 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomainCQA: Crafting Expert-Level QA from Domain-Specific Charts
Paper and Code
Mar 25, 2025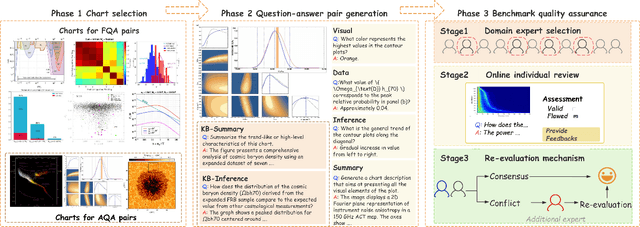
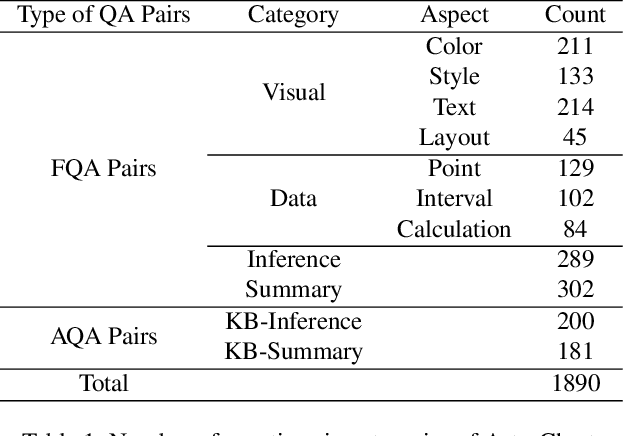
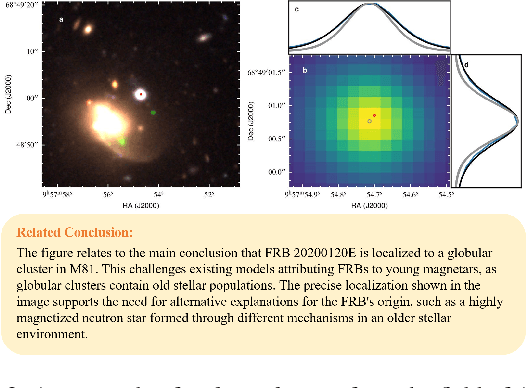
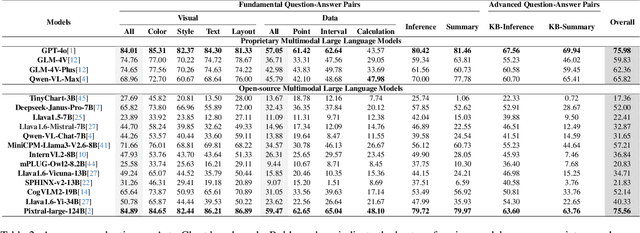
Chart Question Answering (CQA) benchmarks are essential for evaluating the capability of Multimodal Large Language Models (MLLMs) to interpret visual data. However, current benchmarks focus primarily on the evaluation of general-purpose CQA but fail to adequately capture domain-specific challenges. We introduce DomainCQA, a systematic methodology for constructing domain-specific CQA benchmarks, and demonstrate its effectiveness by developing AstroChart, a CQA benchmark in the field of astronomy. Our evaluation shows that chart reasoning and combining chart information with domain knowledge for deeper analysis and summarization, rather than domain-specific knowledge, pose the primary challenge for existing MLLMs, highlighting a critical gap in current benchmarks. By providing a scalable and rigorous framework, DomainCQA enables more precise assessment and improvement of MLLMs for domain-specific applications.