 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThis Is Taking Too Long -- Investigating Time as a Proxy for Energy Consumption of LLMs
Mar 16, 2026The energy consumption of Large Language Models (LLMs) is raising growing concerns due to their adverse effects on environmental stability and resource use. Yet, these energy costs remain largely opaque to users, especially when models are accessed through an API -- a black box in which all information depends on what providers choose to disclose. In this work, we investigate inference time measurements as a proxy to approximate the associated energy costs of API-based LLMs. We ground our approach by comparing our estimations with actual energy measurements from locally hosted equivalents. Our results show that time measurements allow us to infer GPU models for API-based LLMs, grounding our energy cost estimations. Our work aims to create means for understanding the associated energy costs of API-based LLMs, especially for end users.
Promoting Sustainable Web Agents: Benchmarking and Estimating Energy Consumption through Empirical and Theoretical Analysis
Nov 06, 2025Web agents, like OpenAI's Operator and Google's Project Mariner, are powerful agentic systems pushing the boundaries of Large Language Models (LLM). They can autonomously interact with the internet at the user's behest, such as navigating websites, filling search masks, and comparing price lists. Though web agent research is thriving, induced sustainability issues remain largely unexplored. To highlight the urgency of this issue, we provide an initial exploration of the energy and $CO_2$ cost associated with web agents from both a theoretical -via estimation- and an empirical perspective -by benchmarking. Our results show how different philosophies in web agent creation can severely impact the associated expended energy, and that more energy consumed does not necessarily equate to better results. We highlight a lack of transparency regarding disclosing model parameters and processes used for some web agents as a limiting factor when estimating energy consumption. Our work contributes towards a change in thinking of how we evaluate web agents, advocating for dedicated metrics measuring energy consumption in benchmarks.
Human in the Latent Loop (HILL): Interactively Guiding Model Training Through Human Intuition
May 09, 2025Latent space representations are critical for understanding and improving the behavior of machine learning models, yet they often remain obscure and intricate. Understanding and exploring the latent space has the potential to contribute valuable human intuition and expertise about respective domains. In this work, we present HILL, an interactive framework allowing users to incorporate human intuition into the model training by interactively reshaping latent space representations. The modifications are infused into the model training loop via a novel approach inspired by knowledge distillation, treating the user's modifications as a teacher to guide the model in reshaping its intrinsic latent representation. The process allows the model to converge more effectively and overcome inefficiencies, as well as provide beneficial insights to the user. We evaluated HILL in a user study tasking participants to train an optimal model, closely observing the employed strategies. The results demonstrated that human-guided latent space modifications enhance model performance while maintaining generalization, yet also revealing the risks of including user biases. Our work introduces a novel human-AI interaction paradigm that infuses human intuition into model training and critically examines the impact of human intervention on training strategies and potential biases.
TxP: Reciprocal Generation of Ground Pressure Dynamics and Activity Descriptions for Improving Human Activity Recognition
May 04, 2025
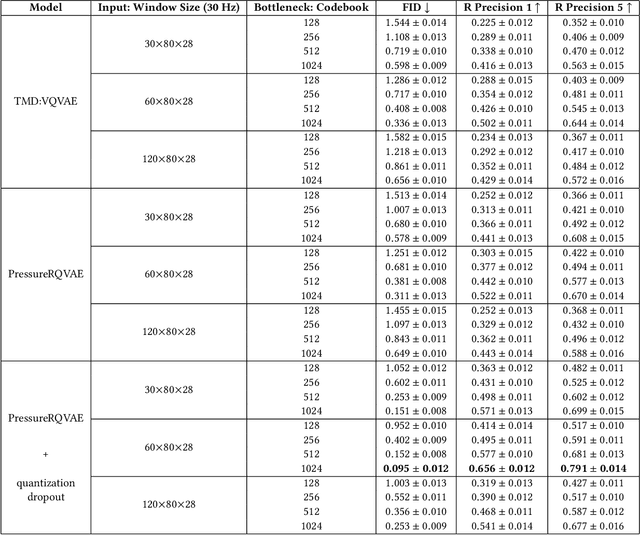


Sensor-based human activity recognition (HAR) has predominantly focused on Inertial Measurement Units and vision data, often overlooking the capabilities unique to pressure sensors, which capture subtle body dynamics and shifts in the center of mass. Despite their potential for postural and balance-based activities, pressure sensors remain underutilized in the HAR domain due to limited datasets. To bridge this gap, we propose to exploit generative foundation models with pressure-specific HAR techniques. Specifically, we present a bidirectional Text$\times$Pressure model that uses generative foundation models to interpret pressure data as natural language. TxP accomplishes two tasks: (1) Text2Pressure, converting activity text descriptions into pressure sequences, and (2) Pressure2Text, generating activity descriptions and classifications from dynamic pressure maps. Leveraging pre-trained models like CLIP and LLaMA 2 13B Chat, TxP is trained on our synthetic PressLang dataset, containing over 81,100 text-pressure pairs. Validated on real-world data for activities such as yoga and daily tasks, TxP provides novel approaches to data augmentation and classification grounded in atomic actions. This consequently improved HAR performance by up to 12.4\% in macro F1 score compared to the state-of-the-art, advancing pressure-based HAR with broader applications and deeper insights into human movement.
Talk2X -- An Open-Source Toolkit Facilitating Deployment of LLM-Powered Chatbots on the Web
Apr 04, 2025



