 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Framework and Dataset for Assessing Gender Bias in Vision-Language Models
Feb 21, 2024
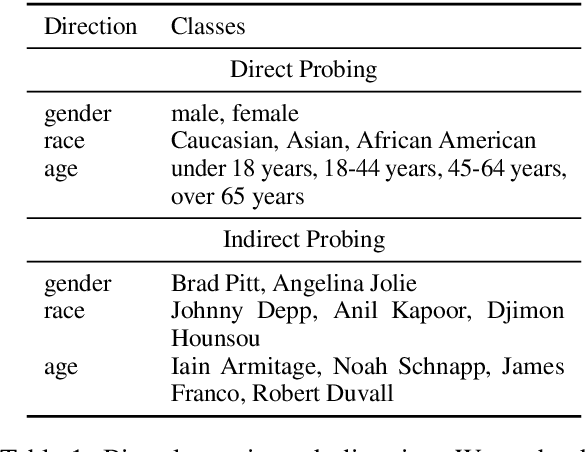


Large vision-language models (VLMs) are widely getting adopted in industry and academia. In this work we build a unified framework to systematically evaluate gender-profession bias in VLMs. Our evaluation encompasses all supported inference modes of the recent VLMs, including image-to-text, text-to-text, text-to-image, and image-to-image. We construct a synthetic, high-quality dataset of text and images that blurs gender distinctions across professional actions to benchmark gender bias. In our benchmarking of recent vision-language models (VLMs), we observe that different input-output modalities result in distinct bias magnitudes and directions. We hope our work will help guide future progress in improving VLMs to learn socially unbiased representations. We will release our data and code.
MAFIA: Multi-Adapter Fused Inclusive LanguAge Models
Feb 12, 2024



Pretrained Language Models (PLMs) are widely used in NLP for various tasks. Recent studies have identified various biases that such models exhibit and have proposed methods to correct these biases. However, most of the works address a limited set of bias dimensions independently such as gender, race, or religion. Moreover, the methods typically involve finetuning the full model to maintain the performance on the downstream task. In this work, we aim to modularly debias a pretrained language model across multiple dimensions. Previous works extensively explored debiasing PLMs using limited US-centric counterfactual data augmentation (CDA). We use structured knowledge and a large generative model to build a diverse CDA across multiple bias dimensions in a semi-automated way. We highlight how existing debiasing methods do not consider interactions between multiple societal biases and propose a debiasing model that exploits the synergy amongst various societal biases and enables multi-bias debiasing simultaneously. An extensive evaluation on multiple tasks and languages demonstrates the efficacy of our approach.
MEGAVERSE: Benchmarking Large Language Models Across Languages, Modalities, Models and Tasks
Nov 13, 2023Recently, there has been a rapid advancement in research on Large Language Models (LLMs), resulting in significant progress in several Natural Language Processing (NLP) tasks. Consequently, there has been a surge in LLM evaluation research to comprehend the models' capabilities and limitations. However, much of this research has been confined to the English language, leaving LLM building and evaluation for non-English languages relatively unexplored. There has been an introduction of several new LLMs, necessitating their evaluation on non-English languages. This study aims to expand our MEGA benchmarking suite by including six new datasets to form the MEGAVERSE benchmark. The benchmark comprises 22 datasets covering 81 languages, including low-resource African languages. We evaluate several state-of-the-art LLMs like GPT-3.5-Turbo, GPT4, PaLM2, and Llama2 on the MEGAVERSE datasets. Additionally, we include two multimodal datasets in the benchmark and assess the performance of the LLaVa-v1.5 model. Our experiments suggest that GPT4 and PaLM2 outperform the Llama models on various tasks, notably on low-resource languages, with GPT4 outperforming PaLM2 on more datasets than vice versa. However, issues such as data contamination must be addressed to obtain an accurate assessment of LLM performance on non-English languages.
MEGA: Multilingual Evaluation of Generative AI
Apr 03, 2023



