 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMM-OVSeg:Multimodal Optical-SAR Fusion for Open-Vocabulary Segmentation in Remote Sensing
Mar 18, 2026Open-vocabulary segmentation enables pixel-level recognition from an open set of textual categories, allowing generalization beyond fixed classes. Despite great potential in remote sensing, progress in this area remains largely limited to clear-sky optical data and struggles under cloudy or haze-contaminated conditions. We present MM-OVSeg, a multimodal Optical-SAR fusion framework for resilient open-vocabulary segmentation under adverse weather conditions. MM-OVSeg leverages the complementary strengths of the two modalities--optical imagery provides rich spectral semantics, while synthetic aperture radar (SAR) offers cloud-penetrating structural cues. To address the cross-modal domain gap and the limited dense prediction capability of current vision-language models, we propose two key designs: a cross-modal unification process for multi-sensor representation alignment, and a dual-encoder fusion module that integrates hierarchical features from multiple vision foundation models for text-aligned multimodal segmentation. Extensive experiments demonstrate that MM-OVSeg achieves superior robustness and generalization across diverse cloud conditions. The source dataset and code are available here.
sparseGeoHOPCA: A Geometric Solution to Sparse Higher-Order PCA Without Covariance Estimation
Jun 10, 2025We propose sparseGeoHOPCA, a novel framework for sparse higher-order principal component analysis (SHOPCA) that introduces a geometric perspective to high-dimensional tensor decomposition. By unfolding the input tensor along each mode and reformulating the resulting subproblems as structured binary linear optimization problems, our method transforms the original nonconvex sparse objective into a tractable geometric form. This eliminates the need for explicit covariance estimation and iterative deflation, enabling significant gains in both computational efficiency and interpretability, particularly in high-dimensional and unbalanced data scenarios. We theoretically establish the equivalence between the geometric subproblems and the original SHOPCA formulation, and derive worst-case approximation error bounds based on classical PCA residuals, providing data-dependent performance guarantees. The proposed algorithm achieves a total computational complexity of $O\left(\sum_{n=1}^{N} (k_n^3 + J_n k_n^2)\right)$, which scales linearly with tensor size. Extensive experiments demonstrate that sparseGeoHOPCA accurately recovers sparse supports in synthetic settings, preserves classification performance under 10$\times$ compression, and achieves high-quality image reconstruction on ImageNet, highlighting its robustness and versatility.
SARLANG-1M: A Benchmark for Vision-Language Modeling in SAR Image Understanding
Apr 04, 2025
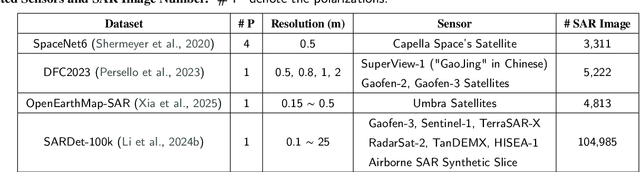

Synthetic Aperture Radar (SAR) is a crucial remote sensing technology, enabling all-weather, day-and-night observation with strong surface penetration for precise and continuous environmental monitoring and analysis. However, SAR image interpretation remains challenging due to its complex physical imaging mechanisms and significant visual disparities from human perception. Recently, Vision-Language Models (VLMs) have demonstrated remarkable success in RGB image understanding, offering powerful open-vocabulary interpretation and flexible language interaction. However, their application to SAR images is severely constrained by the absence of SAR-specific knowledge in their training distributions, leading to suboptimal performance. To address this limitation, we introduce SARLANG-1M, a large-scale benchmark tailored for multimodal SAR image understanding, with a primary focus on integrating SAR with textual modality. SARLANG-1M comprises more than 1 million high-quality SAR image-text pairs collected from over 59 cities worldwide. It features hierarchical resolutions (ranging from 0.1 to 25 meters), fine-grained semantic descriptions (including both concise and detailed captions), diverse remote sensing categories (1,696 object types and 16 land cover classes), and multi-task question-answering pairs spanning seven applications and 1,012 question types. Extensive experiments on mainstream VLMs demonstrate that fine-tuning with SARLANG-1M significantly enhances their performance in SAR image interpretation, reaching performance comparable to human experts. The dataset and code will be made publicly available at https://github.com/Jimmyxichen/SARLANG-1M.
