 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNormalized Orthography for Tunisian Arabic
Feb 20, 2024


Tunisian Arabic (ISO 693-3: aeb) is a distinct linguistic variety native to Tunisia, initially stemmed from the Arabic language and enriched by a multitude of historical influences. This research introduces the "Normalized Orthography for Tunisian Arabic" (NOTA), an adaptation of CODA* guidelines tailored for transcribing Tunisian Arabic using the Arabic script for language resource development purposes, with an emphasis on user-friendliness and consistency. The updated standard seeks to address challenges related to accurately representing the unique characteristics of Tunisian phonology and morphology. This will be achieved by rectifying problems arising from transcriptions based on resemblances to Modern Standard Arabic.
Text Categorization Can Enhance Domain-Agnostic Stopword Extraction
Jan 24, 2024This paper investigates the role of text categorization in streamlining stopword extraction in natural language processing (NLP), specifically focusing on nine African languages alongside French. By leveraging the MasakhaNEWS, African Stopwords Project, and MasakhaPOS datasets, our findings emphasize that text categorization effectively identifies domain-agnostic stopwords with over 80% detection success rate for most examined languages. Nevertheless, linguistic variances result in lower detection rates for certain languages. Interestingly, we find that while over 40% of stopwords are common across news categories, less than 15% are unique to a single category. Uncommon stopwords add depth to text but their classification as stopwords depends on context. Therefore combining statistical and linguistic approaches creates comprehensive stopword lists, highlighting the value of our hybrid method. This research enhances NLP for African languages and underscores the importance of text categorization in stopword extraction.
A Decade of Scholarly Research on Open Knowledge Graphs
Jun 22, 2023The proliferation of open knowledge graphs has led to a surge in scholarly research on the topic over the past decade. This paper presents a bibliometric analysis of the scholarly literature on open knowledge graphs published between 2013 and 2023. The study aims to identify the trends, patterns, and impact of research in this field, as well as the key topics and research questions that have emerged. The work uses bibliometric techniques to analyze a sample of 4445 scholarly articles retrieved from Scopus. The findings reveal an ever-increasing number of publications on open knowledge graphs published every year, particularly in developed countries (+50 per year). These outputs are published in highly-referred scholarly journals and conferences. The study identifies three main research themes: (1) knowledge graph construction and enrichment, (2) evaluation and reuse, and (3) fusion of knowledge graphs into NLP systems. Within these themes, the study identifies specific tasks that have received considerable attention, including entity linking, knowledge graph embedding, and graph neural networks.
