 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Synchronic Definitions and Semantic Relations to Classify Semantic Change Types
Jun 06, 2024There is abundant evidence of the fact that the way words change their meaning can be classified in different types of change, highlighting the relationship between the old and new meanings (among which generalization, specialization and co-hyponymy transfer). In this paper, we present a way of detecting these types of change by constructing a model that leverages information both from synchronic lexical relations and definitions of word meanings. Specifically, we use synset definitions and hierarchy information from WordNet and test it on a digitized version of Blank's (1997) dataset of semantic change types. Finally, we show how the sense relationships can improve models for both approximation of human judgments of semantic relatedness as well as binary Lexical Semantic Change Detection.
Analyzing Semantic Change through Lexical Replacements
Apr 29, 2024Modern language models are capable of contextualizing words based on their surrounding context. However, this capability is often compromised due to semantic change that leads to words being used in new, unexpected contexts not encountered during pre-training. In this paper, we model \textit{semantic change} by studying the effect of unexpected contexts introduced by \textit{lexical replacements}. We propose a \textit{replacement schema} where a target word is substituted with lexical replacements of varying relatedness, thus simulating different kinds of semantic change. Furthermore, we leverage the replacement schema as a basis for a novel \textit{interpretable} model for semantic change. We are also the first to evaluate the use of LLaMa for semantic change detection.
A Systematic Comparison of Contextualized Word Embeddings for Lexical Semantic Change
Feb 22, 2024Contextualized embeddings are the preferred tool for modeling Lexical Semantic Change (LSC). Current evaluations typically focus on a specific task known as Graded Change Detection (GCD). However, performance comparison across work are often misleading due to their reliance on diverse settings. In this paper, we evaluate state-of-the-art models and approaches for GCD under equal conditions. We further break the LSC problem into Word-in-Context (WiC) and Word Sense Induction (WSI) tasks, and compare models across these different levels. Our evaluation is performed across different languages on eight available benchmarks for LSC, and shows that (i) APD outperforms other approaches for GCD; (ii) XL-LEXEME outperforms other contextualized models for WiC, WSI, and GCD, while being comparable to GPT-4; (iii) there is a clear need for improving the modeling of word meanings, as well as focus on how, when, and why these meanings change, rather than solely focusing on the extent of semantic change.
GPT v BERT: Dawn of Justice for Semantic Change Detection
Jan 25, 2024In the universe of Natural Language Processing, Transformer-based language models like BERT and (Chat)GPT have emerged as lexical superheroes with great power to solve open research problems. In this paper, we specifically focus on the temporal problem of semantic change, and evaluate their ability to solve two diachronic extensions of the Word-in-Context (WiC) task: TempoWiC and HistoWiC. In particular, we investigate the potential of a novel, off-the-shelf technology like ChatGPT (and GPT) 3.5 compared to BERT, which represents a family of models that currently stand as the state-of-the-art for modeling semantic change. Our experiments represent the first attempt to assess the use of (Chat)GPT for studying semantic change. Our results indicate that ChatGPT performs significantly worse than the foundational GPT version. Furthermore, our results demonstrate that (Chat)GPT achieves slightly lower performance than BERT in detecting long-term changes but performs significantly worse in detecting short-term changes.
The DURel Annotation Tool: Human and Computational Measurement of Semantic Proximity, Sense Clusters and Semantic Change
Nov 21, 2023
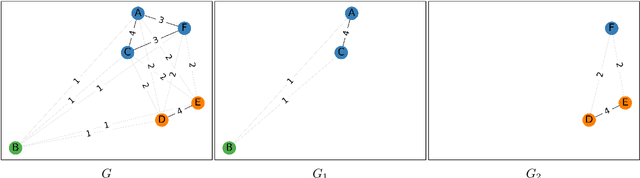


