 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint-Embedding Predictive Architecture for Self-Supervised Learning of Mask Classification Architecture
Jul 15, 2024



In this work, we introduce Mask-JEPA, a self-supervised learning framework tailored for mask classification architectures (MCA), to overcome the traditional constraints associated with training segmentation models. Mask-JEPA combines a Joint Embedding Predictive Architecture with MCA to adeptly capture intricate semantics and precise object boundaries. Our approach addresses two critical challenges in self-supervised learning: 1) extracting comprehensive representations for universal image segmentation from a pixel decoder, and 2) effectively training the transformer decoder. The use of the transformer decoder as a predictor within the JEPA framework allows proficient training in universal image segmentation tasks. Through rigorous evaluations on datasets such as ADE20K, Cityscapes and COCO, Mask-JEPA demonstrates not only competitive results but also exceptional adaptability and robustness across various training scenarios. The architecture-agnostic nature of Mask-JEPA further underscores its versatility, allowing seamless adaptation to various mask classification family.
CNA-TTA: Clean and Noisy Region Aware Feature Learning within Clusters for Online-Offline Test-Time Adaptation
Jan 26, 2024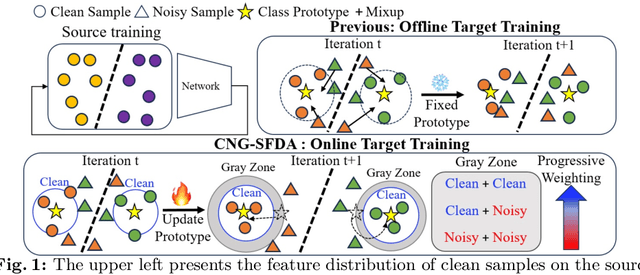

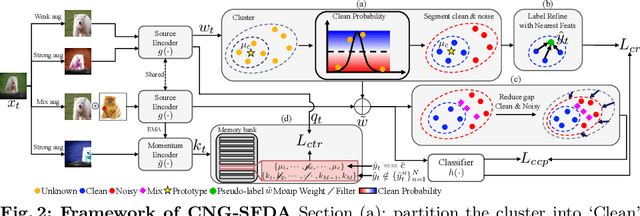
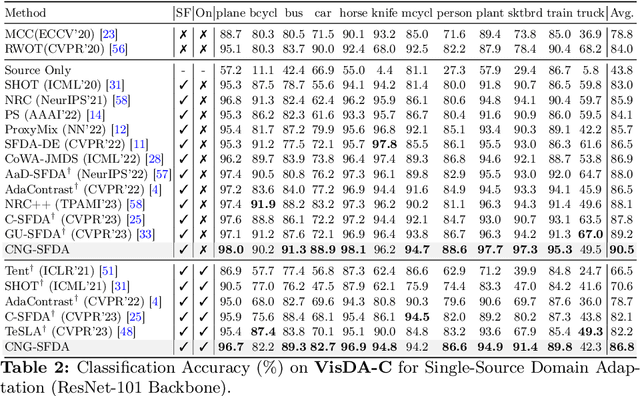
A domain shift occurs when training (source) and test (target) data diverge in their distribution. Test-time adaptation (TTA) addresses the domain shift problem, aiming to adopt a trained model on the source domain to the target domain in a scenario where only a well-trained source model and unlabeled target data are available. In this scenario, handling false labels in the target domain is crucial because they negatively impact the model performance. To deal with this problem, we propose to utilize cluster structure (i.e., {`Clean'} and {`Noisy'} regions within each cluster) in the target domain formulated by the source model. Given an initial clustering of target samples, we first partition clusters into {`Clean'} and {`Noisy'} regions defined based on cluster prototype (i.e., centroid of each cluster). As these regions have totally different distributions of the true pseudo-labels, we adopt distinct training strategies for the clean and noisy regions: we selectively train the target with clean pseudo-labels in the clean region, whereas we introduce mixup inputs representing intermediate features between clean and noisy regions to increase the compactness of the cluster. We conducted extensive experiments on multiple datasets in online/offline TTA settings, whose results demonstrate that our method, {CNA-TTA}, achieves state-of-the-art for most cases.
Effective Pseudo-Labeling based on Heatmap for Unsupervised Domain Adaptation in Cell Detection
Mar 09, 2023



