 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Birds Eye View Perception Models with Frozen Foundation Models: DINOv2 and Metric3Dv2
Jan 14, 2025



Birds Eye View perception models require extensive data to perform and generalize effectively. While traditional datasets often provide abundant driving scenes from diverse locations, this is not always the case. It is crucial to maximize the utility of the available training data. With the advent of large foundation models such as DINOv2 and Metric3Dv2, a pertinent question arises: can these models be integrated into existing model architectures to not only reduce the required training data but surpass the performance of current models? We choose two model architectures in the vehicle segmentation domain to alter: Lift-Splat-Shoot, and Simple-BEV. For Lift-Splat-Shoot, we explore the implementation of frozen DINOv2 for feature extraction and Metric3Dv2 for depth estimation, where we greatly exceed the baseline results by 7.4 IoU while utilizing only half the training data and iterations. Furthermore, we introduce an innovative application of Metric3Dv2's depth information as a PseudoLiDAR point cloud incorporated into the Simple-BEV architecture, replacing traditional LiDAR. This integration results in a +3 IoU improvement compared to the Camera-only model.
Velocity Driven Vision: Asynchronous Sensor Fusion Birds Eye View Models for Autonomous Vehicles
Jul 24, 2024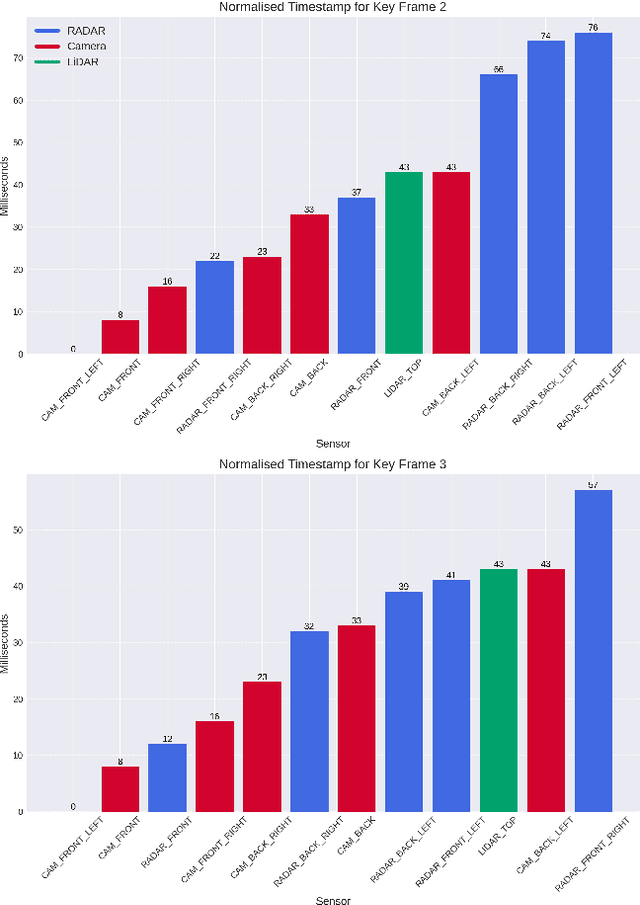
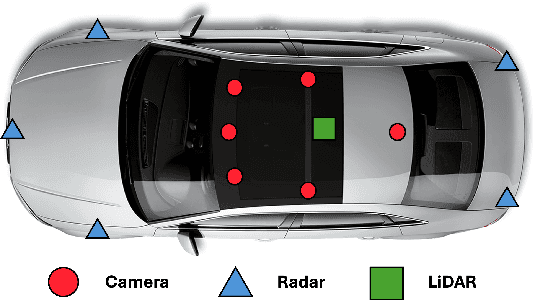
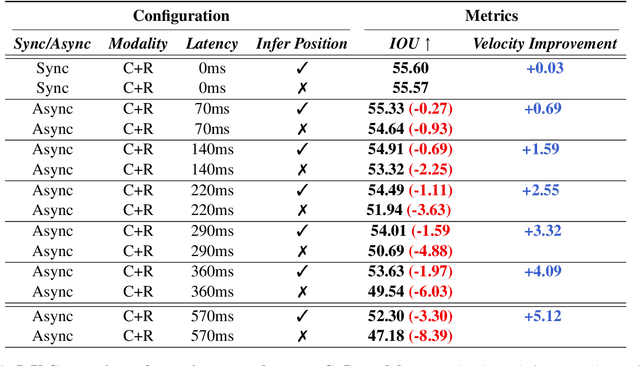
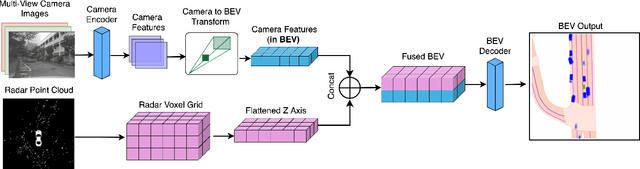
Fusing different sensor modalities can be a difficult task, particularly if they are asynchronous. Asynchronisation may arise due to long processing times or improper synchronisation during calibration, and there must exist a way to still utilise this previous information for the purpose of safe driving, and object detection in ego vehicle/ multi-agent trajectory prediction. Difficulties arise in the fact that the sensor modalities have captured information at different times and also at different positions in space. Therefore, they are not spatially nor temporally aligned. This paper will investigate the challenge of radar and LiDAR sensors being asynchronous relative to the camera sensors, for various time latencies. The spatial alignment will be resolved before lifting into BEV space via the transformation of the radar/LiDAR point clouds into the new ego frame coordinate system. Only after this can we concatenate the radar/LiDAR point cloud and lifted camera features. Temporal alignment will be remedied for radar data only, we will implement a novel method of inferring the future radar point positions using the velocity information. Our approach to resolving the issue of sensor asynchrony yields promising results. We demonstrate velocity information can drastically improve IoU for asynchronous datasets, as for a time latency of 360 milliseconds (ms), IoU improves from 49.54 to 53.63. Additionally, for a time latency of 550ms, the camera+radar (C+R) model outperforms the camera+LiDAR (C+L) model by 0.18 IoU. This is an advancement in utilising the often-neglected radar sensor modality, which is less favoured than LiDAR for autonomous driving purposes.