Network representation learning systematic review: ancestors and current development state
Sep 14, 2021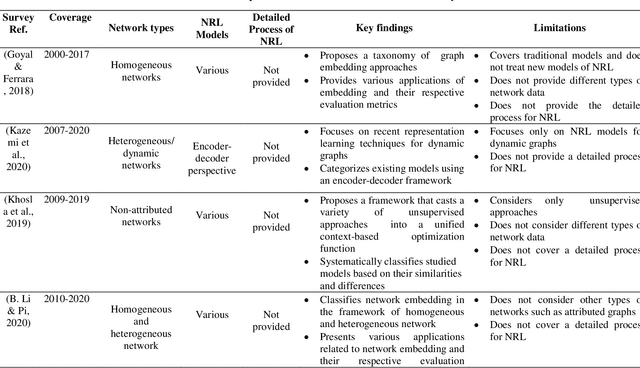
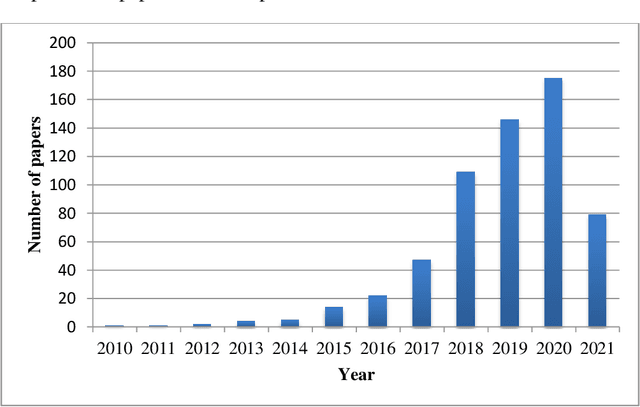

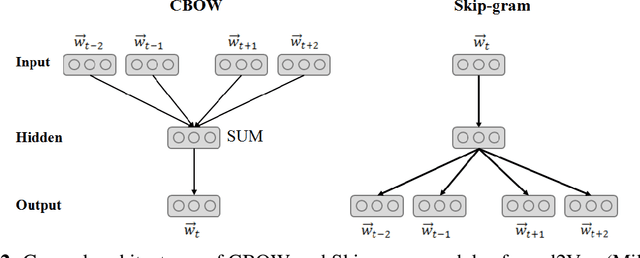
Real-world information networks are increasingly occurring across various disciplines including online social networks and citation networks. These network data are generally characterized by sparseness, nonlinearity and heterogeneity bringing different challenges to the network analytics task to capture inherent properties from network data. Artificial intelligence and machine learning have been recently leveraged as powerful systems to learn insights from network data and deal with presented challenges. As part of machine learning techniques, graph embedding approaches are originally conceived for graphs constructed from feature represented datasets, like image dataset, in which links between nodes are explicitly defined. These traditional approaches cannot cope with network data challenges. As a new learning paradigm, network representation learning has been proposed to map a real-world information network into a low-dimensional space while preserving inherent properties of the network. In this paper, we present a systematic comprehensive survey of network representation learning, known also as network embedding, from birth to the current development state. Through the undertaken survey, we provide a comprehensive view of reasons behind the emergence of network embedding and, types of settings and models used in the network embedding pipeline. Thus, we introduce a brief history of representation learning and word representation learning ancestor of network embedding. We provide also formal definitions of basic concepts required to understand network representation learning followed by a description of network embedding pipeline. Most commonly used downstream tasks to evaluate embeddings, their evaluation metrics and popular datasets are highlighted. Finally, we present the open-source libraries for network embedding.
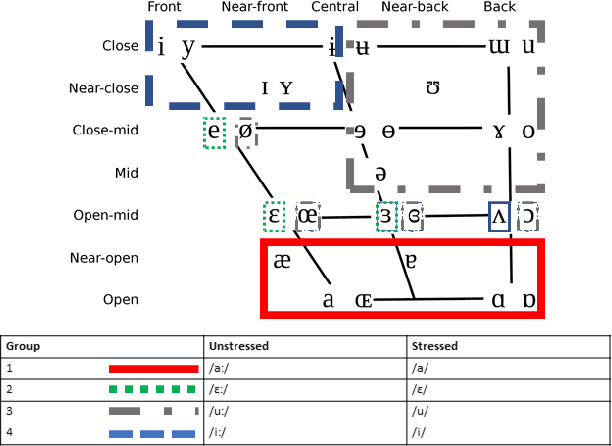
* 65 pages 11 Figures 6 Tables
Semantic similarity-based approach to enhance supervised classification learning accuracy
Oct 30, 2020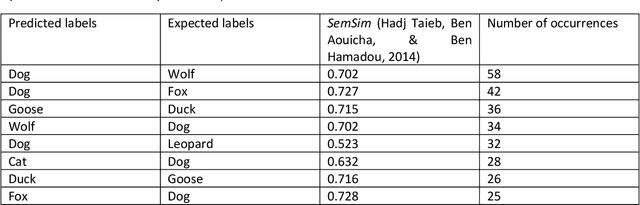
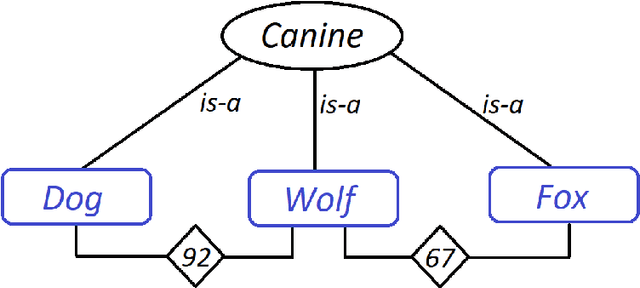
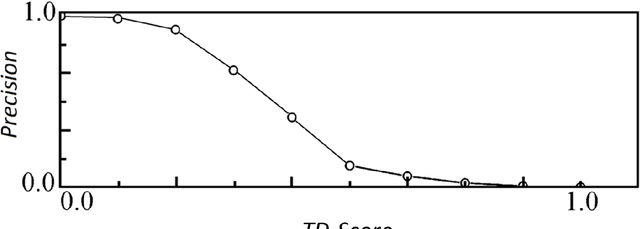
This brief communication discusses the usefulness of semantic similarity measures for the evaluation and amelioration of the accuracy of supervised classification learning. It proposes a semantic similarity-based method to enhance the choice of adequate labels for the classification algorithm as well as two metrics (SS-Score and TD-Score) and a curve (SA-Curve) that can be coupled to statistical evaluation measures of supervised classification learning to take into consideration the impact of the semantic aspect of the labels on the classification accuracy.