 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint-Embedding Predictive Architecture for Self-Supervised Learning of Mask Classification Architecture
Jul 15, 2024



In this work, we introduce Mask-JEPA, a self-supervised learning framework tailored for mask classification architectures (MCA), to overcome the traditional constraints associated with training segmentation models. Mask-JEPA combines a Joint Embedding Predictive Architecture with MCA to adeptly capture intricate semantics and precise object boundaries. Our approach addresses two critical challenges in self-supervised learning: 1) extracting comprehensive representations for universal image segmentation from a pixel decoder, and 2) effectively training the transformer decoder. The use of the transformer decoder as a predictor within the JEPA framework allows proficient training in universal image segmentation tasks. Through rigorous evaluations on datasets such as ADE20K, Cityscapes and COCO, Mask-JEPA demonstrates not only competitive results but also exceptional adaptability and robustness across various training scenarios. The architecture-agnostic nature of Mask-JEPA further underscores its versatility, allowing seamless adaptation to various mask classification family.
CNA-TTA: Clean and Noisy Region Aware Feature Learning within Clusters for Online-Offline Test-Time Adaptation
Jan 26, 2024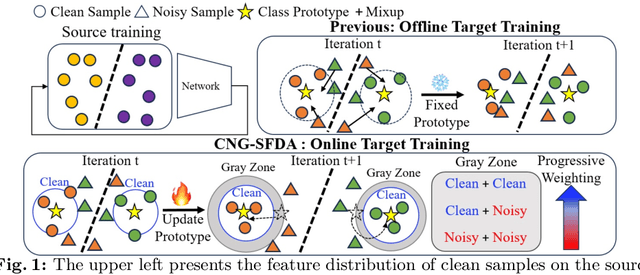

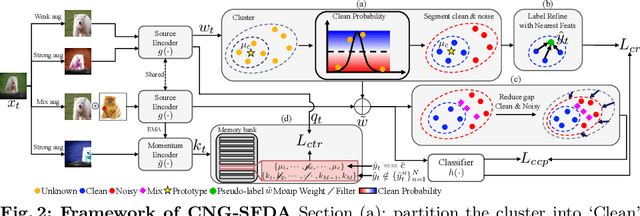
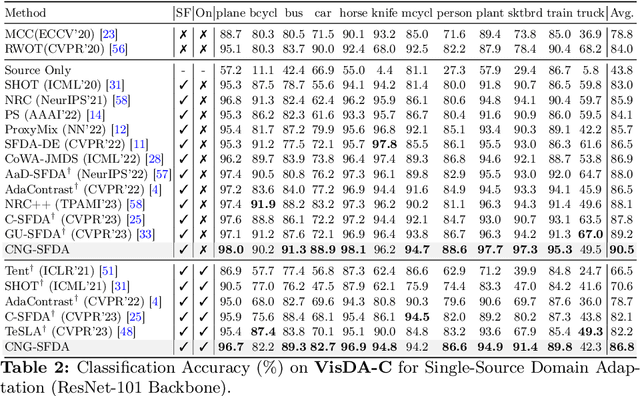
A domain shift occurs when training (source) and test (target) data diverge in their distribution. Test-time adaptation (TTA) addresses the domain shift problem, aiming to adopt a trained model on the source domain to the target domain in a scenario where only a well-trained source model and unlabeled target data are available. In this scenario, handling false labels in the target domain is crucial because they negatively impact the model performance. To deal with this problem, we propose to utilize cluster structure (i.e., {`Clean'} and {`Noisy'} regions within each cluster) in the target domain formulated by the source model. Given an initial clustering of target samples, we first partition clusters into {`Clean'} and {`Noisy'} regions defined based on cluster prototype (i.e., centroid of each cluster). As these regions have totally different distributions of the true pseudo-labels, we adopt distinct training strategies for the clean and noisy regions: we selectively train the target with clean pseudo-labels in the clean region, whereas we introduce mixup inputs representing intermediate features between clean and noisy regions to increase the compactness of the cluster. We conducted extensive experiments on multiple datasets in online/offline TTA settings, whose results demonstrate that our method, {CNA-TTA}, achieves state-of-the-art for most cases.