 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing BERT for German Compound Semantics
May 20, 2025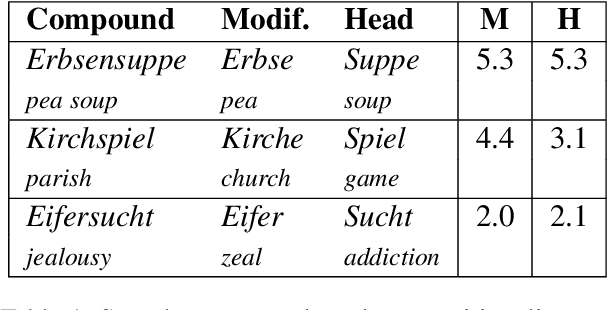
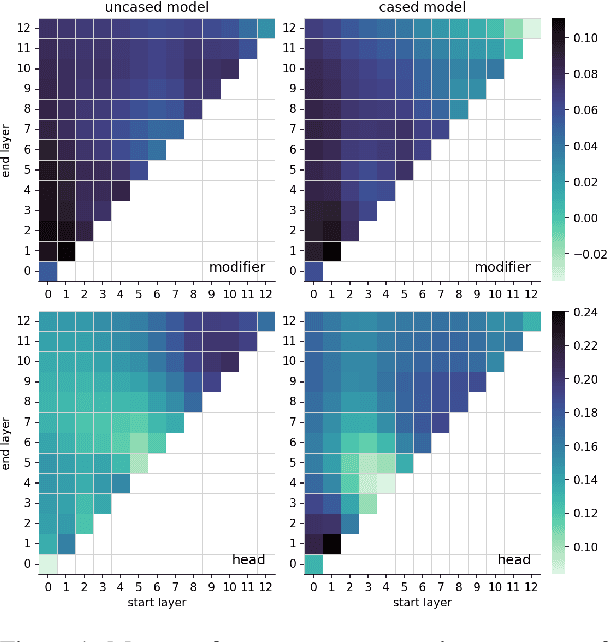
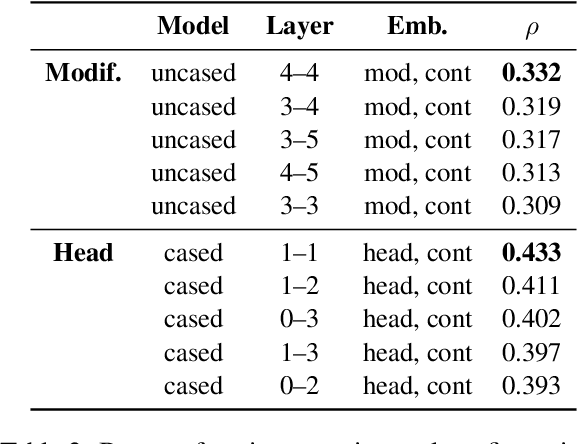
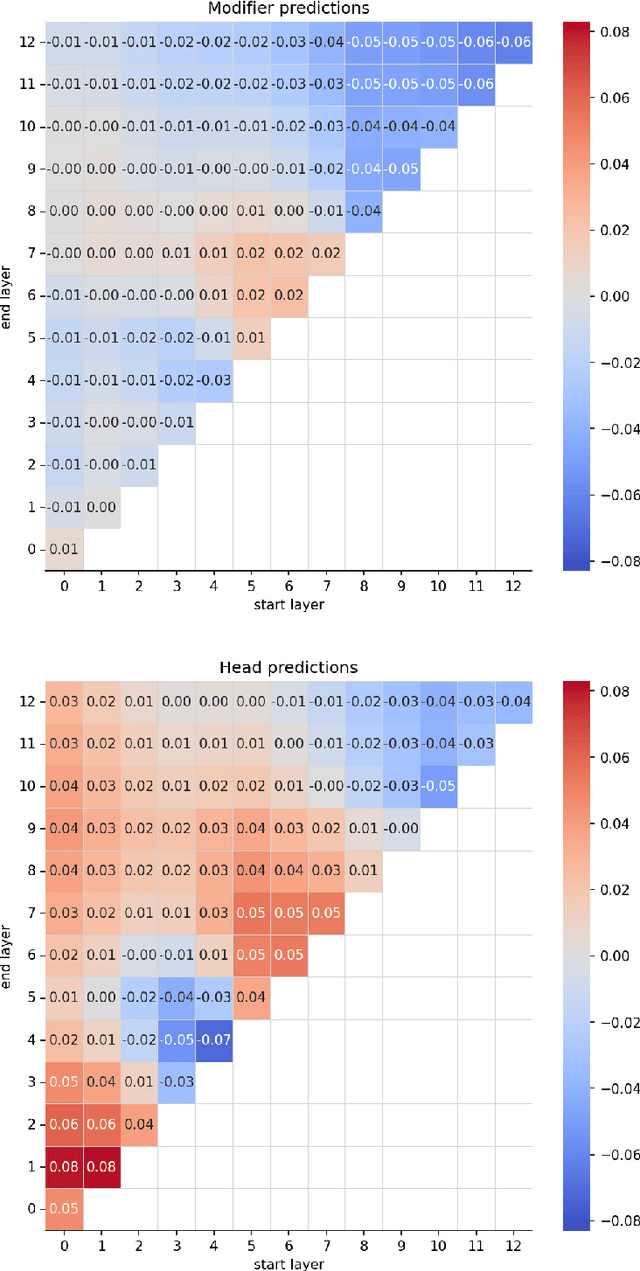
This paper investigates the extent to which pretrained German BERT encodes knowledge of noun compound semantics. We comprehensively vary combinations of target tokens, layers, and cased vs. uncased models, and evaluate them by predicting the compositionality of 868 gold standard compounds. Looking at representational patterns within the transformer architecture, we observe trends comparable to equivalent prior work on English, with compositionality information most easily recoverable in the early layers. However, our strongest results clearly lag behind those reported for English, suggesting an inherently more difficult task in German. This may be due to the higher productivity of compounding in German than in English and the associated increase in constituent-level ambiguity, including in our target compound set.
Semantics of Multiword Expressions in Transformer-Based Models: A Survey
Jan 27, 2024Multiword expressions (MWEs) are composed of multiple words and exhibit variable degrees of compositionality. As such, their meanings are notoriously difficult to model, and it is unclear to what extent this issue affects transformer architectures. Addressing this gap, we provide the first in-depth survey of MWE processing with transformer models. We overall find that they capture MWE semantics inconsistently, as shown by reliance on surface patterns and memorized information. MWE meaning is also strongly localized, predominantly in early layers of the architecture. Representations benefit from specific linguistic properties, such as lower semantic idiosyncrasy and ambiguity of target expressions. Our findings overall question the ability of transformer models to robustly capture fine-grained semantics. Furthermore, we highlight the need for more directly comparable evaluation setups.
