 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSARLANG-1M: A Benchmark for Vision-Language Modeling in SAR Image Understanding
Apr 04, 2025
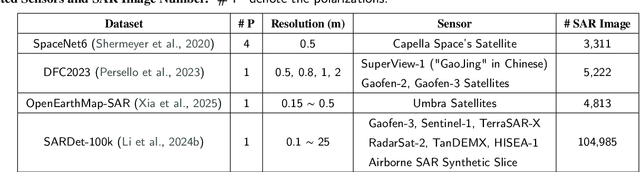

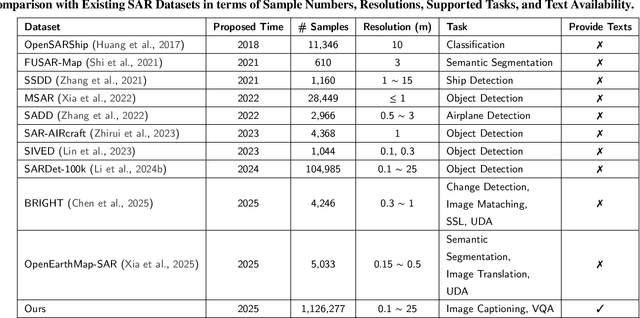
Synthetic Aperture Radar (SAR) is a crucial remote sensing technology, enabling all-weather, day-and-night observation with strong surface penetration for precise and continuous environmental monitoring and analysis. However, SAR image interpretation remains challenging due to its complex physical imaging mechanisms and significant visual disparities from human perception. Recently, Vision-Language Models (VLMs) have demonstrated remarkable success in RGB image understanding, offering powerful open-vocabulary interpretation and flexible language interaction. However, their application to SAR images is severely constrained by the absence of SAR-specific knowledge in their training distributions, leading to suboptimal performance. To address this limitation, we introduce SARLANG-1M, a large-scale benchmark tailored for multimodal SAR image understanding, with a primary focus on integrating SAR with textual modality. SARLANG-1M comprises more than 1 million high-quality SAR image-text pairs collected from over 59 cities worldwide. It features hierarchical resolutions (ranging from 0.1 to 25 meters), fine-grained semantic descriptions (including both concise and detailed captions), diverse remote sensing categories (1,696 object types and 16 land cover classes), and multi-task question-answering pairs spanning seven applications and 1,012 question types. Extensive experiments on mainstream VLMs demonstrate that fine-tuning with SARLANG-1M significantly enhances their performance in SAR image interpretation, reaching performance comparable to human experts. The dataset and code will be made publicly available at https://github.com/Jimmyxichen/SARLANG-1M.
Self-supervised Noise2noise Method Utilizing Corrupted Images with a Modular Network for LDCT Denoising
Aug 13, 2023Deep learning is a very promising technique for low-dose computed tomography (LDCT) image denoising. However, traditional deep learning methods require paired noisy and clean datasets, which are often difficult to obtain. This paper proposes a new method for performing LDCT image denoising with only LDCT data, which means that normal-dose CT (NDCT) is not needed. We adopt a combination including the self-supervised noise2noise model and the noisy-as-clean strategy. First, we add a second yet similar type of noise to LDCT images multiple times. Note that we use LDCT images based on the noisy-as-clean strategy for corruption instead of NDCT images. Then, the noise2noise model is executed with only the secondary corrupted images for training. We select a modular U-Net structure from several candidates with shared parameters to perform the task, which increases the receptive field without increasing the parameter size. The experimental results obtained on the Mayo LDCT dataset show the effectiveness of the proposed method compared with that of state-of-the-art deep learning methods. The developed code is available at https://github.com/XYuan01/Self-supervised-Noise2Noise-for-LDCT.