 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWho Wins the Race? (R Vs Python) - An Exploratory Study on Energy Consumption of Machine Learning Algorithms
Aug 24, 2025The utilization of Machine Learning (ML) in contemporary software systems is extensive and continually expanding. However, its usage is energy-intensive, contributing to increased carbon emissions and demanding significant resources. While numerous studies examine the performance and accuracy of ML, only a limited few focus on its environmental aspects, particularly energy consumption. In addition, despite emerging efforts to compare energy consumption across various programming languages for specific algorithms and tasks, there remains a gap specifically in comparing these languages for ML-based tasks. This paper aims to raise awareness of the energy costs associated with employing different programming languages for ML model training and inference. Through this empirical study, we measure and compare the energy consumption along with run-time performance of five regression and five classification tasks implemented in Python and R, the two most popular programming languages in this context. Our study results reveal a statistically significant difference in costs between the two languages in 95% of the cases examined. Furthermore, our analysis demonstrates that the choice of programming language can influence energy efficiency significantly, up to 99.16% during model training and up to 99.8% during inferences, for a given ML task.
CodeSAM: Source Code Representation Learning by Infusing Self-Attention with Multi-Code-View Graphs
Nov 21, 2024



Machine Learning (ML) for software engineering (SE) has gained prominence due to its ability to significantly enhance the performance of various SE applications. This progress is largely attributed to the development of generalizable source code representations that effectively capture the syntactic and semantic characteristics of code. In recent years, pre-trained transformer-based models, inspired by natural language processing (NLP), have shown remarkable success in SE tasks. However, source code contains structural and semantic properties embedded within its grammar, which can be extracted from structured code-views like the Abstract Syntax Tree (AST), Data-Flow Graph (DFG), and Control-Flow Graph (CFG). These code-views can complement NLP techniques, further improving SE tasks. Unfortunately, there are no flexible frameworks to infuse arbitrary code-views into existing transformer-based models effectively. Therefore, in this work, we propose CodeSAM, a novel scalable framework to infuse multiple code-views into transformer-based models by creating self-attention masks. We use CodeSAM to fine-tune a small language model (SLM) like CodeBERT on the downstream SE tasks of semantic code search, code clone detection, and program classification. Experimental results show that by using this technique, we improve downstream performance when compared to SLMs like GraphCodeBERT and CodeBERT on all three tasks by utilizing individual code-views or a combination of code-views during fine-tuning. We believe that these results are indicative that techniques like CodeSAM can help create compact yet performant code SLMs that fit in resource constrained settings.
COMEX: A Tool for Generating Customized Source Code Representations
Jul 10, 2023

Learning effective representations of source code is critical for any Machine Learning for Software Engineering (ML4SE) system. Inspired by natural language processing, large language models (LLMs) like Codex and CodeGen treat code as generic sequences of text and are trained on huge corpora of code data, achieving state of the art performance on several software engineering (SE) tasks. However, valid source code, unlike natural language, follows a strict structure and pattern governed by the underlying grammar of the programming language. Current LLMs do not exploit this property of the source code as they treat code like a sequence of tokens and overlook key structural and semantic properties of code that can be extracted from code-views like the Control Flow Graph (CFG), Data Flow Graph (DFG), Abstract Syntax Tree (AST), etc. Unfortunately, the process of generating and integrating code-views for every programming language is cumbersome and time consuming. To overcome this barrier, we propose our tool COMEX - a framework that allows researchers and developers to create and combine multiple code-views which can be used by machine learning (ML) models for various SE tasks. Some salient features of our tool are: (i) it works directly on source code (which need not be compilable), (ii) it currently supports Java and C#, (iii) it can analyze both method-level snippets and program-level snippets by using both intra-procedural and inter-procedural analysis, and (iv) it is easily extendable to other languages as it is built on tree-sitter - a widely used incremental parser that supports over 40 languages. We believe this easy-to-use code-view generation and customization tool will give impetus to research in source code representation learning methods and ML4SE. Tool: https://pypi.org/project/comex - GitHub: https://github.com/IBM/tree-sitter-codeviews - Demo: https://youtu.be/GER6U87FVbU
ML-Quest: A Game for Introducing Machine Learning Concepts to K-12 Students
Jul 13, 2021



Today, Machine Learning (ML) is of a great importance to society due to the availability of huge data and high computational resources. This ultimately led to the introduction of ML concepts at multiple levels of education including K-12 students to promote computational thinking. However, teaching these concepts to K-12 through traditional methodologies such as video lectures and books is challenging. Many studies in the literature have reported that using interactive environments such as games to teach computational thinking and programming improves retention capacity and motivation among students. Therefore, introducing ML concepts using a game might enhance students' understanding of the subject and motivate them to learn further. However, we are not aware of any existing game which explicitly focuses on introducing ML concepts to students using game play. Hence, in this paper, we propose ML-Quest, a 3D video game to provide conceptual overview of three ML concepts: Supervised Learning, Gradient Descent and K-Nearest Neighbor (KNN) Classification. The crux of the game is to introduce the definition and working of these concepts, which we call conceptual overview, in a simulated scenario without overwhelming students with the intricacies of ML. The game has been predominantly evaluated for its usefulness and player experience using the Technology Acceptance Model (TAM) model with the help of 23 higher-secondary school students. The survey result shows that around 70% of the participants either agree or strongly agree that the ML-Quest is quite interactive and useful in introducing them to ML concepts.
An Ontology Based Modeling Framework for Design of Educational Technologies
Feb 07, 2018
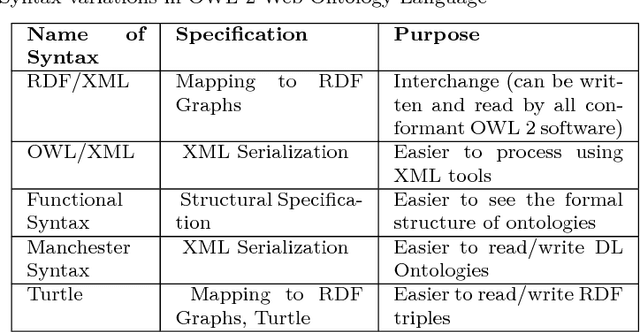


Despite rapid progress, most of the educational technologies today lack a strong instructional design knowledge basis leading to questionable quality of instruction. In addition, a major challenge is to customize these educational technologies for a wide range of instructional designs. Ontologies are one of the pertinent mechanisms to represent instructional design in the literature. However, existing approaches do not support modeling of flexible instructional designs. To address this problem, in this paper, we propose an ontology based framework for systematic modeling of different aspects of instructional design knowledge based on domain patterns. As part of the framework, we present ontologies for modeling goals, instructional processes and instructional materials. We demonstrate the ontology framework by presenting instances of the ontology for the large scale case study of adult literacy in India (287 million learners spread across 22 Indian Languages), which requires creation of 1000 similar but varied eLearning Systems based on flexible instructional designs. The implemented framework is available at http://rice.iiit.ac.in and is transferred to National Literacy Mission of Government of India. This framework could be used for modeling instructional design knowledge of systems for skills, school education and beyond.