 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDescriptor: Distance-Annotated Traffic Perception Question Answering (DTPQA)
Nov 17, 2025The remarkable progress of Vision-Language Models (VLMs) on a variety of tasks has raised interest in their application to automated driving. However, for these models to be trusted in such a safety-critical domain, they must first possess robust perception capabilities, i.e., they must be capable of understanding a traffic scene, which can often be highly complex, with many things happening simultaneously. Moreover, since critical objects and agents in traffic scenes are often at long distances, we require systems with not only strong perception capabilities at close distances (up to 20 meters), but also at long (30+ meters) range. Therefore, it is important to evaluate the perception capabilities of these models in isolation from other skills like reasoning or advanced world knowledge. Distance-Annotated Traffic Perception Question Answering (DTPQA) is a Visual Question Answering (VQA) benchmark designed specifically for this purpose: it can be used to evaluate the perception systems of VLMs in traffic scenarios using trivial yet crucial questions relevant to driving decisions. It consists of two parts: a synthetic benchmark (DTP-Synthetic) created using a simulator, and a real-world benchmark (DTP-Real) built on top of existing images of real traffic scenes. Additionally, DTPQA includes distance annotations, i.e., how far the object in question is from the camera. More specifically, each DTPQA sample consists of (at least): (a) an image, (b) a question, (c) the ground truth answer, and (d) the distance of the object in question, enabling analysis of how VLM performance degrades with increasing object distance. In this article, we provide the dataset itself along with the Python scripts used to create it, which can be used to generate additional data of the same kind.
FIN: Fast Inference Network for Map Segmentation
Oct 01, 2025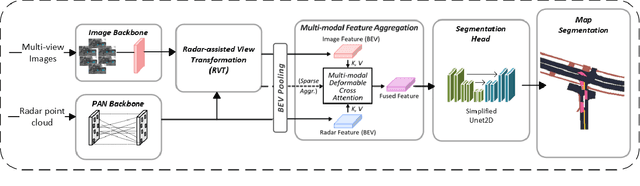
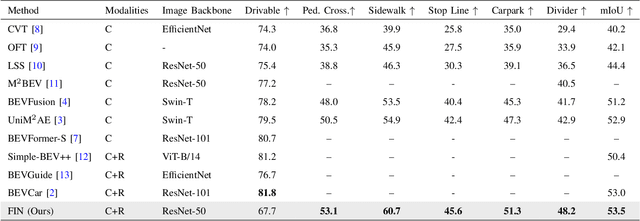
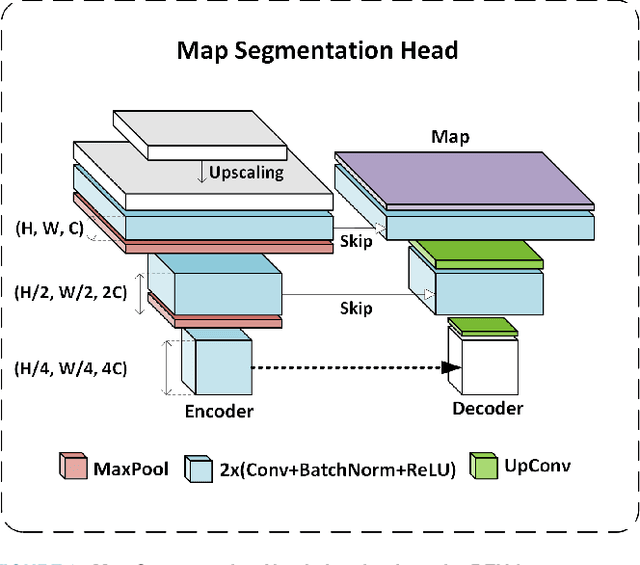
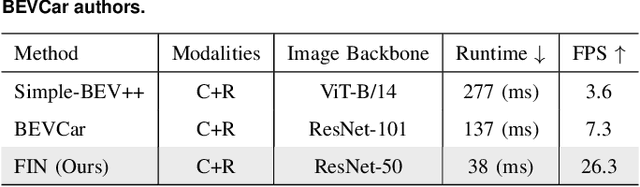
Multi-sensor fusion in autonomous vehicles is becoming more common to offer a more robust alternative for several perception tasks. This need arises from the unique contribution of each sensor in collecting data: camera-radar fusion offers a cost-effective solution by combining rich semantic information from cameras with accurate distance measurements from radar, without incurring excessive financial costs or overwhelming data processing requirements. Map segmentation is a critical task for enabling effective vehicle behaviour in its environment, yet it continues to face significant challenges in achieving high accuracy and meeting real-time performance requirements. Therefore, this work presents a novel and efficient map segmentation architecture, using cameras and radars, in the \acrfull{bev} space. Our model introduces a real-time map segmentation architecture considering aspects such as high accuracy, per-class balancing, and inference time. To accomplish this, we use an advanced loss set together with a new lightweight head to improve the perception results. Our results show that, with these modifications, our approach achieves results comparable to large models, reaching 53.5 mIoU, while also setting a new benchmark for inference time, improving it by 260\% over the strongest baseline models.