OpenEarthMap-SAR: A Benchmark Synthetic Aperture Radar Dataset for Global High-Resolution Land Cover Mapping
Jan 18, 2025



High-resolution land cover mapping plays a crucial role in addressing a wide range of global challenges, including urban planning, environmental monitoring, disaster response, and sustainable development. However, creating accurate, large-scale land cover datasets remains a significant challenge due to the inherent complexities of geospatial data, such as diverse terrain, varying sensor modalities, and atmospheric conditions. Synthetic Aperture Radar (SAR) imagery, with its ability to penetrate clouds and capture data in all-weather, day-and-night conditions, offers unique advantages for land cover mapping. Despite these strengths, the lack of benchmark datasets tailored for SAR imagery has limited the development of robust models specifically designed for this data modality. To bridge this gap and facilitate advancements in SAR-based geospatial analysis, we introduce OpenEarthMap-SAR, a benchmark SAR dataset, for global high-resolution land cover mapping. OpenEarthMap-SAR consists of 1.5 million segments of 5033 aerial and satellite images with the size of 1024$\times$1024 pixels, covering 35 regions from Japan, France, and the USA, with partially manually annotated and fully pseudo 8-class land cover labels at a ground sampling distance of 0.15--0.5 m. We evaluated the performance of state-of-the-art methods for semantic segmentation and present challenging problem settings suitable for further technical development. The dataset also serves the official dataset for IEEE GRSS Data Fusion Contest Track I. The dataset has been made publicly available at https://zenodo.org/records/14622048.
BRIGHT: A globally distributed multimodal building damage assessment dataset with very-high-resolution for all-weather disaster response
Jan 10, 2025



Disaster events occur around the world and cause significant damage to human life and property. Earth observation (EO) data enables rapid and comprehensive building damage assessment (BDA), an essential capability in the aftermath of a disaster to reduce human casualties and to inform disaster relief efforts. Recent research focuses on the development of AI models to achieve accurate mapping of unseen disaster events, mostly using optical EO data. However, solutions based on optical data are limited to clear skies and daylight hours, preventing a prompt response to disasters. Integrating multimodal (MM) EO data, particularly the combination of optical and SAR imagery, makes it possible to provide all-weather, day-and-night disaster responses. Despite this potential, the development of robust multimodal AI models has been constrained by the lack of suitable benchmark datasets. In this paper, we present a BDA dataset using veRy-hIGH-resoluTion optical and SAR imagery (BRIGHT) to support AI-based all-weather disaster response. To the best of our knowledge, BRIGHT is the first open-access, globally distributed, event-diverse MM dataset specifically curated to support AI-based disaster response. It covers five types of natural disasters and two types of man-made disasters across 12 regions worldwide, with a particular focus on developing countries where external assistance is most needed. The optical and SAR imagery in BRIGHT, with a spatial resolution between 0.3-1 meters, provides detailed representations of individual buildings, making it ideal for precise BDA. In our experiments, we have tested seven advanced AI models trained with our BRIGHT to validate the transferability and robustness. The dataset and code are available at https://github.com/ChenHongruixuan/BRIGHT. BRIGHT also serves as the official dataset for the 2025 IEEE GRSS Data Fusion Contest.
Coseparable Nonnegative Tensor Factorization With T-CUR Decomposition
Jan 30, 2024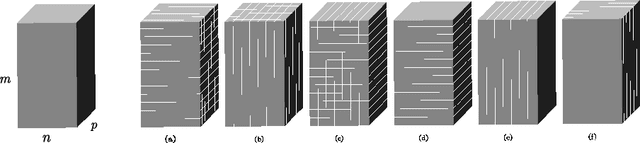
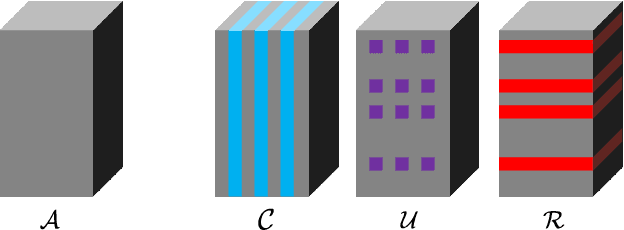
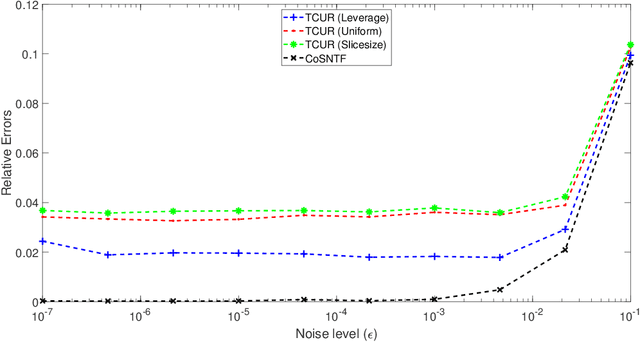
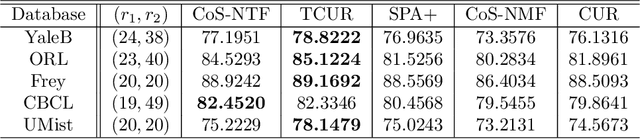