We present the DURel tool that implements the annotation of semantic proximity between uses of words into an online, open source interface. The tool supports standardized human annotation as well as computational annotation, building on recent advances with Word-in-Context models. Annotator judgments are clustered with automatic graph clustering techniques and visualized for analysis. This allows to measure word senses with simple and intuitive micro-task judgments between use pairs, requiring minimal preparation efforts. The tool offers additional functionalities to compare the agreement between annotators to guarantee the inter-subjectivity of the obtained judgments and to calculate summary statistics giving insights into sense frequency distributions, semantic variation or changes of senses over time.
Computational modeling of semantic change
Apr 13, 2023In this chapter we provide an overview of computational modeling for semantic change using large and semi-large textual corpora. We aim to provide a key for the interpretation of relevant methods and evaluation techniques, and also provide insights into important aspects of the computational study of semantic change. We discuss the pros and cons of different classes of models with respect to the properties of the data from which one wishes to model semantic change, and which avenues are available to evaluate the results.
DWUG: A large Resource of Diachronic Word Usage Graphs in Four Languages
Apr 17, 2021


Word meaning is notoriously difficult to capture, both synchronically and diachronically. In this paper, we describe the creation of the largest resource of graded contextualized, diachronic word meaning annotation in four different languages, based on 100,000 human semantic proximity judgments. We thoroughly describe the multi-round incremental annotation process, the choice for a clustering algorithm to group usages into senses, and possible - diachronic and synchronic - uses for this dataset.
SuperSim: a test set for word similarity and relatedness in Swedish
Apr 12, 2021



Language models are notoriously difficult to evaluate. We release SuperSim, a large-scale similarity and relatedness test set for Swedish built with expert human judgments. The test set is composed of 1,360 word-pairs independently judged for both relatedness and similarity by five annotators. We evaluate three different models (Word2Vec, fastText, and GloVe) trained on two separate Swedish datasets, namely the Swedish Gigaword corpus and a Swedish Wikipedia dump, to provide a baseline for future comparison. We release the fully annotated test set, code, baseline models, and data.
Challenges for Computational Lexical Semantic Change
Jan 19, 2021
The computational study of lexical semantic change (LSC) has taken off in the past few years and we are seeing increasing interest in the field, from both computational sciences and linguistics. Most of the research so far has focused on methods for modelling and detecting semantic change using large diachronic textual data, with the majority of the approaches employing neural embeddings. While methods that offer easy modelling of diachronic text are one of the main reasons for the spiking interest in LSC, neural models leave many aspects of the problem unsolved. The field has several open and complex challenges. In this chapter, we aim to describe the most important of these challenges and outline future directions.
SemEval-2020 Task 1: Unsupervised Lexical Semantic Change Detection
Aug 28, 2020
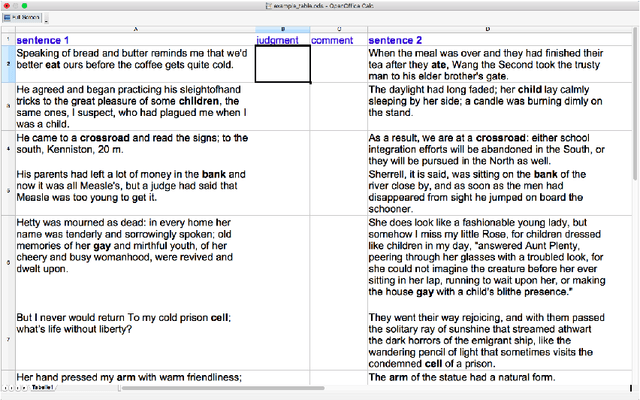
Lexical Semantic Change detection, i.e., the task of identifying words that change meaning over time, is a very active research area, with applications in NLP, lexicography, and linguistics. Evaluation is currently the most pressing problem in Lexical Semantic Change detection, as no gold standards are available to the community, which hinders progress. We present the results of the first shared task that addresses this gap by providing researchers with an evaluation framework and manually annotated, high-quality datasets for English, German, Latin, and Swedish. 33 teams submitted 186 systems, which were evaluated on two subtasks.