 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Based Font Pair Suggestion Modelling For Graphic Design
Jan 19, 2025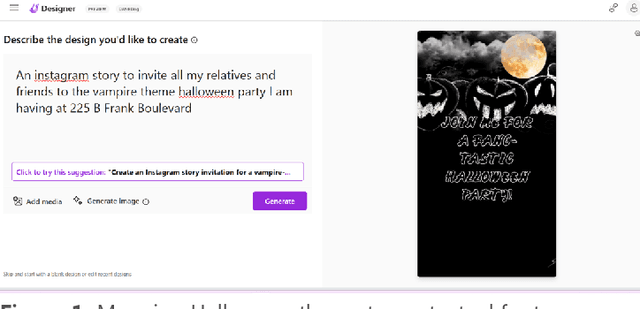
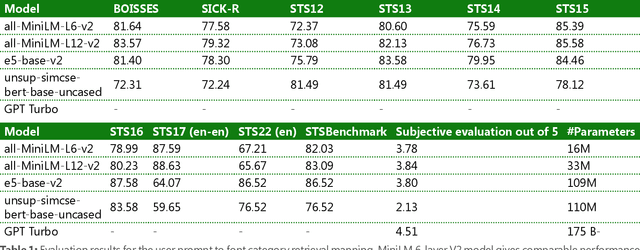
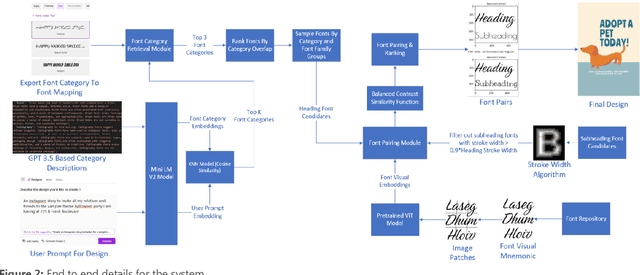

One of the key challenges of AI generated designs in Microsoft Designer is selecting the most contextually relevant and novel fonts for the design suggestions. Previous efforts involved manually mapping design intent to fonts. Though this was high quality, this method does not scale for a large number of fonts (3000+) and numerous user intents for graphic design. In this work we create font visual embeddings, a font stroke width algorithm, a font category to font mapping dataset, an LLM-based category utilization description and a lightweight, low latency knowledge-distilled mini language model (Mini LM V2) to recommend multiple pairs of contextual heading and subheading fonts for beautiful and intuitive designs. We also utilize a weighted scoring mechanism, nearest neighbor approach and stratified sampling to rank the font pairs and bring novelty to the predictions.
Image Segmentation: Inducing graph-based learning
Jan 07, 2025This study explores the potential of graph neural networks (GNNs) to enhance semantic segmentation across diverse image modalities. We evaluate the effectiveness of a novel GNN-based U-Net architecture on three distinct datasets: PascalVOC, a standard benchmark for natural image segmentation, WoodScape, a challenging dataset of fisheye images commonly used in autonomous driving, introducing significant geometric distortions; and ISIC2016, a dataset of dermoscopic images for skin lesion segmentation. We compare our proposed UNet-GNN model against established convolutional neural networks (CNNs) based segmentation models, including U-Net and U-Net++, as well as the transformer-based SwinUNet. Unlike these methods, which primarily rely on local convolutional operations or global self-attention, GNNs explicitly model relationships between image regions by constructing and operating on a graph representation of the image features. This approach allows the model to capture long-range dependencies and complex spatial relationships, which we hypothesize will be particularly beneficial for handling geometric distortions present in fisheye imagery and capturing intricate boundaries in medical images. Our analysis demonstrates the versatility of GNNs in addressing diverse segmentation challenges and highlights their potential to improve segmentation accuracy in various applications, including autonomous driving and medical image analysis.
Deformable Convolution Based Road Scene Semantic Segmentation of Fisheye Images in Autonomous Driving
Jul 23, 2024



This study investigates the effectiveness of modern Deformable Convolutional Neural Networks (DCNNs) for semantic segmentation tasks, particularly in autonomous driving scenarios with fisheye images. These images, providing a wide field of view, pose unique challenges for extracting spatial and geometric information due to dynamic changes in object attributes. Our experiments focus on segmenting the WoodScape fisheye image dataset into ten distinct classes, assessing the Deformable Networks' ability to capture intricate spatial relationships and improve segmentation accuracy. Additionally, we explore different loss functions to address class imbalance issues and compare the performance of conventional CNN architectures with Deformable Convolution-based CNNs, including Vanilla U-Net and Residual U-Net architectures. The significant improvement in mIoU score resulting from integrating Deformable CNNs demonstrates their effectiveness in handling the geometric distortions present in fisheye imagery, exceeding the performance of traditional CNN architectures. This underscores the significant role of Deformable convolution in enhancing semantic segmentation performance for fisheye imagery.
