 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHUSKY: Humanoid Skateboarding System via Physics-Aware Whole-Body Control
Feb 03, 2026While current humanoid whole-body control frameworks predominantly rely on the static environment assumptions, addressing tasks characterized by high dynamism and complex interactions presents a formidable challenge. In this paper, we address humanoid skateboarding, a highly challenging task requiring stable dynamic maneuvering on an underactuated wheeled platform. This integrated system is governed by non-holonomic constraints and tightly coupled human-object interactions. Successfully executing this task requires simultaneous mastery of hybrid contact dynamics and robust balance control on a mechanically coupled, dynamically unstable skateboard. To overcome the aforementioned challenges, we propose HUSKY, a learning-based framework that integrates humanoid-skateboard system modeling and physics-aware whole-body control. We first model the coupling relationship between board tilt and truck steering angles, enabling a principled analysis of system dynamics. Building upon this, HUSKY leverages Adversarial Motion Priors (AMP) to learn human-like pushing motions and employs a physics-guided, heading-oriented strategy for lean-to-steer behaviors. Moreover, a trajectory-guided mechanism ensures smooth and stable transitions between pushing and steering. Experimental results on the Unitree G1 humanoid platform demonstrate that our framework enables stable and agile maneuvering on skateboards in real-world scenarios. The project page is available on https://husky-humanoid.github.io/.
Towards Adaptive Humanoid Control via Multi-Behavior Distillation and Reinforced Fine-Tuning
Nov 11, 2025Humanoid robots are promising to learn a diverse set of human-like locomotion behaviors, including standing up, walking, running, and jumping. However, existing methods predominantly require training independent policies for each skill, yielding behavior-specific controllers that exhibit limited generalization and brittle performance when deployed on irregular terrains and in diverse situations. To address this challenge, we propose Adaptive Humanoid Control (AHC) that adopts a two-stage framework to learn an adaptive humanoid locomotion controller across different skills and terrains. Specifically, we first train several primary locomotion policies and perform a multi-behavior distillation process to obtain a basic multi-behavior controller, facilitating adaptive behavior switching based on the environment. Then, we perform reinforced fine-tuning by collecting online feedback in performing adaptive behaviors on more diverse terrains, enhancing terrain adaptability for the controller. We conduct experiments in both simulation and real-world experiments in Unitree G1 robots. The results show that our method exhibits strong adaptability across various situations and terrains. Project website: https://ahc-humanoid.github.io.
