 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting the Exit from Nuclear Energy in Germany with NLP
Aug 25, 2024Annotation of political discourse is resource-intensive, but recent developments in NLP promise to automate complex annotation tasks. Fine-tuned transformer-based models outperform human annotators in some annotation tasks, but they require large manually annotated training datasets. In our contribution, we explore to which degree a manually annotated dataset can be automatically replicated with today's NLP methods, using unsupervised machine learning and zero- and few-shot learning.
Willkommens-Merkel, Chaos-Johnson, and Tore-Klose: Modeling the Evaluative Meaning of German Personal Name Compounds
Apr 05, 2024We present a comprehensive computational study of the under-investigated phenomenon of personal name compounds (PNCs) in German such as Willkommens-Merkel ('Welcome-Merkel'). Prevalent in news, social media, and political discourse, PNCs are hypothesized to exhibit an evaluative function that is reflected in a more positive or negative perception as compared to the respective personal full name (such as Angela Merkel). We model 321 PNCs and their corresponding full names at discourse level, and show that PNCs bear an evaluative nature that can be captured through a variety of computational methods. Specifically, we assess through valence information whether a PNC is more positively or negatively evaluative than the person's name, by applying and comparing two approaches using (i) valence norms and (ii) pretrained language models (PLMs). We further enrich our data with personal, domain-specific, and extra-linguistic information and perform a range of regression analyses revealing that factors including compound and modifier valence, domain, and political party membership influence how a PNC is evaluated.
Between welcome culture and border fence. A dataset on the European refugee crisis in German newspaper reports
Nov 19, 2021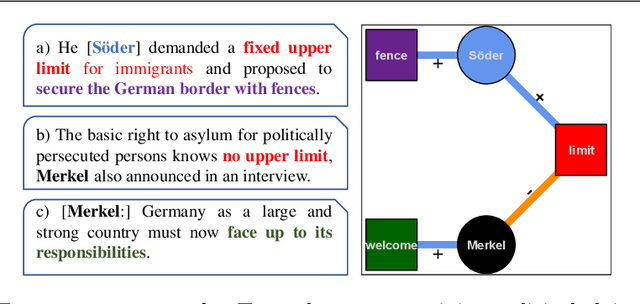
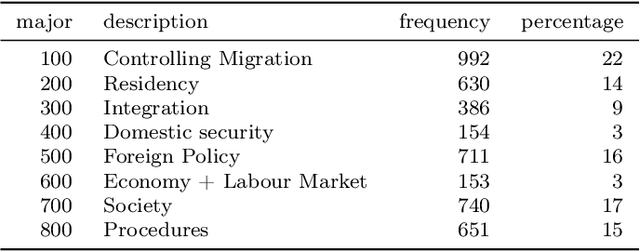
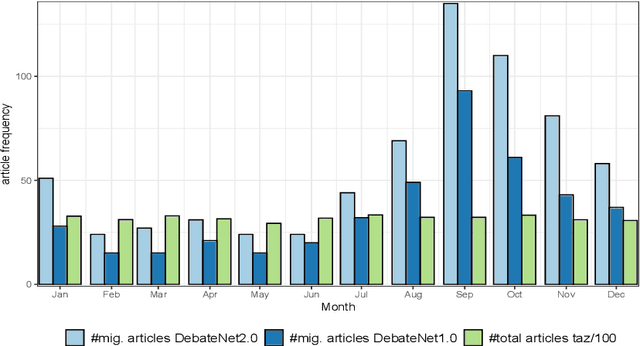
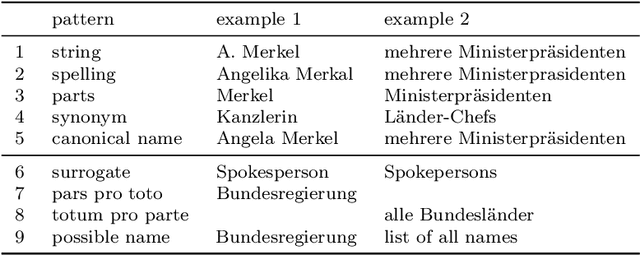
Newspaper reports provide a rich source of information on the unfolding of public debate on specific policy fields that can serve as basis for inquiry in political science. Such debates are often triggered by critical events, which attract public attention and incite the reactions of political actors: crisis sparks the debate. However, due to the challenges of reliable annotation and modeling, few large-scale datasets with high-quality annotation are available. This paper introduces DebateNet2.0, which traces the political discourse on the European refugee crisis in the German quality newspaper taz during the year 2015. The core units of our annotation are political claims (requests for specific actions to be taken within the policy field) and the actors who make them (politicians, parties, etc.). The contribution of this paper is twofold. First, we document and release DebateNet2.0 along with its companion R package, mardyR, guiding the reader through the practical and conceptual issues related to the annotation of policy debates in newspapers. Second, we outline and apply a Discourse Network Analysis (DNA) to DebateNet2.0, comparing two crucial moments of the policy debate on the 'refugee crisis': the migration flux through the Mediterranean in April/May and the one along the Balkan route in September/October. Besides the released resources and the case-study, our contribution is also methodological: we talk the reader through the steps from a newspaper article to a discourse network, demonstrating that there is not just one discourse network for the German migration debate, but multiple ones, depending on the topic of interest (political actors, policy fields, time spans).