Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeÌròyìnSpeech: A multi-purpose Yorùbá Speech Corpus
Paper and Code
Jul 29, 2023
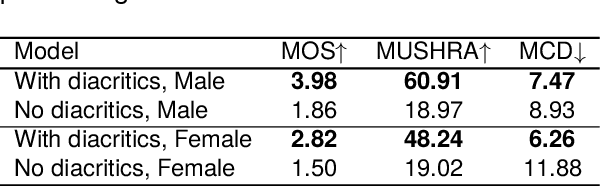
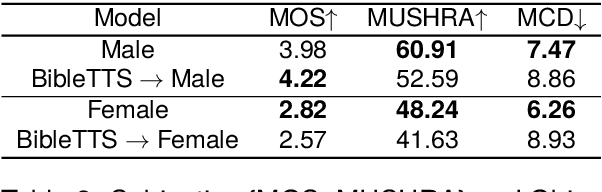
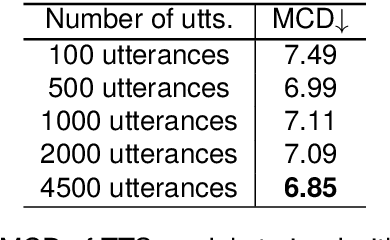
We introduce the \`{I}r\`{o}y\`{i}nSpeech corpus -- a new dataset influenced by a desire to increase the amount of high quality, freely available, contemporary Yor\`{u}b\'{a} speech. We release a multi-purpose dataset that can be used for both TTS and ASR tasks. We curated text sentences from the news and creative writing domains under an open license i.e., CC-BY-4.0 and had multiple speakers record each sentence. We provide 5000 of our utterances to the Common Voice platform to crowdsource transcriptions online. The dataset has 38.5 hours of data in total, recorded by 80 volunteers.
* working paper
View paper on