 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongReason: A Synthetic Long-Context Reasoning Benchmark via Context Expansion
Jan 25, 2025



Large language models (LLMs) have demonstrated remarkable progress in understanding long-context inputs. However, benchmarks for evaluating the long-context reasoning abilities of LLMs fall behind the pace. Existing benchmarks often focus on a narrow range of tasks or those that do not demand complex reasoning. To address this gap and enable a more comprehensive evaluation of the long-context reasoning capabilities of current LLMs, we propose a new synthetic benchmark, LongReason, which is constructed by synthesizing long-context reasoning questions from a varied set of short-context reasoning questions through context expansion. LongReason consists of 794 multiple-choice reasoning questions with diverse reasoning patterns across three task categories: reading comprehension, logical inference, and mathematical word problems. We evaluate 21 LLMs on LongReason, revealing that most models experience significant performance drops as context length increases. Our further analysis shows that even state-of-the-art LLMs still have significant room for improvement in providing robust reasoning across different tasks. We will open-source LongReason to support the comprehensive evaluation of LLMs' long-context reasoning capabilities.
ToolHop: A Query-Driven Benchmark for Evaluating Large Language Models in Multi-Hop Tool Use
Jan 07, 2025Effective evaluation of multi-hop tool use is critical for analyzing the understanding, reasoning, and function-calling capabilities of large language models (LLMs). However, progress has been hindered by a lack of reliable evaluation datasets. To address this, we present ToolHop, a dataset comprising 995 user queries and 3,912 associated tools, specifically designed for rigorous evaluation of multi-hop tool use. ToolHop ensures diverse queries, meaningful interdependencies, locally executable tools, detailed feedback, and verifiable answers through a novel query-driven data construction approach that includes tool creation, document refinement, and code generation. We evaluate 14 LLMs across five model families (i.e., LLaMA3.1, Qwen2.5, Gemini1.5, Claude3.5, and GPT), uncovering significant challenges in handling multi-hop tool-use scenarios. The leading model, GPT-4o, achieves an accuracy of 49.04%, underscoring substantial room for improvement. Further analysis reveals variations in tool-use strategies for various families, offering actionable insights to guide the development of more effective approaches. Code and data can be found in https://huggingface.co/datasets/bytedance-research/ToolHop.
RubyStar: A Non-Task-Oriented Mixture Model Dialog System
Dec 16, 2017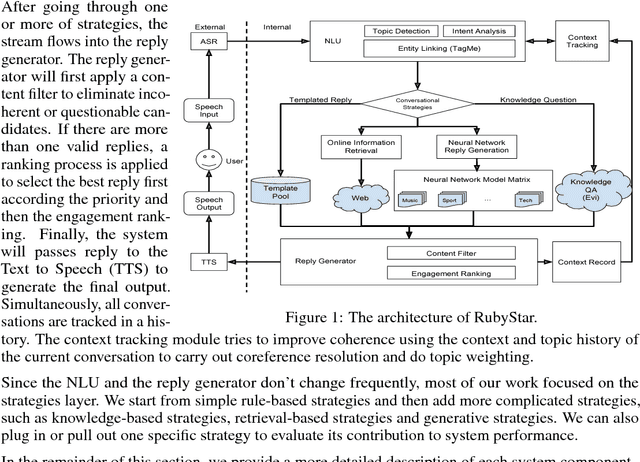


RubyStar is a dialog system designed to create "human-like" conversation by combining different response generation strategies. RubyStar conducts a non-task-oriented conversation on general topics by using an ensemble of rule-based, retrieval-based and generative methods. Topic detection, engagement monitoring, and context tracking are used for managing interaction. Predictable elements of conversation, such as the bot's backstory and simple question answering are handled by separate modules. We describe a rating scheme we developed for evaluating response generation. We find that character-level RNN is an effective generation model for general responses, with proper parameter settings; however other kinds of conversation topics might benefit from using other models.