 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCNA-TTA: Clean and Noisy Region Aware Feature Learning within Clusters for Online-Offline Test-Time Adaptation
Paper and Code
Jan 26, 2024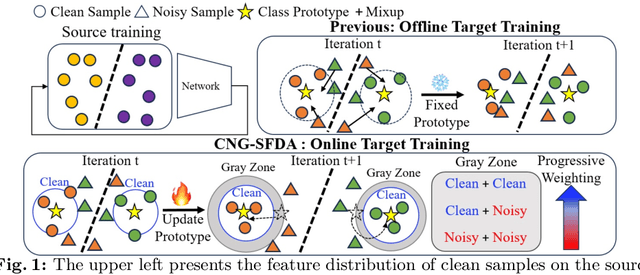

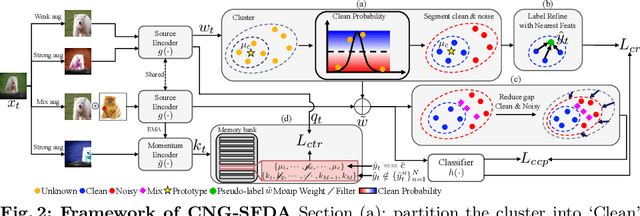
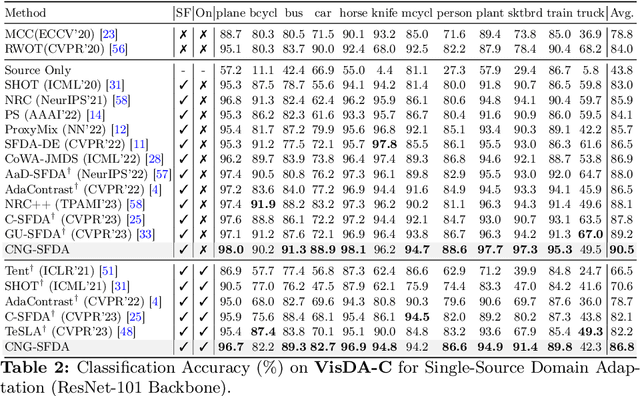
A domain shift occurs when training (source) and test (target) data diverge in their distribution. Test-time adaptation (TTA) addresses the domain shift problem, aiming to adopt a trained model on the source domain to the target domain in a scenario where only a well-trained source model and unlabeled target data are available. In this scenario, handling false labels in the target domain is crucial because they negatively impact the model performance. To deal with this problem, we propose to utilize cluster structure (i.e., {`Clean'} and {`Noisy'} regions within each cluster) in the target domain formulated by the source model. Given an initial clustering of target samples, we first partition clusters into {`Clean'} and {`Noisy'} regions defined based on cluster prototype (i.e., centroid of each cluster). As these regions have totally different distributions of the true pseudo-labels, we adopt distinct training strategies for the clean and noisy regions: we selectively train the target with clean pseudo-labels in the clean region, whereas we introduce mixup inputs representing intermediate features between clean and noisy regions to increase the compactness of the cluster. We conducted extensive experiments on multiple datasets in online/offline TTA settings, whose results demonstrate that our method, {CNA-TTA}, achieves state-of-the-art for most cases.