Subgraph Clustering and Atom Learning for Improved Image Classification
Jul 20, 2024In this study, we present the Graph Sub-Graph Network (GSN), a novel hybrid image classification model merging the strengths of Convolutional Neural Networks (CNNs) for feature extraction and Graph Neural Networks (GNNs) for structural modeling. GSN employs k-means clustering to group graph nodes into clusters, facilitating the creation of subgraphs. These subgraphs are then utilized to learn representative `atoms` for dictionary learning, enabling the identification of sparse, class-distinguishable features. This integrated approach is particularly relevant in domains like medical imaging, where discerning subtle feature differences is crucial for accurate classification. To evaluate the performance of our proposed GSN, we conducted experiments on benchmark datasets, including PascalVOC and HAM10000. Our results demonstrate the efficacy of our model in optimizing dictionary configurations across varied classes, which contributes to its effectiveness in medical classification tasks. This performance enhancement is primarily attributed to the integration of CNNs, GNNs, and graph learning techniques, which collectively improve the handling of datasets with limited labeled examples. Specifically, our experiments show that the model achieves a higher accuracy on benchmark datasets such as Pascal VOC and HAM10000 compared to conventional CNN approaches.
Optimizing Ego Vehicle Trajectory Prediction: The Graph Enhancement Approach
Jan 10, 2024Predicting the trajectory of an ego vehicle is a critical component of autonomous driving systems. Current state-of-the-art methods typically rely on Deep Neural Networks (DNNs) and sequential models to process front-view images for future trajectory prediction. However, these approaches often struggle with perspective issues affecting object features in the scene. To address this, we advocate for the use of Bird's Eye View (BEV) perspectives, which offer unique advantages in capturing spatial relationships and object homogeneity. In our work, we leverage Graph Neural Networks (GNNs) and positional encoding to represent objects in a BEV, achieving competitive performance compared to traditional DNN-based methods. While the BEV-based approach loses some detailed information inherent to front-view images, we balance this by enriching the BEV data by representing it as a graph where relationships between the objects in a scene are captured effectively.
Large Language Models aren't all that you need
Jan 01, 2024This paper describes the architecture and systems built towards solving the SemEval 2023 Task 2: MultiCoNER II (Multilingual Complex Named Entity Recognition) [1]. We evaluate two approaches (a) a traditional Conditional Random Fields model and (b) a Large Language Model (LLM) fine-tuned with a customized head and compare the two approaches. The novel ideas explored are: 1) Decaying auxiliary loss (with residual) - where we train the model on an auxiliary task of Coarse-Grained NER and include this task as a part of the loss function 2) Triplet token blending - where we explore ways of blending the embeddings of neighboring tokens in the final NER layer prior to prediction 3) Task-optimal heads - where we explore a variety of custom heads and learning rates for the final layer of the LLM. We also explore multiple LLMs including GPT-3 and experiment with a variety of dropout and other hyperparameter settings before arriving at our final model which achieves micro & macro f1 of 0.85/0.84 (on dev) and 0.67/0.61 on the test data . We show that while pre-trained LLMs, by themselves, bring about a large improvement in scores as compared to traditional models, we also demonstrate that tangible improvements to the Macro-F1 score can be made by augmenting the LLM with additional feature/loss/model engineering techniques described above.
Connecting the Dots: Graph Neural Network Powered Ensemble and Classification of Medical Images
Nov 13, 2023Deep learning models have demonstrated remarkable results for various computer vision tasks, including the realm of medical imaging. However, their application in the medical domain is limited due to the requirement for large amounts of training data, which can be both challenging and expensive to obtain. To mitigate this, pre-trained models have been fine-tuned on domain-specific data, but such an approach can suffer from inductive biases. Furthermore, deep learning models struggle to learn the relationship between spatially distant features and their importance, as convolution operations treat all pixels equally. Pioneering a novel solution to this challenge, we employ the Image Foresting Transform to optimally segment images into superpixels. These superpixels are subsequently transformed into graph-structured data, enabling the proficient extraction of features and modeling of relationships using Graph Neural Networks (GNNs). Our method harnesses an ensemble of three distinct GNN architectures to boost its robustness. In our evaluations targeting pneumonia classification, our methodology surpassed prevailing Deep Neural Networks (DNNs) in performance, all while drastically cutting down on the parameter count. This not only trims down the expenses tied to data but also accelerates training and minimizes bias. Consequently, our proposition offers a sturdy, economically viable, and scalable strategy for medical image classification, significantly diminishing dependency on extensive training data sets.
