 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAfriNames: Most ASR models "butcher" African Names
Jun 02, 2023Useful conversational agents must accurately capture named entities to minimize error for downstream tasks, for example, asking a voice assistant to play a track from a certain artist, initiating navigation to a specific location, or documenting a laboratory result for a patient. However, where named entities such as ``Ukachukwu`` (Igbo), ``Lakicia`` (Swahili), or ``Ingabire`` (Rwandan) are spoken, automatic speech recognition (ASR) models' performance degrades significantly, propagating errors to downstream systems. We model this problem as a distribution shift and demonstrate that such model bias can be mitigated through multilingual pre-training, intelligent data augmentation strategies to increase the representation of African-named entities, and fine-tuning multilingual ASR models on multiple African accents. The resulting fine-tuned models show an 81.5\% relative WER improvement compared with the baseline on samples with African-named entities.
Ìtàkúròso: Exploiting Cross-Lingual Transferability for Natural Language Generation of Dialogues in Low-Resource, African Languages
Apr 17, 2022
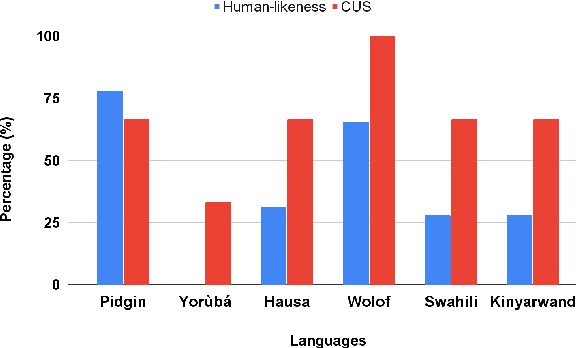
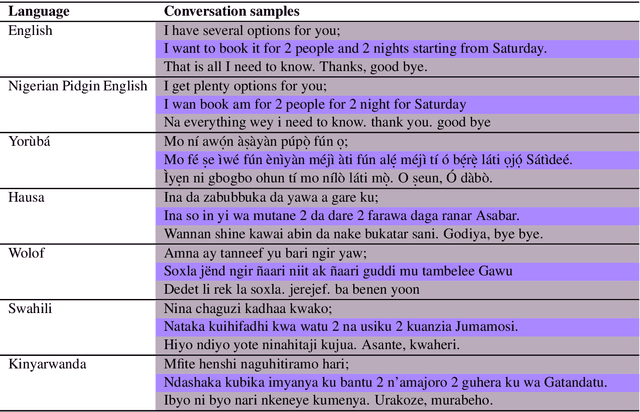
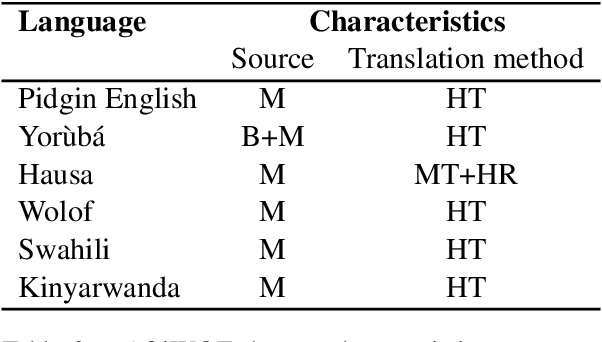
We investigate the possibility of cross-lingual transfer from a state-of-the-art (SoTA) deep monolingual model (DialoGPT) to 6 African languages and compare with 2 baselines (BlenderBot 90M, another SoTA, and a simple Seq2Seq). The languages are Swahili, Wolof, Hausa, Nigerian Pidgin English, Kinyarwanda & Yor\`ub\'a. Generation of dialogues is known to be a challenging task for many reasons. It becomes more challenging for African languages which are low-resource in terms of data. Therefore, we translate a small portion of the English multi-domain MultiWOZ dataset for each target language. Besides intrinsic evaluation (i.e. perplexity), we conduct human evaluation of single-turn conversations by using majority votes and measure inter-annotator agreement (IAA). The results show that the hypothesis that deep monolingual models learn some abstractions that generalise across languages holds. We observe human-like conversations in 5 out of the 6 languages. It, however, applies to different degrees in different languages, which is expected. The language with the most transferable properties is the Nigerian Pidgin English, with a human-likeness score of 78.1%, of which 34.4% are unanimous. The main contributions of this paper include the representation (through the provision of high-quality dialogue data) of under-represented African languages and demonstrating the cross-lingual transferability hypothesis for dialogue systems. We also provide the datasets and host the model checkpoints/demos on the HuggingFace hub for public access.