 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHEALTH-PARIKSHA: Assessing RAG Models for Health Chatbots in Real-World Multilingual Settings
Paper and Code
Oct 17, 2024
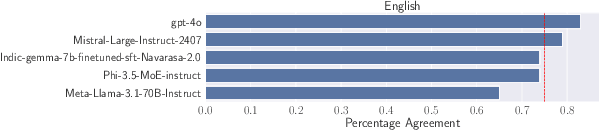
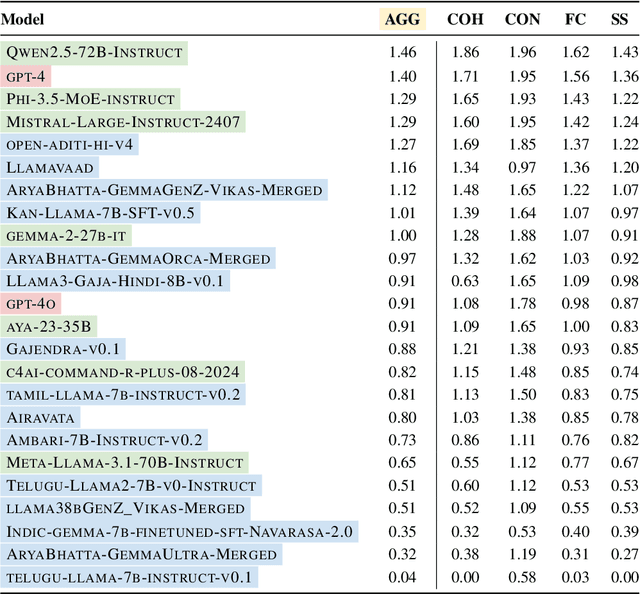
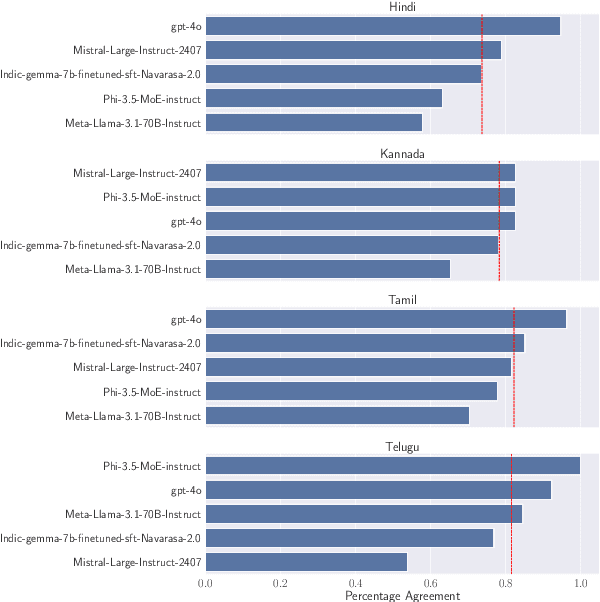
Assessing the capabilities and limitations of large language models (LLMs) has garnered significant interest, yet the evaluation of multiple models in real-world scenarios remains rare. Multilingual evaluation often relies on translated benchmarks, which typically do not capture linguistic and cultural nuances present in the source language. This study provides an extensive assessment of 24 LLMs on real world data collected from Indian patients interacting with a medical chatbot in Indian English and 4 other Indic languages. We employ a uniform Retrieval Augmented Generation framework to generate responses, which are evaluated using both automated techniques and human evaluators on four specific metrics relevant to our application. We find that models vary significantly in their performance and that instruction tuned Indic models do not always perform well on Indic language queries. Further, we empirically show that factual correctness is generally lower for responses to Indic queries compared to English queries. Finally, our qualitative work shows that code-mixed and culturally relevant queries in our dataset pose challenges to evaluated models.