 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeValue Vision-Language-Action Planning & Search
Jan 02, 2026Vision-Language-Action (VLA) models have emerged as powerful generalist policies for robotic manipulation, yet they remain fundamentally limited by their reliance on behavior cloning, leading to brittleness under distribution shift. While augmenting pretrained models with test-time search algorithms like Monte Carlo Tree Search (MCTS) can mitigate these failures, existing formulations rely solely on the VLA prior for guidance, lacking a grounded estimate of expected future return. Consequently, when the prior is inaccurate, the planner can only correct action selection via the exploration term, which requires extensive simulation to become effective. To address this limitation, we introduce Value Vision-Language-Action Planning and Search (V-VLAPS), a framework that augments MCTS with a lightweight, learnable value function. By training a simple multilayer perceptron (MLP) on the latent representations of a fixed VLA backbone (Octo), we provide the search with an explicit success signal that biases action selection toward high-value regions. We evaluate V-VLAPS on the LIBERO robotic manipulation suite, demonstrating that our value-guided search improves success rates by over 5 percentage points while reducing the average number of MCTS simulations by 5-15 percent compared to baselines that rely only on the VLA prior.
ChartGaze: Enhancing Chart Understanding in LVLMs with Eye-Tracking Guided Attention Refinement
Sep 16, 2025Charts are a crucial visual medium for communicating and representing information. While Large Vision-Language Models (LVLMs) have made progress on chart question answering (CQA), the task remains challenging, particularly when models attend to irrelevant regions of the chart. In this work, we present ChartGaze, a new eye-tracking dataset that captures human gaze patterns during chart reasoning tasks. Through a systematic comparison of human and model attention, we find that LVLMs often diverge from human gaze, leading to reduced interpretability and accuracy. To address this, we propose a gaze-guided attention refinement that aligns image-text attention with human fixations. Our approach improves both answer accuracy and attention alignment, yielding gains of up to 2.56 percentage points across multiple models. These results demonstrate the promise of incorporating human gaze to enhance both the reasoning quality and interpretability of chart-focused LVLMs.
Captioning Visualizations with Large Language Models (CVLLM): A Tutorial
Jun 27, 2024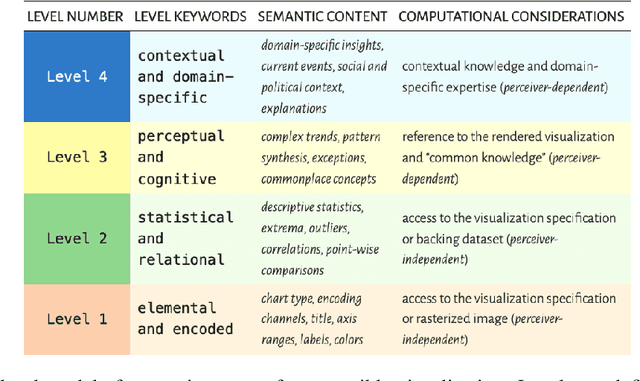
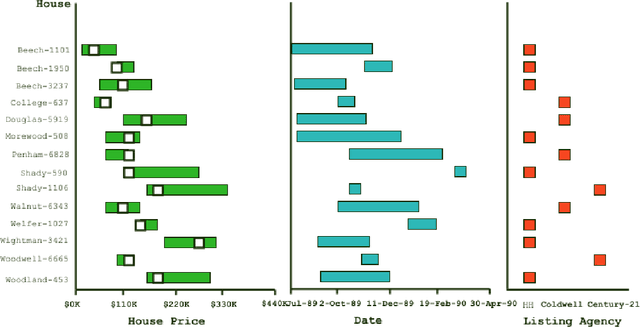
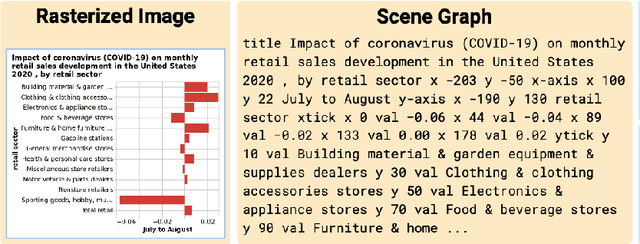
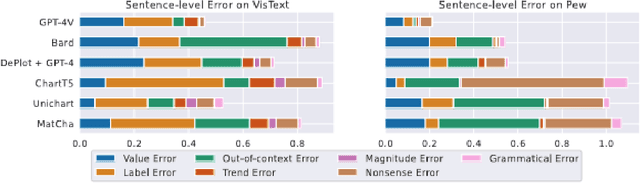
Automatically captioning visualizations is not new, but recent advances in large language models(LLMs) open exciting new possibilities. In this tutorial, after providing a brief review of Information Visualization (InfoVis) principles and past work in captioning, we introduce neural models and the transformer architecture used in generic LLMs. We then discuss their recent applications in InfoVis, with a focus on captioning. Additionally, we explore promising future directions in this field.