Generative AI models have impressive performance on many Natural Language Processing tasks such as language understanding, reasoning and language generation. One of the most important questions that is being asked by the AI community today is about the capabilities and limits of these models, and it is clear that evaluating generative AI is very challenging. Most studies on generative Large Language Models (LLMs) are restricted to English and it is unclear how capable these models are at understanding and generating other languages. We present the first comprehensive benchmarking of generative LLMs - MEGA, which evaluates models on standard NLP benchmarks, covering 8 diverse tasks and 33 typologically diverse languages. We also compare the performance of generative LLMs to State of the Art (SOTA) non-autoregressive models on these tasks to determine how well generative models perform compared to the previous generation of LLMs. We present a thorough analysis of the performance of models across languages and discuss some of the reasons why generative LLMs are currently not optimal for all languages. We create a framework for evaluating generative LLMs in the multilingual setting and provide directions for future progress in the field.
Multilingual Knowledge Graph Completion with Joint Relation and Entity Alignment
Apr 18, 2021
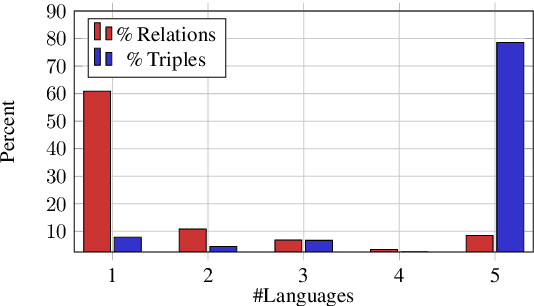


