 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenEarthMap-SAR: A Benchmark Synthetic Aperture Radar Dataset for Global High-Resolution Land Cover Mapping
Jan 18, 2025



High-resolution land cover mapping plays a crucial role in addressing a wide range of global challenges, including urban planning, environmental monitoring, disaster response, and sustainable development. However, creating accurate, large-scale land cover datasets remains a significant challenge due to the inherent complexities of geospatial data, such as diverse terrain, varying sensor modalities, and atmospheric conditions. Synthetic Aperture Radar (SAR) imagery, with its ability to penetrate clouds and capture data in all-weather, day-and-night conditions, offers unique advantages for land cover mapping. Despite these strengths, the lack of benchmark datasets tailored for SAR imagery has limited the development of robust models specifically designed for this data modality. To bridge this gap and facilitate advancements in SAR-based geospatial analysis, we introduce OpenEarthMap-SAR, a benchmark SAR dataset, for global high-resolution land cover mapping. OpenEarthMap-SAR consists of 1.5 million segments of 5033 aerial and satellite images with the size of 1024$\times$1024 pixels, covering 35 regions from Japan, France, and the USA, with partially manually annotated and fully pseudo 8-class land cover labels at a ground sampling distance of 0.15--0.5 m. We evaluated the performance of state-of-the-art methods for semantic segmentation and present challenging problem settings suitable for further technical development. The dataset also serves the official dataset for IEEE GRSS Data Fusion Contest Track I. The dataset has been made publicly available at https://zenodo.org/records/14622048.
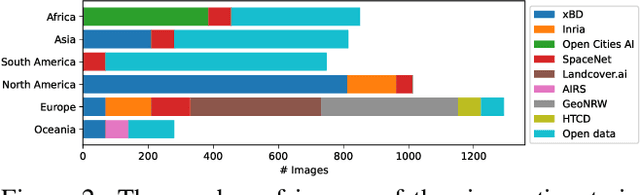
BRIGHT: A globally distributed multimodal building damage assessment dataset with very-high-resolution for all-weather disaster response
Jan 10, 2025



Disaster events occur around the world and cause significant damage to human life and property. Earth observation (EO) data enables rapid and comprehensive building damage assessment (BDA), an essential capability in the aftermath of a disaster to reduce human casualties and to inform disaster relief efforts. Recent research focuses on the development of AI models to achieve accurate mapping of unseen disaster events, mostly using optical EO data. However, solutions based on optical data are limited to clear skies and daylight hours, preventing a prompt response to disasters. Integrating multimodal (MM) EO data, particularly the combination of optical and SAR imagery, makes it possible to provide all-weather, day-and-night disaster responses. Despite this potential, the development of robust multimodal AI models has been constrained by the lack of suitable benchmark datasets. In this paper, we present a BDA dataset using veRy-hIGH-resoluTion optical and SAR imagery (BRIGHT) to support AI-based all-weather disaster response. To the best of our knowledge, BRIGHT is the first open-access, globally distributed, event-diverse MM dataset specifically curated to support AI-based disaster response. It covers five types of natural disasters and two types of man-made disasters across 12 regions worldwide, with a particular focus on developing countries where external assistance is most needed. The optical and SAR imagery in BRIGHT, with a spatial resolution between 0.3-1 meters, provides detailed representations of individual buildings, making it ideal for precise BDA. In our experiments, we have tested seven advanced AI models trained with our BRIGHT to validate the transferability and robustness. The dataset and code are available at https://github.com/ChenHongruixuan/BRIGHT. BRIGHT also serves as the official dataset for the 2025 IEEE GRSS Data Fusion Contest.
Generalized Few-Shot Semantic Segmentation in Remote Sensing: Challenge and Benchmark
Sep 17, 2024