MoRE: Mixture of Residual Experts for Humanoid Lifelike Gaits Learning on Complex Terrains
Jun 12, 2025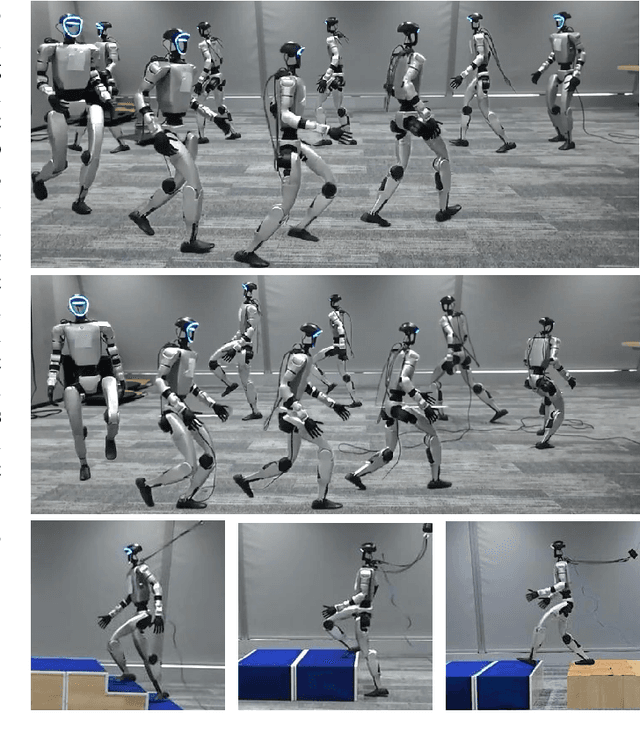
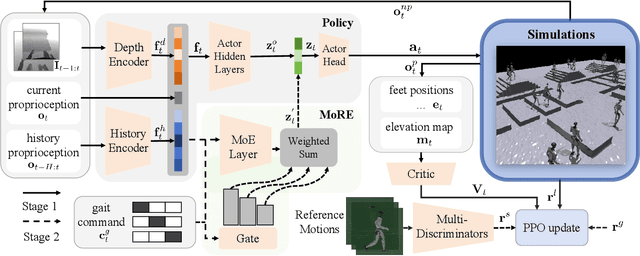
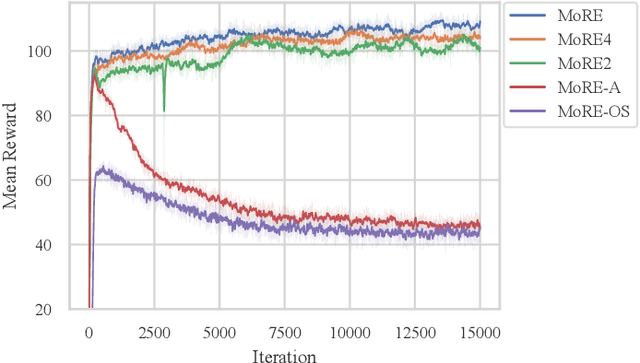
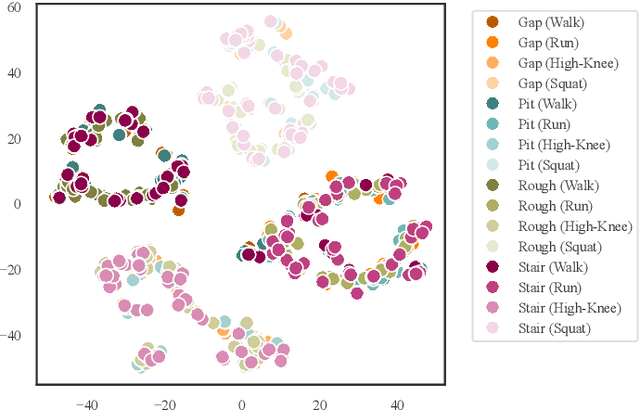
Humanoid robots have demonstrated robust locomotion capabilities using Reinforcement Learning (RL)-based approaches. Further, to obtain human-like behaviors, existing methods integrate human motion-tracking or motion prior in the RL framework. However, these methods are limited in flat terrains with proprioception only, restricting their abilities to traverse challenging terrains with human-like gaits. In this work, we propose a novel framework using a mixture of latent residual experts with multi-discriminators to train an RL policy, which is capable of traversing complex terrains in controllable lifelike gaits with exteroception. Our two-stage training pipeline first teaches the policy to traverse complex terrains using a depth camera, and then enables gait-commanded switching between human-like gait patterns. We also design gait rewards to adjust human-like behaviors like robot base height. Simulation and real-world experiments demonstrate that our framework exhibits exceptional performance in traversing complex terrains, and achieves seamless transitions between multiple human-like gait patterns.
Adversarial Locomotion and Motion Imitation for Humanoid Policy Learning
Apr 19, 2025Humans exhibit diverse and expressive whole-body movements. However, attaining human-like whole-body coordination in humanoid robots remains challenging, as conventional approaches that mimic whole-body motions often neglect the distinct roles of upper and lower body. This oversight leads to computationally intensive policy learning and frequently causes robot instability and falls during real-world execution. To address these issues, we propose Adversarial Locomotion and Motion Imitation (ALMI), a novel framework that enables adversarial policy learning between upper and lower body. Specifically, the lower body aims to provide robust locomotion capabilities to follow velocity commands while the upper body tracks various motions. Conversely, the upper-body policy ensures effective motion tracking when the robot executes velocity-based movements. Through iterative updates, these policies achieve coordinated whole-body control, which can be extended to loco-manipulation tasks with teleoperation systems. Extensive experiments demonstrate that our method achieves robust locomotion and precise motion tracking in both simulation and on the full-size Unitree H1 robot. Additionally, we release a large-scale whole-body motion control dataset featuring high-quality episodic trajectories from MuJoCo simulations deployable on real robots. The project page is https://almi-humanoid.github.io.
