrate that MCDPO achieves superior performance on benchmarks. Notably, our conditional framework enables dynamic and multiple-axis control at inference time using Classifier Free Guidance to amplify specific reward dimensions without additional training or external reward models.
DeepVideo-R1: Video Reinforcement Fine-Tuning via Difficulty-aware Regressive GRPO
Jun 09, 2025Recent works have demonstrated the effectiveness of reinforcement learning (RL)-based post-training in enhancing the reasoning capabilities of large language models (LLMs). In particular, Group Relative Policy Optimization (GRPO) has shown impressive success by employing a PPO-style reinforcement algorithm with group-based normalized rewards. However, the application of GRPO to Video Large Language Models (Video LLMs) has been less studied. In this paper, we explore GRPO for video LLMs and identify two primary issues that impede its effective learning: (1) reliance on safeguards, and (2) the vanishing advantage problem. To mitigate these challenges, we propose DeepVideo-R1, a video large language model trained with our proposed Reg-GRPO (Regressive GRPO) and difficulty-aware data augmentation strategy. Reg-GRPO reformulates the GRPO objective as a regression task, directly predicting the advantage in GRPO. This design eliminates the need for safeguards like clipping and min functions, thereby facilitating more direct policy guidance by aligning the model with the advantage values. We also design the difficulty-aware data augmentation strategy that dynamically augments training samples at solvable difficulty levels, fostering diverse and informative reward signals. Our comprehensive experiments show that DeepVideo-R1 significantly improves video reasoning performance across multiple video reasoning benchmarks.
DynamicER: Resolving Emerging Mentions to Dynamic Entities for RAG
Oct 15, 2024In the rapidly evolving landscape of language, resolving new linguistic expressions in continuously updating knowledge bases remains a formidable challenge. This challenge becomes critical in retrieval-augmented generation (RAG) with knowledge bases, as emerging expressions hinder the retrieval of relevant documents, leading to generator hallucinations. To address this issue, we introduce a novel task aimed at resolving emerging mentions to dynamic entities and present DynamicER benchmark. Our benchmark includes dynamic entity mention resolution and entity-centric knowledge-intensive QA task, evaluating entity linking and RAG model's adaptability to new expressions, respectively. We discovered that current entity linking models struggle to link these new expressions to entities. Therefore, we propose a temporal segmented clustering method with continual adaptation, effectively managing the temporal dynamics of evolving entities and emerging mentions. Extensive experiments demonstrate that our method outperforms existing baselines, enhancing RAG model performance on QA task with resolved mentions.
TEOChat: A Large Vision-Language Assistant for Temporal Earth Observation Data
Oct 08, 2024Large vision and language assistants have enabled new capabilities for interpreting natural images. These approaches have recently been adapted to earth observation data, but they are only able to handle single image inputs, limiting their use for many real-world tasks. In this work, we develop a new vision and language assistant called TEOChat that can engage in conversations about temporal sequences of earth observation data. To train TEOChat, we curate an instruction-following dataset composed of many single image and temporal tasks including building change and damage assessment, semantic change detection, and temporal scene classification. We show that TEOChat can perform a wide variety of spatial and temporal reasoning tasks, substantially outperforming previous vision and language assistants, and even achieving comparable or better performance than specialist models trained to perform these specific tasks. Furthermore, TEOChat achieves impressive zero-shot performance on a change detection and change question answering dataset, outperforms GPT-4o and Gemini 1.5 Pro on multiple temporal tasks, and exhibits stronger single image capabilities than a comparable single EO image instruction-following model. We publicly release our data, models, and code at https://github.com/ermongroup/TEOChat .