Learning with limited labelled data is a challenging problem in various applications, including remote sensing. Few-shot semantic segmentation is one approach that can encourage deep learning models to learn from few labelled examples for novel classes not seen during the training. The generalized few-shot segmentation setting has an additional challenge which encourages models not only to adapt to the novel classes but also to maintain strong performance on the training base classes. While previous datasets and benchmarks discussed the few-shot segmentation setting in remote sensing, we are the first to propose a generalized few-shot segmentation benchmark for remote sensing. The generalized setting is more realistic and challenging, which necessitates exploring it within the remote sensing context. We release the dataset augmenting OpenEarthMap with additional classes labelled for the generalized few-shot evaluation setting. The dataset is released during the OpenEarthMap land cover mapping generalized few-shot challenge in the L3D-IVU workshop in conjunction with CVPR 2024. In this work, we summarize the dataset and challenge details in addition to providing the benchmark results on the two phases of the challenge for the validation and test sets.
Unsupervised Domain Adaptation Architecture Search with Self-Training for Land Cover Mapping
Apr 23, 2024Unsupervised domain adaptation (UDA) is a challenging open problem in land cover mapping. Previous studies show encouraging progress in addressing cross-domain distribution shifts on remote sensing benchmarks for land cover mapping. The existing works are mainly built on large neural network architectures, which makes them resource-hungry systems, limiting their practical impact for many real-world applications in resource-constrained environments. Thus, we proposed a simple yet effective framework to search for lightweight neural networks automatically for land cover mapping tasks under domain shifts. This is achieved by integrating Markov random field neural architecture search (MRF-NAS) into a self-training UDA framework to search for efficient and effective networks under a limited computation budget. This is the first attempt to combine NAS with self-training UDA as a single framework for land cover mapping. We also investigate two different pseudo-labelling approaches (confidence-based and energy-based) in self-training scheme. Experimental results on two recent datasets (OpenEarthMap & FLAIR #1) for remote sensing UDA demonstrate a satisfactory performance. With only less than 2M parameters and 30.16 GFLOPs, the best-discovered lightweight network reaches state-of-the-art performance on the regional target domain of OpenEarthMap (59.38% mIoU) and the considered target domain of FLAIR #1 (51.19% mIoU). The code is at https://github.com/cliffbb/UDA-NAS}{https://github.com/cliffbb/UDA-NAS.
A Survey on African Computer Vision Datasets, Topics and Researchers
Feb 04, 2024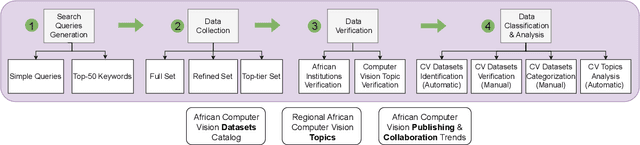


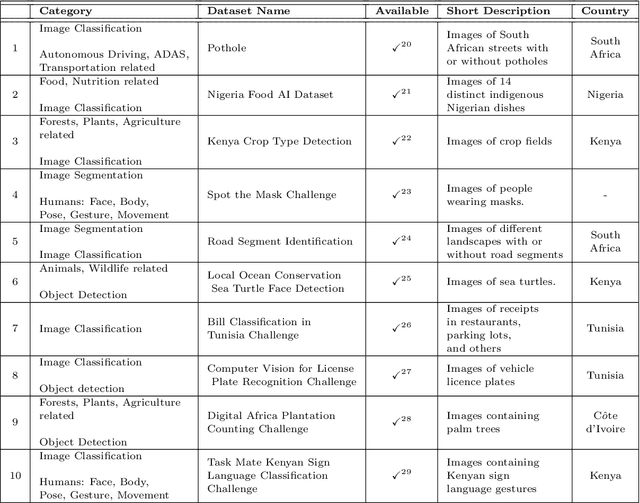
Computer vision encompasses a range of tasks such as object detection, semantic segmentation, and 3D reconstruction. Despite its relevance to African communities, research in this field within Africa represents only 0.06% of top-tier publications over the past decade. This study undertakes a thorough analysis of 63,000 Scopus-indexed computer vision publications from Africa, spanning from 2012 to 2022. The aim is to provide a survey of African computer vision topics, datasets and researchers. A key aspect of our study is the identification and categorization of African Computer Vision datasets using large language models that automatically parse abstracts of these publications. We also provide a compilation of unofficial African Computer Vision datasets distributed through challenges or data hosting platforms, and provide a full taxonomy of dataset categories. Our survey also pinpoints computer vision topics trends specific to different African regions, indicating their unique focus areas. Additionally, we carried out an extensive survey to capture the views of African researchers on the current state of computer vision research in the continent and the structural barriers they believe need urgent attention. In conclusion, this study catalogs and categorizes Computer Vision datasets and topics contributed or initiated by African institutions and identifies barriers to publishing in top-tier Computer Vision venues. This survey underscores the importance of encouraging African researchers and institutions in advancing computer vision research in the continent. It also stresses on the need for research topics to be more aligned with the needs of African communities.
Submeter-level Land Cover Mapping of Japan
Nov 19, 2023