Nonnegative Matrix Factorization (NMF) is an important unsupervised learning method to extract meaningful features from data. To address the NMF problem within a polynomial time framework, researchers have introduced a separability assumption, which has recently evolved into the concept of coseparability. This advancement offers a more efficient core representation for the original data. However, in the real world, the data is more natural to be represented as a multi-dimensional array, such as images or videos. The NMF's application to high-dimensional data involves vectorization, which risks losing essential multi-dimensional correlations. To retain these inherent correlations in the data, we turn to tensors (multidimensional arrays) and leverage the tensor t-product. This approach extends the coseparable NMF to the tensor setting, creating what we term coseparable Nonnegative Tensor Factorization (NTF). In this work, we provide an alternating index selection method to select the coseparable core. Furthermore, we validate the t-CUR sampling theory and integrate it with the tensor Discrete Empirical Interpolation Method (t-DEIM) to introduce an alternative, randomized index selection process. These methods have been tested on both synthetic and facial analysis datasets. The results demonstrate the efficiency of coseparable NTF when compared to coseparable NMF.
Reinforcement Learning from Statistical Feedback: the Journey from AB Testing to ANT Testing
Nov 24, 2023Reinforcement Learning from Human Feedback (RLHF) has played a crucial role in the success of large models such as ChatGPT. RLHF is a reinforcement learning framework which combines human feedback to improve learning effectiveness and performance. However, obtaining preferences feedback manually is quite expensive in commercial applications. Some statistical commercial indicators are usually more valuable and always ignored in RLHF. There exists a gap between commercial target and model training. In our research, we will attempt to fill this gap with statistical business feedback instead of human feedback, using AB testing which is a well-established statistical method. Reinforcement Learning from Statistical Feedback (RLSF) based on AB testing is proposed. Statistical inference methods are used to obtain preferences for training the reward network, which fine-tunes the pre-trained model in reinforcement learning framework, achieving greater business value. Furthermore, we extend AB testing with double selections at a single time-point to ANT testing with multiple selections at different feedback time points. Moreover, we design numerical experiences to validate the effectiveness of our algorithm framework.
T-ADAF: Adaptive Data Augmentation Framework for Image Classification Network based on Tensor T-product Operator
Jun 07, 2023Image classification is one of the most fundamental tasks in Computer Vision. In practical applications, the datasets are usually not as abundant as those in the laboratory and simulation, which is always called as Data Hungry. How to extract the information of data more completely and effectively is very important. Therefore, an Adaptive Data Augmentation Framework based on the tensor T-product Operator is proposed in this paper, to triple one image data to be trained and gain the result from all these three images together with only less than 0.1% increase in the number of parameters. At the same time, this framework serves the functions of column image embedding and global feature intersection, enabling the model to obtain information in not only spatial but frequency domain, and thus improving the prediction accuracy of the model. Numerical experiments have been designed for several models, and the results demonstrate the effectiveness of this adaptive framework. Numerical experiments show that our data augmentation framework can improve the performance of original neural network model by 2%, which provides competitive results to state-of-the-art methods.
Spatial-Temporal Transformer for 3D Point Cloud Sequences
Oct 19, 2021Effective learning of spatial-temporal information within a point cloud sequence is highly important for many down-stream tasks such as 4D semantic segmentation and 3D action recognition. In this paper, we propose a novel framework named Point Spatial-Temporal Transformer (PST2) to learn spatial-temporal representations from dynamic 3D point cloud sequences. Our PST2 consists of two major modules: a Spatio-Temporal Self-Attention (STSA) module and a Resolution Embedding (RE) module. Our STSA module is introduced to capture the spatial-temporal context information across adjacent frames, while the RE module is proposed to aggregate features across neighbors to enhance the resolution of feature maps. We test the effectiveness our PST2 with two different tasks on point cloud sequences, i.e., 4D semantic segmentation and 3D action recognition. Extensive experiments on three benchmarks show that our PST2 outperforms existing methods on all datasets. The effectiveness of our STSA and RE modules have also been justified with ablation experiments.