Joint-Embedding Predictive Architecture for Self-Supervised Learning of Mask Classification Architecture
Jul 15, 2024



In this work, we introduce Mask-JEPA, a self-supervised learning framework tailored for mask classification architectures (MCA), to overcome the traditional constraints associated with training segmentation models. Mask-JEPA combines a Joint Embedding Predictive Architecture with MCA to adeptly capture intricate semantics and precise object boundaries. Our approach addresses two critical challenges in self-supervised learning: 1) extracting comprehensive representations for universal image segmentation from a pixel decoder, and 2) effectively training the transformer decoder. The use of the transformer decoder as a predictor within the JEPA framework allows proficient training in universal image segmentation tasks. Through rigorous evaluations on datasets such as ADE20K, Cityscapes and COCO, Mask-JEPA demonstrates not only competitive results but also exceptional adaptability and robustness across various training scenarios. The architecture-agnostic nature of Mask-JEPA further underscores its versatility, allowing seamless adaptation to various mask classification family.
GrowOVER: How Can LLMs Adapt to Growing Real-World Knowledge?
Jun 09, 2024In the real world, knowledge is constantly evolving, which can render existing knowledge-based datasets outdated. This unreliability highlights the critical need for continuous updates to ensure both accuracy and relevance in knowledge-intensive tasks. To address this, we propose GrowOVER-QA and GrowOVER-Dialogue, dynamic open-domain QA and dialogue benchmarks that undergo a continuous cycle of updates, keeping pace with the rapid evolution of knowledge. Our research indicates that retrieval-augmented language models (RaLMs) struggle with knowledge that has not been trained on or recently updated. Consequently, we introduce a novel retrieval-interactive language model framework, where the language model evaluates and reflects on its answers for further re-retrieval. Our exhaustive experiments demonstrate that our training-free framework significantly improves upon existing methods, performing comparably to or even surpassing continuously trained language models.
Groupwise Query Specialization and Quality-Aware Multi-Assignment for Transformer-based Visual Relationship Detection
Mar 26, 2024Visual Relationship Detection (VRD) has seen significant advancements with Transformer-based architectures recently. However, we identify two key limitations in a conventional label assignment for training Transformer-based VRD models, which is a process of mapping a ground-truth (GT) to a prediction. Under the conventional assignment, an unspecialized query is trained since a query is expected to detect every relation, which makes it