ML-Triton, A Multi-Level Compilation and Language Extension to Triton GPU Programming
Mar 19, 2025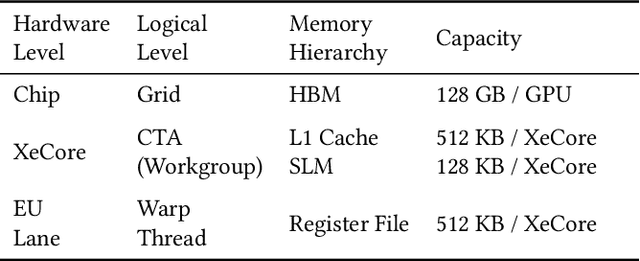



In the era of LLMs, dense operations such as GEMM and MHA are critical components. These operations are well-suited for parallel execution using a tilebased approach. While traditional GPU programming often relies on low level interfaces like CUDA or SYCL, Triton has emerged as a DSL that offers a more user-friendly and portable alternative by programming at a higher level. The current Triton starts at the workgroup (aka threadblock) level, and directly lowers to per-thread level. And then attempt to coalesce and amend through a series of passes, promoting information from low-level representation. We believe this is pre-mature lowering based on the below observations. 1. GPU has a hierarchical structure both physically and logically. Modern GPUs often feature SIMD units capable of directly operating on tiles on a warp or warpgroup basis, such as blocked load and blocked MMA. 2. Multi-level gradual lowering can make compiler decoupled and clean by separating considerations inter and intra a logical layer. 3. Kernel developers often need fine control to get good performance on the latest hardware. FlashAttention2 advocates explicit data partition between warps to make a performance boost. In this context, we propose ML-Triton which features multi-level compilation flow and programming interface. Our approach begins at the workgroup level and progressively lowers to the warp and intrinsic level, implementing a multilevel lowering align with the hierarchical nature of GPU. Additionally, we extend triton language to support user-set compiler hint and warp level programming, enabling researchers to get good out-of-the box performance without awaiting compiler updates. Experimental results demonstrate that our approach achieves performance above 95% of expert-written kernels on Intel GPU, as measured by the geometric mean.
Hy-DAT: A Tool to Address Hydropower Modeling Gaps Using Interdependency, Efficiency Curves, and Unit Dispatch Models
Mar 05, 2024



