 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Human Interaction Motion Generation
Mar 17, 2025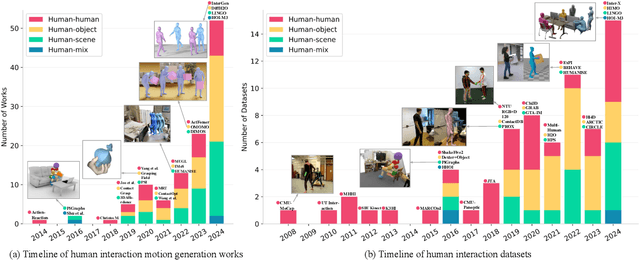


Humans inhabit a world defined by interactions -- with other humans, objects, and environments. These interactive movements not only convey our relationships with our surroundings but also demonstrate how we perceive and communicate with the real world. Therefore, replicating these interaction behaviors in digital systems has emerged as an important topic for applications in robotics, virtual reality, and animation. While recent advances in deep generative models and new datasets have accelerated progress in this field, significant challenges remain in modeling the intricate human dynamics and their interactions with entities in the external world. In this survey, we present, for the first time, a comprehensive overview of the literature in human interaction motion generation. We begin by establishing foundational concepts essential for understanding the research background. We then systematically review existing solutions and datasets across three primary interaction tasks -- human-human, human-object, and human-scene interactions -- followed by evaluation metrics. Finally, we discuss open research directions and future opportunities.
ReMoS: Reactive 3D Motion Synthesis for Two-Person Interactions
Nov 28, 2023Current approaches for 3D human motion synthesis can generate high-quality 3D animations of digital humans performing a wide variety of actions and gestures. However, there is still a notable technological gap in addressing the complex dynamics of multi-human interactions within this paradigm. In this work, we introduce ReMoS, a denoising diffusion-based probabilistic model for reactive motion synthesis that explores two-person interactions. Given the motion of one person, we synthesize the reactive motion of the second person to complete the interactions between the two. In addition to synthesizing the full-body motions, we also synthesize plausible hand interactions. We show the performance of ReMoS under a wide range of challenging two-person scenarios including pair-dancing, Ninjutsu, kickboxing, and acrobatics, where one person's movements have complex and diverse influences on the motions of the other. We further propose the ReMoCap dataset for two-person interactions consisting of full-body and hand motions. We evaluate our approach through multiple quantitative metrics, qualitative visualizations, and a user study. Our results are usable in interactive applications while also providing an adequate amount of control for animators.
IMoS: Intent-Driven Full-Body Motion Synthesis for Human-Object Interactions
Dec 16, 2022Can we make virtual characters in a scene interact with their surrounding objects through simple instructions? Is it possible to synthesize such motion plausibly with a diverse set of objects and instructions? Inspired by these questions, we present the first framework to synthesize the full-body motion of virtual human characters performing specified actions with 3D objects placed within their reach. Our system takes as input textual instructions specifying the objects and the associated intentions of the virtual characters and outputs diverse sequences of full-body motions. This is in contrast to existing work, where full-body action synthesis methods generally do not consider object interactions, and human-object interaction methods focus mainly on synthesizing hand or finger movements for grasping objects. We accomplish our objective by designing an intent-driven full-body motion generator, which uses a pair of decoupled conditional variational autoencoders (CVAE) to learn the motion of the body parts in an autoregressive manner. We also optimize for the positions of the objects with six degrees of freedom (6DoF) such that they plausibly fit within the hands of the synthesized characters. We compare our proposed method with the existing methods of motion synthesis and establish a new and stronger state-of-the-art for the task of intent-driven motion synthesis. Through a user study, we further show that our synthesized full-body motions appear more realistic to the participants in more than 80% of scenarios compared to the current state-of-the-art methods, and are perceived to be as good as the ground truth on several occasions.
Synthesis of Compositional Animations from Textual Descriptions
Mar 31, 2021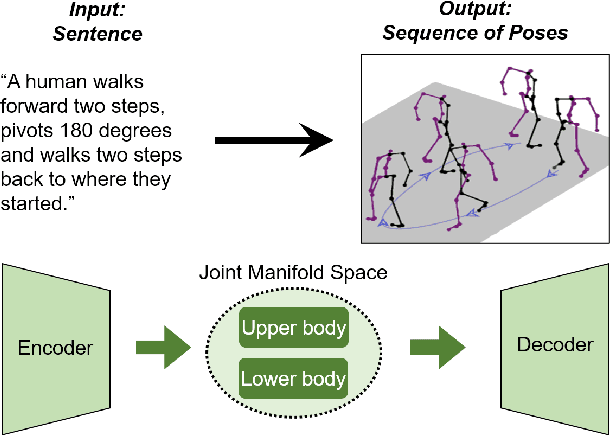
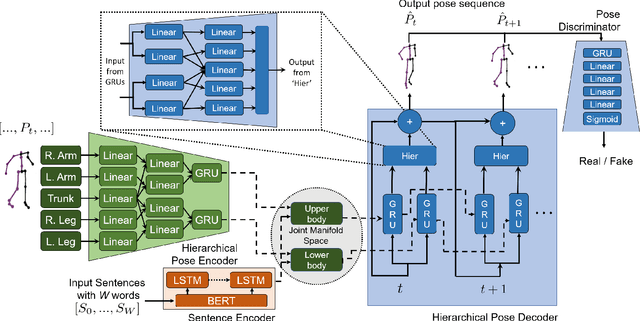
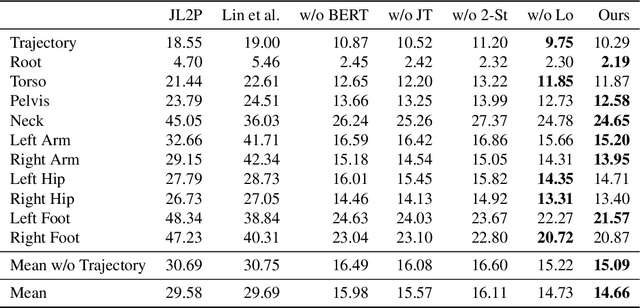
"How can we animate 3D-characters from a movie script or move robots by simply telling them what we would like them to do?" "How unstructured and complex can we make a sentence and still generate plausible movements from it?" These are questions that need to be answered in the long-run, as the field is still in its infancy. Inspired by these problems, we present a new technique for generating compositional actions, which handles complex input sentences. Our output is a 3D pose sequence depicting the actions in the input sentence. We propose a hierarchical two-stream sequential model to explore a finer joint-level mapping between natural language sentences and 3D pose sequences corresponding to the given motion. We learn two manifold representations of the motion -- one each for the upper body and the lower body movements. Our model can generate plausible pose sequences for short sentences describing single actions as well as long compositional sentences describing multiple sequential and superimposed actions. We evaluate our proposed model on the publicly available KIT Motion-Language Dataset containing 3D pose data with human-annotated sentences. Experimental results show that our model advances the state-of-the-art on text-based motion synthesis in objective evaluations by a margin of 50%. Qualitative evaluations based on a user study indicate that our synthesized motions are perceived to be the closest to the ground-truth motion captures for both short and compositional sentences.