Deformable Convolution Based Road Scene Semantic Segmentation of Fisheye Images in Autonomous Driving
Jul 23, 2024



This study investigates the effectiveness of modern Deformable Convolutional Neural Networks (DCNNs) for semantic segmentation tasks, particularly in autonomous driving scenarios with fisheye images. These images, providing a wide field of view, pose unique challenges for extracting spatial and geometric information due to dynamic changes in object attributes. Our experiments focus on segmenting the WoodScape fisheye image dataset into ten distinct classes, assessing the Deformable Networks' ability to capture intricate spatial relationships and improve segmentation accuracy. Additionally, we explore different loss functions to address class imbalance issues and compare the performance of conventional CNN architectures with Deformable Convolution-based CNNs, including Vanilla U-Net and Residual U-Net architectures. The significant improvement in mIoU score resulting from integrating Deformable CNNs demonstrates their effectiveness in handling the geometric distortions present in fisheye imagery, exceeding the performance of traditional CNN architectures. This underscores the significant role of Deformable convolution in enhancing semantic segmentation performance for fisheye imagery.
SS-SFR: Synthetic Scenes Spatial Frequency Response on Virtual KITTI and Degraded Automotive Simulations for Object Detection
Jul 22, 2024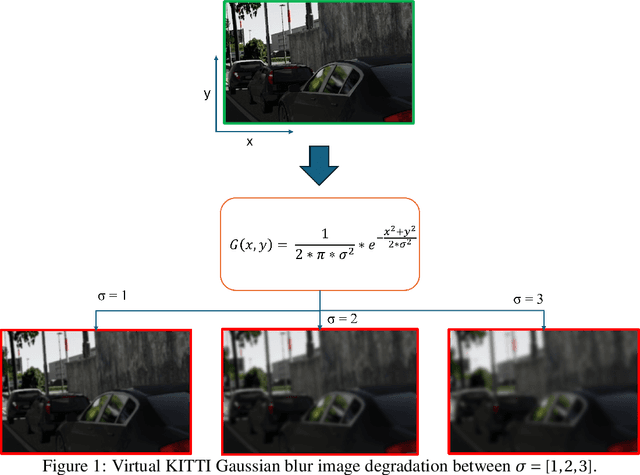

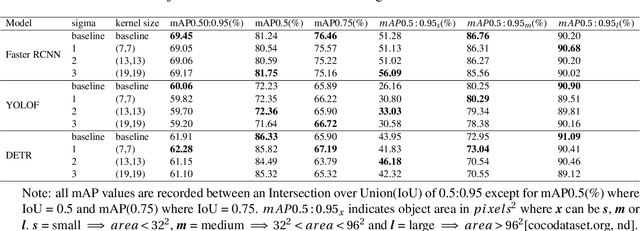
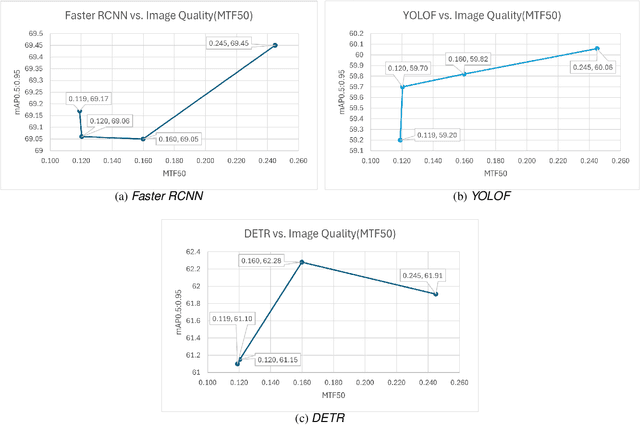
Automotive simulation can potentially compensate for a lack of training data in computer vision applications. However, there has been little to no image quality evaluation of automotive simulation and the impact of optical degradations on simulation is little explored. In this work, we investigate Virtual KITTI and the impact of applying variations of Gaussian blur on image sharpness. Furthermore, we consider object detection, a common computer vision application on three different state-of-the-art models, thus allowing us to characterize the relationship between object detection and sharpness. It was found that while image sharpness (MTF50) degrades from an average of 0.245cy/px to approximately 0.119cy/px; object detection performance stays largely robust within 0.58\%(Faster RCNN), 1.45\%(YOLOF) and 1.93\%(DETR) across all respective held-out test sets.
* 8 pages, 2 figures, 2 tables