 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoSE: Skill-by-Skill Mixture-of-Expert Learning for Autonomous Driving
Jul 10, 2025
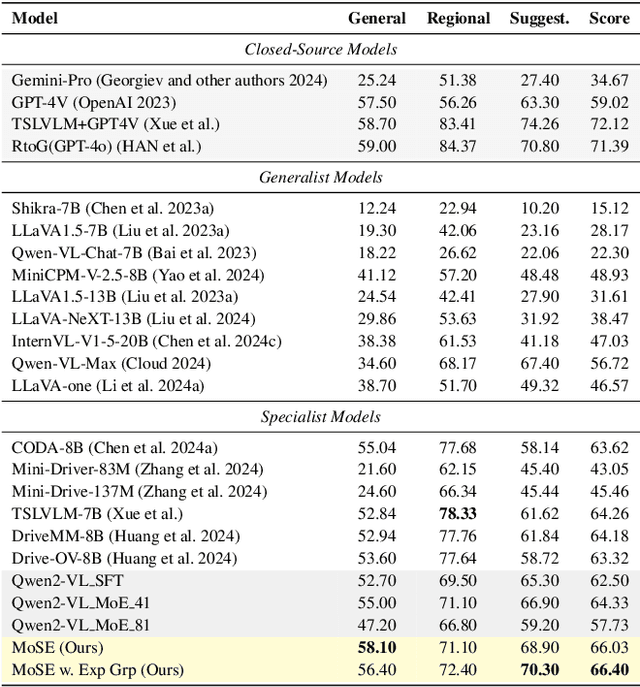
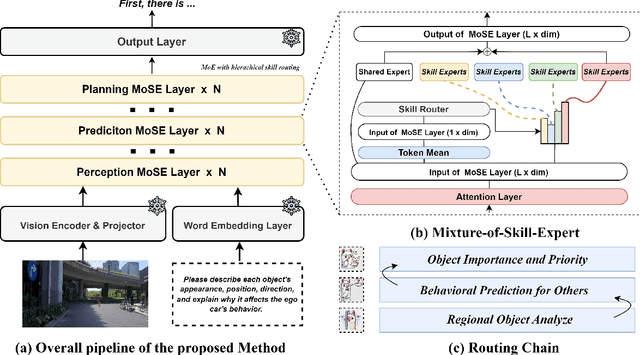
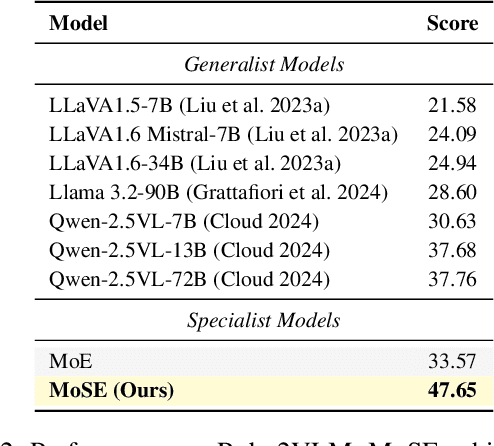
Recent studies show large language models (LLMs) and vision language models (VLMs) trained using web-scale data can empower end-to-end autonomous driving systems for a better generalization and interpretation. Specifically, by dynamically routing inputs to specialized subsets of parameters, the Mixture-of-Experts (MoE) technique enables general LLMs or VLMs to achieve substantial performance improvements while maintaining computational efficiency. However, general MoE models usually demands extensive training data and complex optimization. In this work, inspired by the learning process of human drivers, we propose a skill-oriented MoE, called MoSE, which mimics human drivers' learning process and reasoning process, skill-by-skill and step-by-step. We propose a skill-oriented routing mechanism that begins with defining and annotating specific skills, enabling experts to identify the necessary driving competencies for various scenarios and reasoning tasks, thereby facilitating skill-by-skill learning. Further align the driving process to multi-step planning in human reasoning and end-to-end driving models, we build a hierarchical skill dataset and pretrain the router to encourage the model to think step-by-step. Unlike multi-round dialogs, MoSE integrates valuable auxiliary tasks (e.g.\ description, reasoning, planning) in one single forward process without introducing any extra computational cost. With less than 3B sparsely activated parameters, our model outperforms several 8B+ parameters on CODA AD corner case reasoning task. Compared to existing methods based on open-source models and data, our approach achieves state-of-the-art performance with significantly reduced activated model size (at least by $62.5\%$) with a single-turn conversation.
How Can Objects Help Video-Language Understanding?
Apr 10, 2025How multimodal large language models (MLLMs) perceive the visual world remains a mystery. To one extreme, object and relation modeling may be implicitly implemented with inductive biases, for example by treating objects as tokens. To the other extreme, empirical results reveal the surprising finding that simply performing visual captioning, which tends to ignore spatial configuration of the objects, serves as a strong baseline for video understanding. We aim to answer the question: how can objects help video-language understanding in MLLMs? We tackle the question from the object representation and adaptation perspectives. Specifically, we investigate the trade-off between representation expressiveness (e.g., distributed versus symbolic) and integration difficulty (e.g., data-efficiency when learning the adapters). Through extensive evaluations on five video question answering datasets, we confirm that explicit integration of object-centric representation remains necessary, and the symbolic objects can be most easily integrated while being performant for question answering. We hope our findings can encourage the community to explore the explicit integration of perception modules into MLLM design. Our code and models will be publicly released.