Knowledge Graph Completion (KGC) predicts missing facts in an incomplete Knowledge Graph. Almost all of existing KGC research is applicable to only one KG at a time, and in one language only. However, different language speakers may maintain separate KGs in their language and no individual KG is expected to be complete. Moreover, common entities or relations in these KGs have different surface forms and IDs, leading to ID proliferation. Entity alignment (EA) and relation alignment (RA) tasks resolve this by recognizing pairs of entity (relation) IDs in different KGs that represent the same entity (relation). This can further help prediction of missing facts, since knowledge from one KG is likely to benefit completion of another. High confidence predictions may also add valuable information for the alignment tasks. In response, we study the novel task of jointly training multilingual KGC, relation alignment and entity alignment models. We present ALIGNKGC, which uses some seed alignments to jointly optimize all three of KGC, EA and RA losses. A key component of ALIGNKGC is an embedding based soft notion of asymmetric overlap defined on the (subject, object) set signatures of relations this aids in better predicting relations that are equivalent to or implied by other relations. Extensive experiments with DBPedia in five languages establish the benefits of joint training for all tasks, achieving 10-32 MRR improvements of ALIGNKGC over a strong state-of-the-art single-KGC system completion model over each monolingual KG . Further, ALIGNKGC achieves reasonable gains in EA and RA tasks over a vanilla completion model over a KG that combines all facts without alignment, underscoring the value of joint training for these tasks.
Knowledge Base Completion: Baseline strikes back (Again)
May 02, 2020
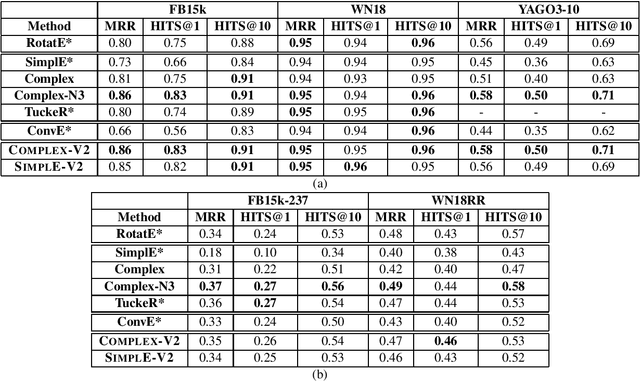
Knowledge Base Completion has been a very active area recently, where multiplicative models have generally outperformed additive and other deep learning methods -- like GNN, CNN, path-based models. Several recent KBC papers propose architectural changes, new training methods, or even a new problem reformulation. They evaluate their methods on standard benchmark datasets - FB15k, FB15k-237, WN18, WN18RR, and Yago3-10. Recently, some papers discussed how 1-N scoring can speed up training and evaluation. In this paper, we discuss how by just applying this training regime to a basic model like Complex gives near SOTA performance on all the datasets -- we call this model COMPLEX-V2. We also highlight how various multiplicative methods recently proposed in literature benefit from this trick and become indistinguishable in terms of performance on most datasets. This paper calls for a reassessment of their individual value, in light of these findings.
Temporal Knowledge Base Completion: New Algorithms and Evaluation Protocols
May 02, 2020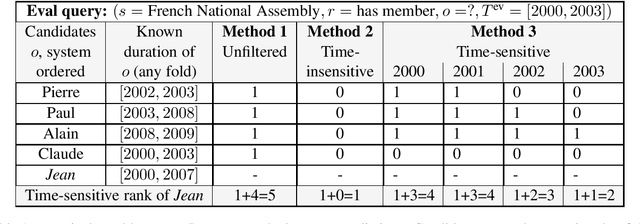
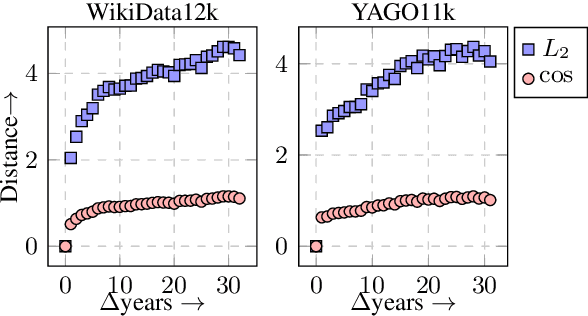
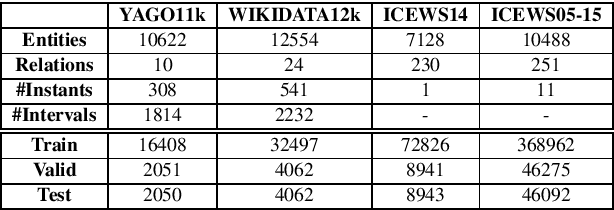
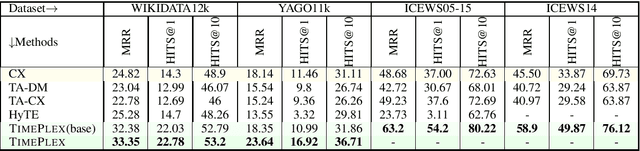
Temporal knowledge bases associate relational (s,r,o) triples with a set of times (or a single time instant) when the relation is valid. While time-agnostic KB completion (KBC) has witnessed significant research, temporal KB completion (TKBC) is in its early days. In this paper, we consider predicting missing entities (link prediction) and missing time intervals (time prediction) as joint TKBC tasks where entities, relations, and time are all embedded in a uniform, compatible space. We present TIMEPLEX, a novel time-aware KBC method, that also automatically exploits the recurrent nature of some relations and temporal interactions between pairs of relations. TIMEPLEX achieves state-of-the-art performance on both prediction tasks. We also find that existing TKBC models heavily overestimate link prediction performance due to imperfect evaluation mechanisms. In response, we propose improved TKBC evaluation protocols for both link and time prediction tasks, dealing with subtle issues that arise from the partial overlap of time intervals in gold instances and system predictions.
Joint Matrix-Tensor Factorization for Knowledge Base Inference
Jun 02, 2017
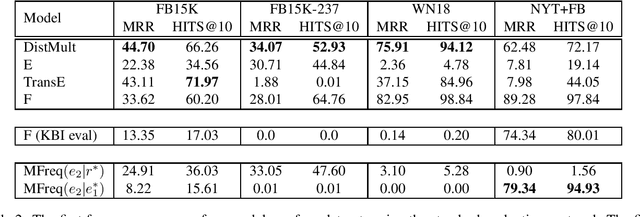


While several matrix factorization (MF) and tensor factorization (TF) models have been proposed for knowledge base (KB) inference, they have rarely been compared across various datasets. Is there a single model that performs well across datasets? If not, what characteristics of a dataset determine the performance of MF and TF models? Is there a joint TF+MF model that performs robustly on all datasets? We perform an extensive evaluation to compare popular KB inference models across popular datasets in the literature. In addition to answering the questions above, we remove a limitation in the standard evaluation protocol for MF models, propose an extension to MF models so that they can better handle out-of-vocabulary (OOV) entity pairs, and develop a novel combination of TF and MF models. We also analyze and explain the results based on models and dataset characteristics. Our best model is robust, and obtains strong results across all datasets.