* Our code is available at https://github.com/aryan-at-ul/AICS_2023_submission
Compact & Capable: Harnessing Graph Neural Networks and Edge Convolution for Medical Image Classification
Jul 24, 2023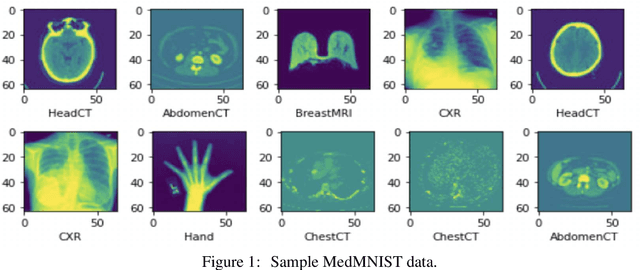
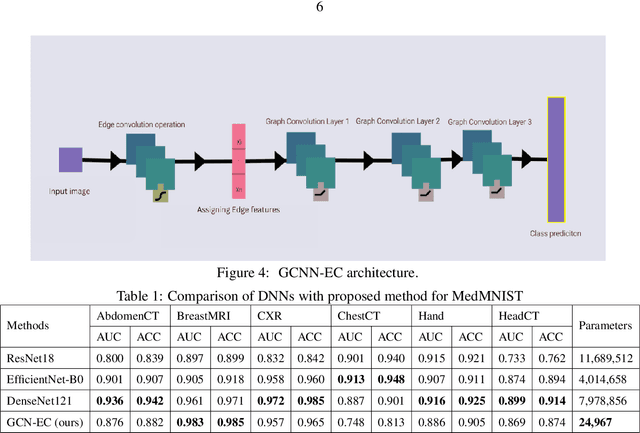
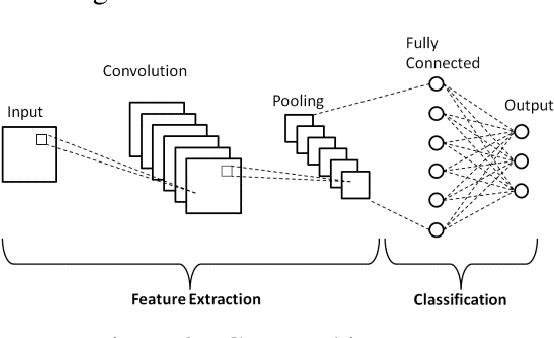
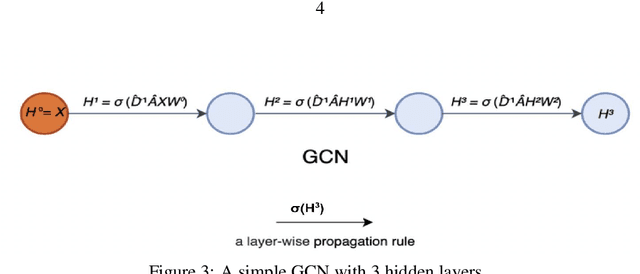
Graph-based neural network models are gaining traction in the field of representation learning due to their ability to uncover latent topological relationships between entities that are otherwise challenging to identify. These models have been employed across a diverse range of domains, encompassing drug discovery, protein interactions, semantic segmentation, and fluid dynamics research. In this study, we investigate the potential of Graph Neural Networks (GNNs) for medical image classification. We introduce a novel model that combines GNNs and edge convolution, leveraging the interconnectedness of RGB channel feature values to strongly represent connections between crucial graph nodes. Our proposed model not only performs on par with state-of-the-art Deep Neural Networks (DNNs) but does so with 1000 times fewer parameters, resulting in reduced training time and data requirements. We compare our Graph Convolutional Neural Network (GCNN) to pre-trained DNNs for classifying MedMNIST dataset classes, revealing promising prospects for GNNs in medical image analysis. Our results also encourage further exploration of advanced graph-based models such as Graph Attention Networks (GAT) and Graph Auto-Encoders in the medical imaging domain. The proposed model yields more reliable, interpretable, and accurate outcomes for tasks like semantic segmentation and image classification compared to simpler GCNNs