difficult for a query to specialize in specific relations. Furthermore, a query is also insufficiently trained since a GT is assigned only to a single prediction, therefore near-correct or even correct predictions are suppressed by being assigned no relation as a GT. To address these issues, we propose Groupwise Query Specialization and Quality-Aware Multi-Assignment (SpeaQ). Groupwise Query Specialization trains a specialized query by dividing queries and relations into disjoint groups and directing a query in a specific query group solely toward relations in the corresponding relation group. Quality-Aware Multi-Assignment further facilitates the training by assigning a GT to multiple predictions that are significantly close to a GT in terms of a subject, an object, and the relation in between. Experimental results and analyses show that SpeaQ effectively trains specialized queries, which better utilize the capacity of a model, resulting in consistent performance gains with zero additional inference cost across multiple VRD models and benchmarks. Code is available at https://github.com/mlvlab/SpeaQ.
CNA-TTA: Clean and Noisy Region Aware Feature Learning within Clusters for Online-Offline Test-Time Adaptation
Jan 26, 2024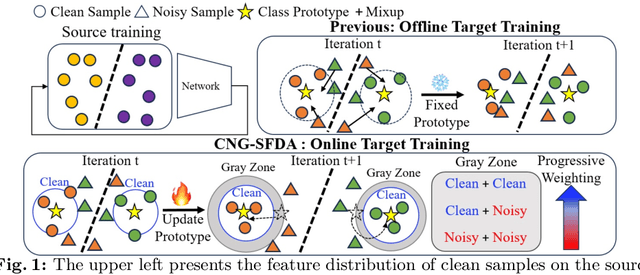

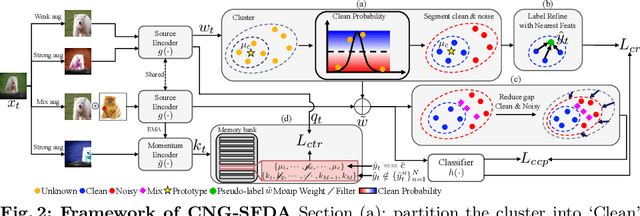
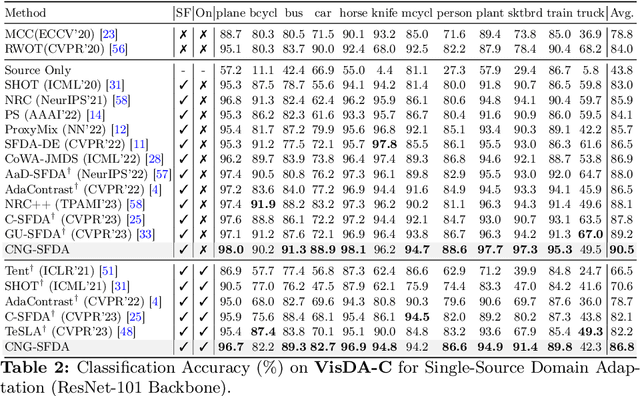
A domain shift occurs when training (source) and test (target) data diverge in their distribution. Test-time adaptation (TTA) addresses the domain shift problem, aiming to adopt a trained model on the source domain to the target domain in a scenario where only a well-trained source model and unlabeled target data are available. In this scenario, handling false labels in the target domain is crucial because they negatively impact the model performance. To deal with this problem, we propose to utilize cluster structure (i.e., {`Clean'} and {`Noisy'} regions within each cluster) in the target domain formulated by the source model. Given an initial clustering of target samples, we first partition clusters into {`Clean'} and {`Noisy'} regions defined based on cluster prototype (i.e., centroid of each cluster). As these regions have totally different distributions of the true pseudo-labels, we adopt distinct training strategies for the clean and noisy regions: we selectively train the target with clean pseudo-labels in the clean region, whereas we introduce mixup inputs representing intermediate features between clean and noisy regions to increase the compactness of the cluster. We conducted extensive experiments on multiple datasets in online/offline TTA settings, whose results demonstrate that our method, {CNA-TTA}, achieves state-of-the-art for most cases.
Deep Cerebellar Nuclei Segmentation via Semi-Supervised Deep Context-Aware Learning from 7T Diffusion MRI