Deep learning has shown promising performance in submeter-level mapping tasks; however, the annotation cost of submeter-level imagery remains a challenge, especially when applied on a large scale. In this paper, we present the first submeter-level land cover mapping of Japan with eight classes, at a relatively low annotation cost. We introduce a human-in-the-loop deep learning framework leveraging OpenEarthMap, a recently introduced benchmark dataset for global submeter-level land cover mapping, with a U-Net model that achieves national-scale mapping with a small amount of additional labeled data. By adding a small amount of labeled data of areas or regions where a U-Net model trained on OpenEarthMap clearly failed and retraining the model, an overall accuracy of 80\% was achieved, which is a nearly 16 percentage point improvement after retraining. Using aerial imagery provided by the Geospatial Information Authority of Japan, we create land cover classification maps of eight classes for the entire country of Japan. Our framework, with its low annotation cost and high-accuracy mapping results, demonstrates the potential to contribute to the automatic updating of national-scale land cover mapping using submeter-level optical remote sensing data. The mapping results will be made publicly available.
Land-cover change detection using paired OpenStreetMap data and optical high-resolution imagery via object-guided Transformer
Oct 04, 2023



Optical high-resolution imagery and OpenStreetMap (OSM) data are two important data sources for land-cover change detection. Previous studies in these two data sources focus on utilizing the information in OSM data to aid the change detection on multi-temporal optical high-resolution images. This paper pioneers the direct detection of land-cover changes utilizing paired OSM data and optical imagery, thereby broadening the horizons of change detection tasks to encompass more dynamic earth observations. To this end, we propose an object-guided Transformer (ObjFormer) architecture by naturally combining the prevalent object-based image analysis (OBIA) technique with the advanced vision Transformer architecture. The introduction of OBIA can significantly reduce the computational overhead and memory burden in the self-attention module. Specifically, the proposed ObjFormer has a hierarchical pseudo-siamese encoder consisting of object-guided self-attention modules that extract representative features of different levels from OSM data and optical images; a decoder consisting of object-guided cross-attention modules can progressively recover the land-cover changes from the extracted heterogeneous features. In addition to the basic supervised binary change detection task, this paper raises a new semi-supervised semantic change detection task that does not require any manually annotated land-cover labels of optical images to train semantic change detectors. Two lightweight semantic decoders are added to ObjFormer to accomplish this task efficiently. A converse cross-entropy loss is designed to fully utilize the negative samples, thereby contributing to the great performance improvement in this task. The first large-scale benchmark dataset containing 1,287 map-image pairs (1024$\times$ 1024 pixels for each sample) covering 40 regions on six continents ...(see the manuscript for the full abstract)
Real-Time Semantic Segmentation: A Brief Survey & Comparative Study in Remote Sensing
Sep 12, 2023
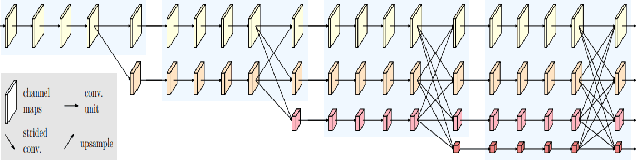