Integrated into websites, LLM-powered chatbots offer alternative means of navigation and information retrieval, leading to a shift in how users access information on the web. Yet, predominantly closed-sourced solutions limit proliferation among web hosts and suffer from a lack of transparency with regard to implementation details and energy efficiency. In this work, we propose our openly available agent Talk2X leveraging an adapted retrieval-augmented generation approach (RAG) combined with an automatically generated vector database, benefiting energy efficiency. Talk2X's architecture is generalizable to arbitrary websites offering developers a ready to use tool for integration. Using a mixed-methods approach, we evaluated Talk2X's usability by tasking users to acquire specific assets from an open science repository. Talk2X significantly improved task completion time, correctness, and user experience supporting users in quickly pinpointing specific information as compared to standard user-website interaction. Our findings contribute technical advancements to an ongoing paradigm shift of how we access information on the web.
Towards Sustainable Web Agents: A Plea for Transparency and Dedicated Metrics for Energy Consumption
Feb 25, 2025


Improvements in the area of large language models have shifted towards the construction of models capable of using external tools and interpreting their outputs. These so-called web agents have the ability to interact autonomously with the internet. This allows them to become powerful daily assistants handling time-consuming, repetitive tasks while supporting users in their daily activities. While web agent research is thriving, the sustainability aspect of this research direction remains largely unexplored. We provide an initial exploration of the energy and CO2 cost associated with web agents. Our results show how different philosophies in web agent creation can severely impact the associated expended energy. We highlight lacking transparency regarding the disclosure of model parameters and processes used for some web agents as a limiting factor when estimating energy consumption. As such, our work advocates a change in thinking when evaluating web agents, warranting dedicated metrics for energy consumption and sustainability.
GenAI Assisting Medical Training
Oct 21, 2024

Medical procedures such as venipuncture and cannulation are essential for nurses and require precise skills. Learning this skill, in turn, is a challenge for educators due to the number of teachers per class and the complexity of the task. The study aims to help students with skill acquisition and alleviate the educator's workload by integrating generative AI methods to provide real-time feedback on medical procedures such as venipuncture and cannulation.
Text me the data: Generating Ground Pressure Sequence from Textual Descriptions for HAR
Feb 22, 2024



In human activity recognition (HAR), the availability of substantial ground truth is necessary for training efficient models. However, acquiring ground pressure data through physical sensors itself can be cost-prohibitive, time-consuming. To address this critical need, we introduce Text-to-Pressure (T2P), a framework designed to generate extensive ground pressure sequences from textual descriptions of human activities using deep learning techniques. We show that the combination of vector quantization of sensor data along with simple text conditioned auto regressive strategy allows us to obtain high-quality generated pressure sequences from textual descriptions with the help of discrete latent correlation between text and pressure maps. We achieved comparable performance on the consistency between text and generated motion with an R squared value of 0.722, Masked R squared value of 0.892, and FID score of 1.83. Additionally, we trained a HAR model with the the synthesized data and evaluated it on pressure dynamics collected by a real pressure sensor which is on par with a model trained on only real data. Combining both real and synthesized training data increases the overall macro F1 score by 5.9 percent.
Unreflected Acceptance -- Investigating the Negative Consequences of ChatGPT-Assisted Problem Solving in Physics Education
Aug 21, 2023Large language models (LLMs) have recently gained popularity. However, the impact of their general availability through ChatGPT on sensitive areas of everyday life, such as education, remains unclear. Nevertheless, the societal impact on established educational methods is already being experienced by both students and educators. Our work focuses on higher physics education and examines problem solving strategies. In a study, students with a background in physics were assigned to solve physics exercises, with one group having access to an internet search engine (N=12) and the other group being allowed to use ChatGPT (N=27). We evaluated their performance, strategies, and interaction with the provided tools. Our results showed that nearly half of the solutions provided with the support of ChatGPT were mistakenly assumed to be correct by the students, indicating that they overly trusted ChatGPT even in their field of expertise. Likewise, in 42% of cases, students used copy & paste to query ChatGPT -- an approach only used in 4% of search engine queries -- highlighting the stark differences in interaction behavior between the groups and indicating limited reflection when using ChatGPT. In our work, we demonstrated a need to (1) guide students on how to interact with LLMs and (2) create awareness of potential shortcomings for users.
SynthCal: A Synthetic Benchmarking Pipeline to Compare Camera Calibration Algorithms
Jul 03, 2023



Accurate camera calibration is crucial for various computer vision applications. However, measuring camera parameters in the real world is challenging and arduous, and there needs to be a dataset with ground truth to evaluate calibration algorithms' accuracy. In this paper, we present SynthCal, a synthetic camera calibration benchmarking pipeline that generates images of calibration patterns to measure and enable accurate quantification of calibration algorithm performance in camera parameter estimation. We present a SynthCal-generated calibration dataset with four common patterns, two camera types, and two environments with varying view, distortion, lighting, and noise levels. The dataset evaluates single-view calibration algorithms by measuring reprojection and root-mean-square errors for identical patterns and camera settings. Additionally, we analyze the significance of different patterns using Zhang's method, which estimates intrinsic and extrinsic camera parameters with known correspondences between 3D points and their 2D projections in different configurations and environments. The experimental results demonstrate the effectiveness of SynthCal in evaluating various calibration algorithms and patterns.