 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Unlock Time Series Editing? Diffusion-Driven Approach with Multi-Grained Control
Jun 05, 2025Recent advances in time series generation have shown promise, yet controlling properties in generated sequences remains challenging. Time Series Editing (TSE) - making precise modifications while preserving temporal coherence - consider both point-level constraints and segment-level controls that current methods struggle to provide. We introduce the CocktailEdit framework to enable simultaneous, flexible control across different types of constraints. This framework combines two key mechanisms: a confidence-weighted anchor control for point-wise constraints and a classifier-based control for managing statistical properties such as sums and averages over segments. Our methods achieve precise local control during the denoising inference stage while maintaining temporal coherence and integrating seamlessly, with any conditionally trained diffusion-based time series models. Extensive experiments across diverse datasets and models demonstrate its effectiveness. Our work bridges the gap between pure generative modeling and real-world time series editing needs, offering a flexible solution for human-in-the-loop time series generation and editing. The code and demo are provided for validation.
ELABORATION: A Comprehensive Benchmark on Human-LLM Competitive Programming
May 22, 2025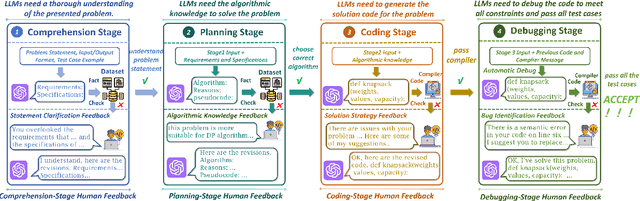
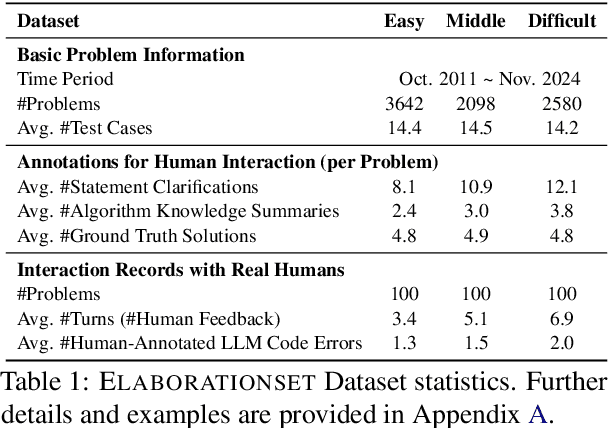

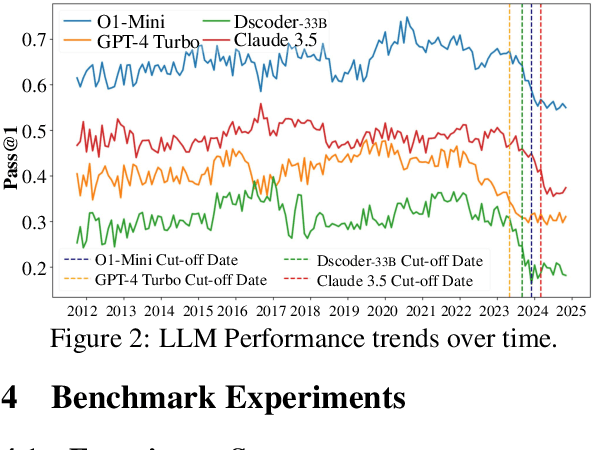
While recent research increasingly emphasizes the value of human-LLM collaboration in competitive programming and proposes numerous empirical methods, a comprehensive understanding remains elusive due to the fragmented nature of existing studies and their use of diverse, application-specific human feedback. Thus, our work serves a three-fold purpose: First, we present the first taxonomy of human feedback consolidating the entire programming process, which promotes fine-grained evaluation. Second, we introduce ELABORATIONSET, a novel programming dataset specifically designed for human-LLM collaboration, meticulously annotated to enable large-scale simulated human feedback and facilitate costeffective real human interaction studies. Third, we introduce ELABORATION, a novel benchmark to facilitate a thorough assessment of human-LLM competitive programming. With ELABORATION, we pinpoint strengthes and weaknesses of existing methods, thereby setting the foundation for future improvement. Our code and dataset are available at https://github.com/SCUNLP/ELABORATION
Evaluation of Retrieval-Augmented Generation: A Survey
May 13, 2024Retrieval-Augmented Generation (RAG) has emerged as a pivotal innovation in natural language processing, enhancing generative models by incorporating external information retrieval. Evaluating RAG systems, however, poses distinct challenges due to their hybrid structure and reliance on dynamic knowledge sources. We consequently enhanced an extensive survey and proposed an analysis framework for benchmarks of RAG systems, RAGR (Retrieval, Generation, Additional Requirement), designed to systematically analyze RAG benchmarks by focusing on measurable outputs and established truths. Specifically, we scrutinize and contrast multiple quantifiable metrics of the Retrieval and Generation component, such as relevance, accuracy, and faithfulness, of the internal links within the current RAG evaluation methods, covering the possible output and ground truth pairs. We also analyze the integration of additional requirements of different works, discuss the limitations of current benchmarks, and propose potential directions for further research to address these shortcomings and advance the field of RAG evaluation. In conclusion, this paper collates the challenges associated with RAG evaluation. It presents a thorough analysis and examination of existing methodologies for RAG benchmark design based on the proposed RGAR framework.
Reinforcement Learning from Statistical Feedback: the Journey from AB Testing to ANT Testing
Nov 24, 2023Reinforcement Learning from Human Feedback (RLHF) has played a crucial role in the success of large models such as ChatGPT. RLHF is a reinforcement learning framework which combines human feedback to improve learning effectiveness and performance. However, obtaining preferences feedback manually is quite expensive in commercial applications. Some statistical commercial indicators are usually more valuable and always ignored in RLHF. There exists a gap between commercial target and model training. In our research, we will attempt to fill this gap with statistical business feedback instead of human feedback, using AB testing which is a well-established statistical method. Reinforcement Learning from Statistical Feedback (RLSF) based on AB testing is proposed. Statistical inference methods are used to obtain preferences for training the reward network, which fine-tunes the pre-trained model in reinforcement learning framework, achieving greater business value. Furthermore, we extend AB testing with double selections at a single time-point to ANT testing with multiple selections at different feedback time points. Moreover, we design numerical experiences to validate the effectiveness of our algorithm framework.