May 12, 2020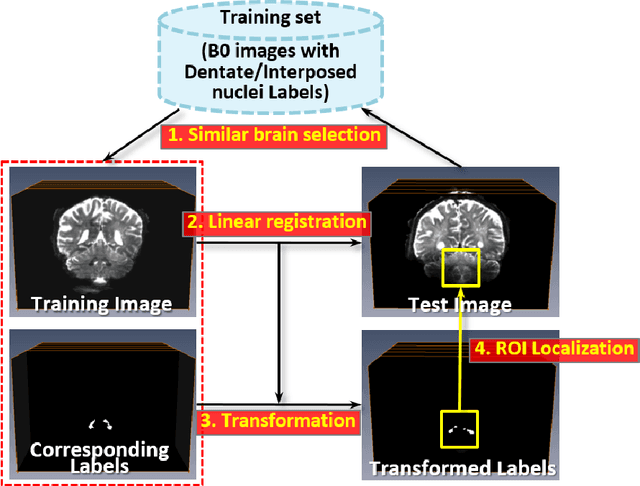

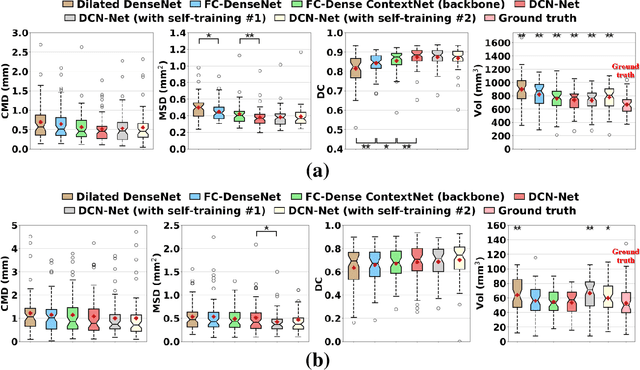
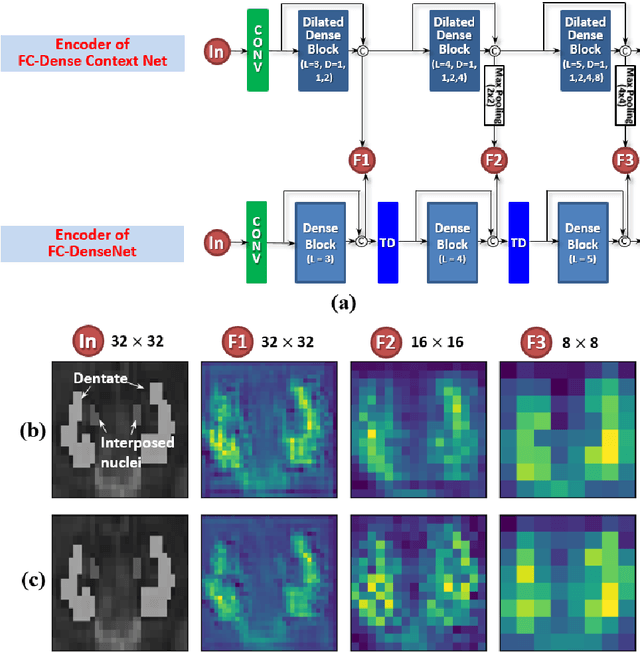
Deep cerebellar nuclei are a key structure of the cerebellum that are involved in processing motor and sensory information. It is thus a crucial step to accurately segment deep cerebellar nuclei for the understanding of the cerebellum system and its utility in deep brain stimulation treatment. However, it is challenging to clearly visualize such small nuclei under standard clinical magnetic resonance imaging (MRI) protocols and therefore precise segmentation is not feasible. Recent advances in 7 Tesla (T) MRI technology and great potential of deep neural networks facilitate automatic patient-specific segmentation. In this paper, we propose a novel deep learning framework (referred to as DCN-Net) for fast, accurate, and robust patient-specific segmentation of deep cerebellar dentate and interposed nuclei on 7T diffusion MRI. DCN-Net effectively encodes contextual information on the patch images without consecutive pooling operations and adding complexity via proposed dilated dense blocks. During the end-to-end training, label probabilities of dentate and interposed nuclei are independently learned with a hybrid loss, handling highly imbalanced data. Finally, we utilize self-training strategies to cope with the problem of limited labeled data. To this end, auxiliary dentate and interposed nuclei labels are created on unlabeled data by using DCN-Net trained on manual labels. We validate the proposed framework using 7T B0 MRIs from 60 subjects. Experimental results demonstrate that DCN-Net provides better segmentation than atlas-based deep cerebellar nuclei segmentation tools and other state-of-the-art deep neural networks in terms of accuracy and consistency. We further prove the effectiveness of the proposed components within DCN-Net in dentate and interposed nuclei segmentation.
Linear Depthwise Convolution for Single Image Super-Resolution
Aug 07, 2019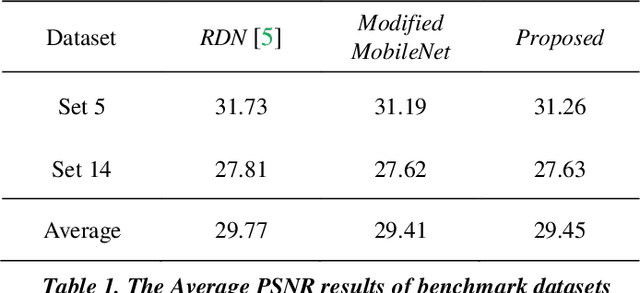

Recent work on super-resolution show that a very deep convolutional neural networks (CNN) have obtained remarkable performance. However, as CNN models have become deeper and wider, the required computational cost is substantially higher. In this paper, we propose Linear Depthwise Convolution to address this problem in single image super resolution. Specifically, Linear Depthwise Convolution can reduce computational burden on CNN model, preserving information used to reconstruct super-resolved image. The performance improvement of our proposed method is due to removing non-linearity between depthwise convolution and pointwise convolution. We evaluate the proposed approach using Set 5 and Set 14 datasets and show it performs significant better performance.