As the power system continues to be flooded with intermittent resources, it becomes more important to accurately assess the role of hydro and its impact on the power grid. While hydropower generation has been studied for decades, dependency of power generation on water availability and constraints in hydro operation are not well represented in power system models used in the planning and operation of large-scale interconnection studies. There are still multiple modeling gaps that need to be addressed; if not, they can lead to inaccurate operation and planning reliability studies, and consequently to unintentional load shedding or even blackouts. As a result, it is very important that hydropower is represented correctly in both steady-state and dynamic power system studies. In this paper, we discuss the development and use of the Hydrological Dispatch and Analysis Tool (Hy-DAT) as an interactive graphical user interface, that uses a novel methodology to address the hydropower modeling gaps like water availability and interdependency using a database and algorithms to generate accurate representative models for power system simulation.
Always-On, Sub-300-nW, Event-Driven Spiking Neural Network based on Spike-Driven Clock-Generation and Clock- and Power-Gating for an Ultra-Low-Power Intelligent Device
Jun 23, 2020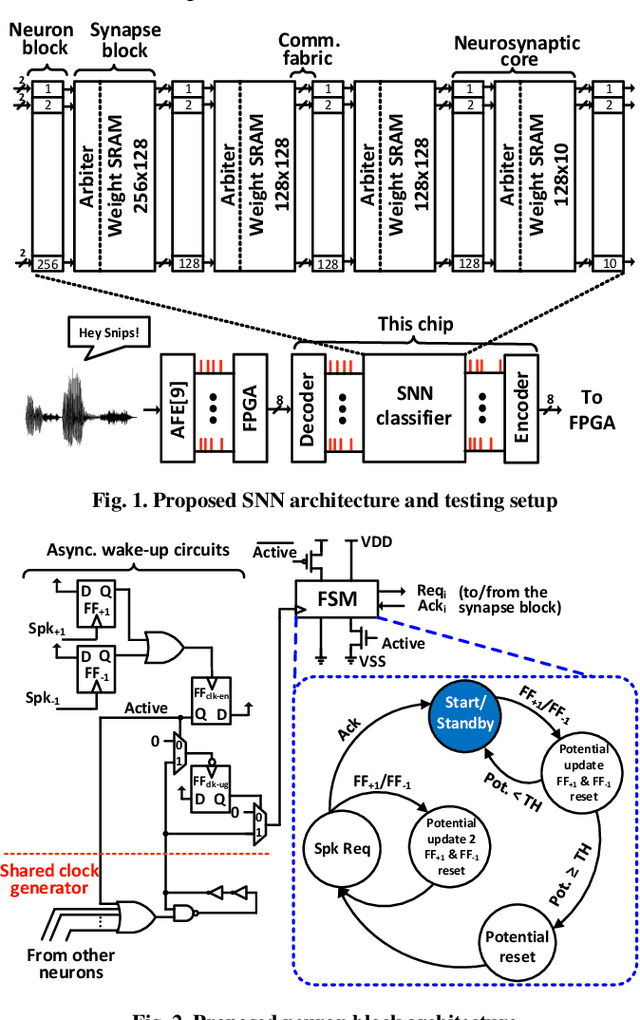
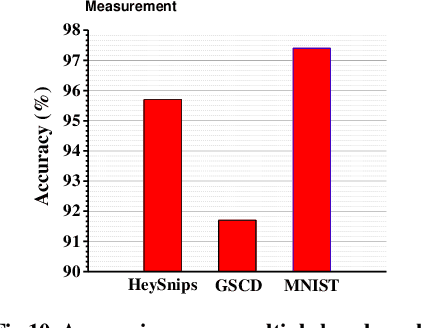
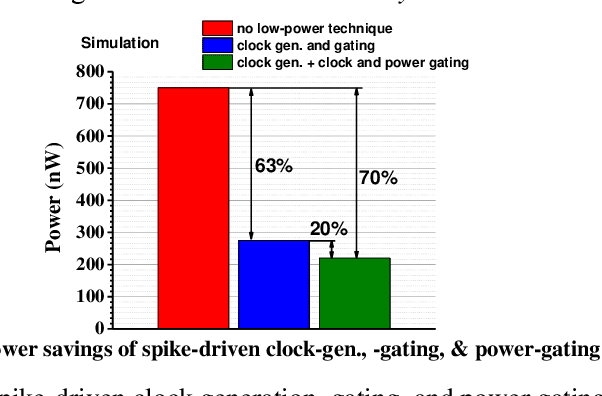
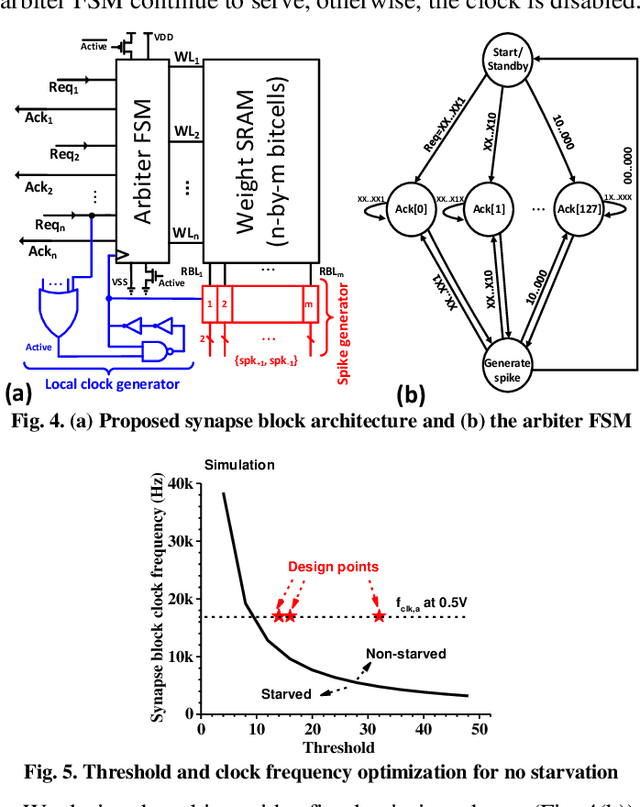
Always-on artificial intelligent (AI) functions such as keyword spotting (KWS) and visual wake-up tend to dominate total power consumption in ultra-low power devices. A key observation is that the signals to an always-on function are sparse in time, which a spiking neural network (SNN) classifier can leverage for power savings, because the switching activity and power consumption of SNNs tend to scale with spike rate. Toward this goal, we present a novel SNN classifier architecture for always-on functions, demonstrating sub-300nW power consumption at the competitive inference accuracy for a KWS and other always-on classification workloads.