Cell detection is an important task in biomedical research. Recently, deep learning methods have made it possible to improve the performance of cell detection. However, a detection network trained with training data under a specific condition (source domain) may not work well on data under other conditions (target domains), which is called the domain shift problem. In particular, cells are cultured under different conditions depending on the purpose of the research. Characteristics, e.g., the shapes and density of the cells, change depending on the conditions, and such changes may cause domain shift problems. Here, we propose an unsupervised domain adaptation method for cell detection using a pseudo-cell-position heatmap, where the cell centroid is at the peak of a Gaussian distribution in the map and selective pseudo-labeling. In the prediction result for the target domain, even if the peak location is correct, the signal distribution around the peak often has a non-Gaussian shape. The pseudo-cell-position heatmap is thus re-generated using the peak positions in the predicted heatmap to have a clear Gaussian shape. Our method selects confident pseudo-cell-position heatmaps based on uncertainty and curriculum learning. We conducted numerous experiments showing that, compared with the existing methods, our method improved detection performance under different conditions.
* 16 pages, 18 figures, Accepted in Medical Image Analysis 2022
Cell Detection in Domain Shift Problem Using Pseudo-Cell-Position Heatmap
Jul 19, 2021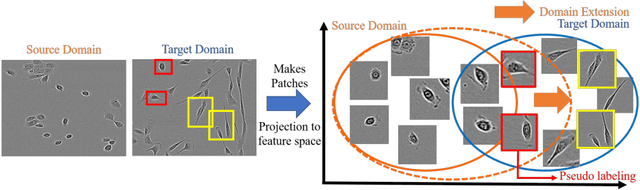

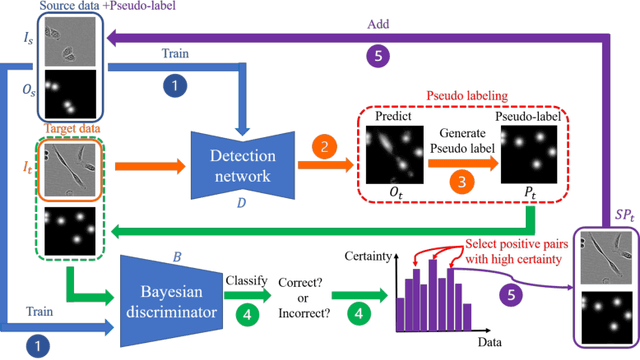
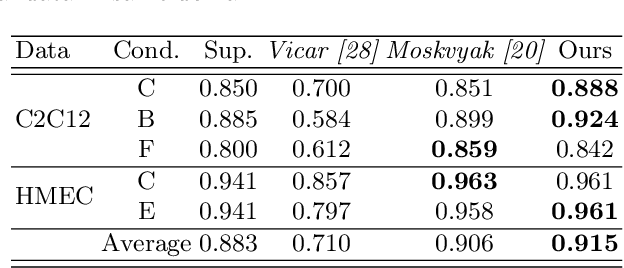
The domain shift problem is an important issue in automatic cell detection. A detection network trained with training data under a specific condition (source domain) may not work well in data under other conditions (target domain). We propose an unsupervised domain adaptation method for cell detection using the pseudo-cell-position heatmap, where a cell centroid becomes a peak with a Gaussian distribution in the map. In the prediction result for the target domain, even if a peak location is correct, the signal distribution around the peak often has anon-Gaussian shape. The pseudo-cell-position heatmap is re-generated using the peak positions in the predicted heatmap to have a clear Gaussian shape. Our method selects confident pseudo-cell-position heatmaps using a Bayesian network and adds them to the training data in the next iteration. The method can incrementally extend the domain from the source domain to the target domain in a semi-supervised manner. In the experiments using 8 combinations of domains, the proposed method outperformed the existing domain adaptation methods.
Semi-supervised Cell Detection in Time-lapse Images Using Temporal Consistency
Jul 19, 2021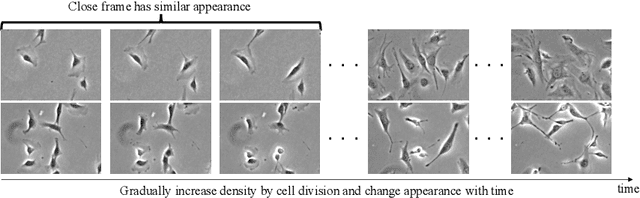
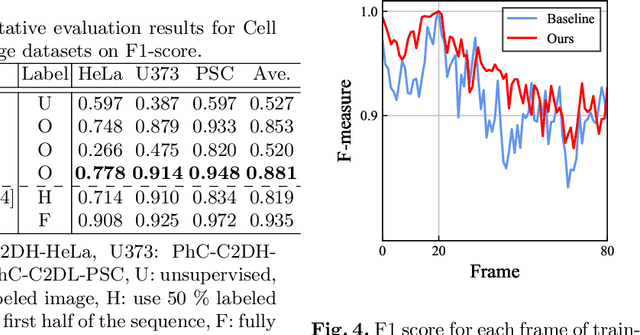

Cell detection is the task of detecting the approximate positions of cell centroids from microscopy images. Recently, convolutional neural network-based approaches have achieved promising performance. However, these methods require a certain amount of annotation for each imaging condition. This annotation is a time-consuming and labor-intensive task. To overcome this problem, we propose a semi-supervised cell-detection method that effectively uses a time-lapse sequence with one labeled image and the other images unlabeled. First, we train a cell-detection network with a one-labeled image and estimate the unlabeled images with the trained network. We then select high-confidence positions from the estimations by tracking the detected cells from the labeled frame to those far from it. Next, we generate pseudo-labels from the tracking results and train the network by using pseudo-labels. We evaluated our method for seven conditions of public datasets, and we achieved the best results relative to other semi-supervised methods. Our code is available at https://github.com/naivete5656/SCDTC