Mindful Explanations: Prevalence and Impact of Mind Attribution in XAI Research
Dec 19, 2023When users perceive AI systems as mindful, independent agents, they hold them responsible instead of the AI experts who created and designed these systems. So far, it has not been studied whether explanations support this shift in responsibility through the use of mind-attributing verbs like "to think". To better understand the prevalence of mind-attributing explanations we analyse AI explanations in 3,533 explainable AI (XAI) research articles from the Semantic Scholar Open Research Corpus (S2ORC). Using methods from semantic shift detection, we identify three dominant types of mind attribution: (1) metaphorical (e.g. "to learn" or "to predict"), (2) awareness (e.g. "to consider"), and (3) agency (e.g. "to make decisions"). We then analyse the impact of mind-attributing explanations on awareness and responsibility in a vignette-based experiment with 199 participants. We find that participants who were given a mind-attributing explanation were more likely to rate the AI system as aware of the harm it caused. Moreover, the mind-attributing explanation had a responsibility-concealing effect: Considering the AI experts' involvement lead to reduced ratings of AI responsibility for participants who were given a non-mind-attributing or no explanation. In contrast, participants who read the mind-attributing explanation still held the AI system responsible despite considering the AI experts' involvement. Taken together, our work underlines the need to carefully phrase explanations about AI systems in scientific writing to reduce mind attribution and clearly communicate human responsibility.