Real-time semantic segmentation of remote sensing imagery is a challenging task that requires a trade-off between effectiveness and efficiency. It has many applications including tracking forest fires, detecting changes in land use and land cover, crop health monitoring, and so on. With the success of efficient deep learning methods (i.e., efficient deep neural networks) for real-time semantic segmentation in computer vision, researchers have adopted these efficient deep neural networks in remote sensing image analysis. This paper begins with a summary of the fundamental compression methods for designing efficient deep neural networks and provides a brief but comprehensive survey, outlining the recent developments in real-time semantic segmentation of remote sensing imagery. We examine several seminal efficient deep learning methods, placing them in a taxonomy based on the network architecture design approach. Furthermore, we evaluate the quality and efficiency of some existing efficient deep neural networks on a publicly available remote sensing semantic segmentation benchmark dataset, the OpenEarthMap. The experimental results of an extensive comparative study demonstrate that most of the existing efficient deep neural networks have good segmentation quality, but they suffer low inference speed (i.e., high latency rate), which may limit their capability of deployment in real-time applications of remote sensing image segmentation. We provide some insights into the current trend and future research directions for real-time semantic segmentation of remote sensing imagery.
OpenEarthMap: A Benchmark Dataset for Global High-Resolution Land Cover Mapping
Oct 19, 2022
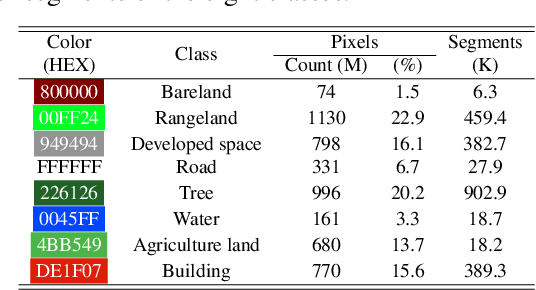

We introduce OpenEarthMap, a benchmark dataset, for global high-resolution land cover mapping. OpenEarthMap consists of 2.2 million segments of 5000 aerial and satellite images covering 97 regions from 44 countries across 6 continents, with manually annotated 8-class land cover labels at a 0.25--0.5m ground sampling distance. Semantic segmentation models trained on the OpenEarthMap generalize worldwide and can be used as off-the-shelf models in a variety of applications. We evaluate the performance of state-of-the-art methods for unsupervised domain adaptation and present challenging problem settings suitable for further technical development. We also investigate lightweight models using automated neural architecture search for limited computational resources and fast mapping. The dataset is available at https://open-earth-map.org.
Evolutionary NAS with Gene Expression Programming of Cellular Encoding
May 27, 2020



The renaissance of neural architecture search (NAS) has seen classical methods such as genetic algorithms (GA) and genetic programming (GP) being exploited for convolutional neural network (CNN) architectures. While recent work have achieved promising performance on visual perception tasks, the direct encoding scheme of both GA and GP has functional complexity deficiency and does not scale well on large architectures like CNN. To address this, we present a new generative encoding scheme -- $symbolic\ linear\ generative\ encoding$ (SLGE) -- simple, yet powerful scheme which embeds local graph transformations in chromosomes of linear fixed-length string to develop CNN architectures of variant shapes and sizes via evolutionary process of gene expression programming. In experiments, the effectiveness of SLGE is shown in discovering architectures that improve the performance of the state-of-the-art handcrafted CNN architectures on CIFAR-10 and CIFAR-100 image classification tasks; and achieves a competitive classification error rate with the existing NAS methods using less GPU resources.