 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFiber: A Platform for Efficient Development and Distributed Training for Reinforcement Learning and Population-Based Methods
Paper and Code
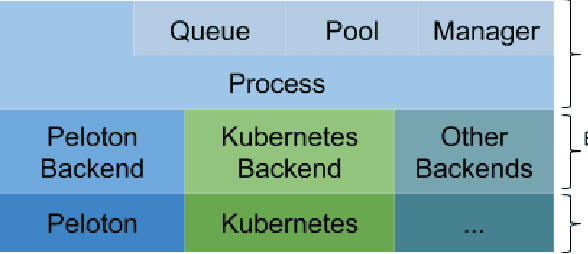
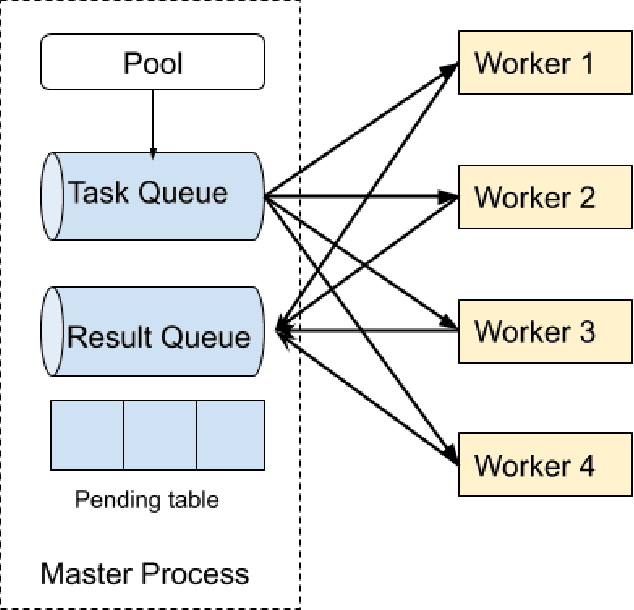
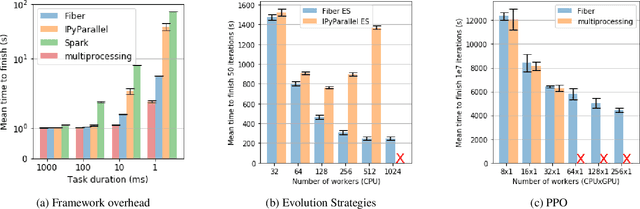
Recent advances in machine learning are consistently enabled by increasing amounts of computation. Reinforcement learning (RL) and population-based methods in particular pose unique challenges for efficiency and flexibility to the underlying distributed computing frameworks. These challenges include frequent interaction with simulations, the need for dynamic scaling, and the need for a user interface with low adoption cost and consistency across different backends. In this paper we address these challenges while still retaining development efficiency and flexibility for both research and practical applications by introducing Fiber, a scalable distributed computing framework for RL and population-based methods. Fiber aims to significantly expand the accessibility of large-scale parallel computation to users of otherwise complicated RL and population-based approaches without the need to for specialized computational expertise.