 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRuddit: Norms of Offensiveness for English Reddit Comments
Paper and Code

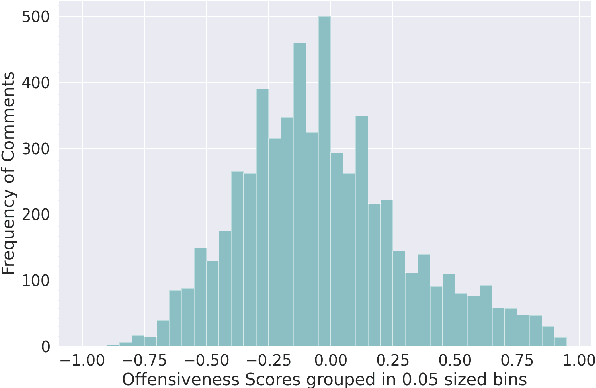

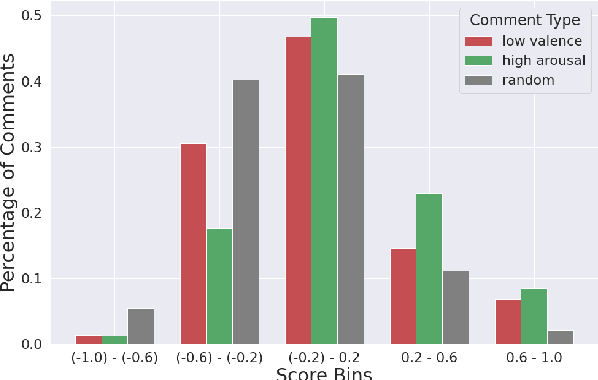
On social media platforms, hateful and offensive language negatively impact the mental well-being of users and the participation of people from diverse backgrounds. Automatic methods to detect offensive language have largely relied on datasets with categorical labels. However, comments can vary in their degree of offensiveness. We create the first dataset of English language Reddit comments that has fine-grained, real-valued scores between -1 (maximally supportive) and 1 (maximally offensive). The dataset was annotated using Best--Worst Scaling, a form of comparative annotation that has been shown to alleviate known biases of using rating scales. We show that the method produces highly reliable offensiveness scores. Finally, we evaluate the ability of widely-used neural models to predict offensiveness scores on this new dataset.