 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM3T: Multi-Scale Memory Matching for Video Object Segmentation and Tracking
Paper and Code
Dec 13, 2023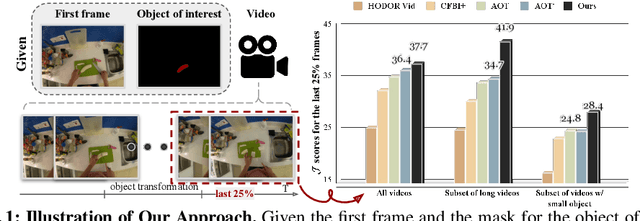

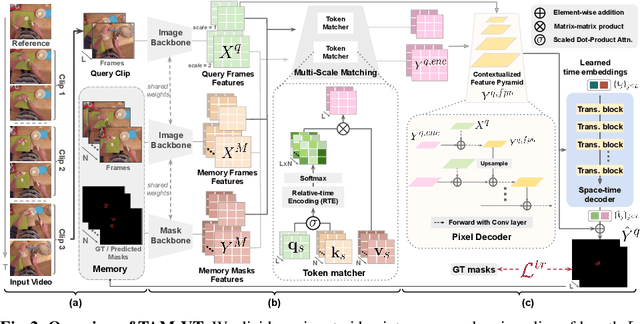
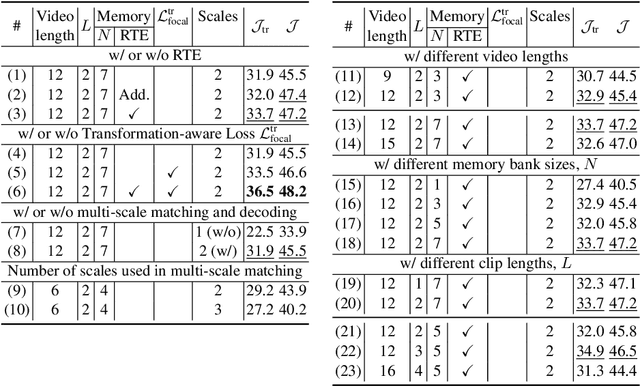
Video Object Segmentation (VOS) has became increasingly important with availability of larger datasets and more complex and realistic settings, which involve long videos with global motion (e.g, in egocentric settings), depicting small objects undergoing both rigid and non-rigid (including state) deformations. While a number of recent approaches have been explored for this task, these data characteristics still present challenges. In this work we propose a novel, DETR-style encoder-decoder architecture, which focuses on systematically analyzing and addressing aforementioned challenges. Specifically, our model enables on-line inference with long videos in a windowed fashion, by breaking the video into clips and propagating context among them using time-coded memory. We illustrate that short clip length and longer memory with learned time-coding are important design choices for achieving state-of-the-art (SoTA) performance. Further, we propose multi-scale matching and decoding to ensure sensitivity and accuracy for small objects. Finally, we propose a novel training strategy that focuses learning on portions of the video where an object undergoes significant deformations -- a form of "soft" hard-negative mining, implemented as loss-reweighting. Collectively, these technical contributions allow our model to achieve SoTA performance on two complex datasets -- VISOR and VOST. A series of detailed ablations validate our design choices as well as provide insights into the importance of parameter choices and their impact on performance.