 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMagnetic Resonance Spectroscopy Quantification Aided by Deep Estimations of Imperfection Factors and Overall Macromolecular Signal
Jun 16, 2023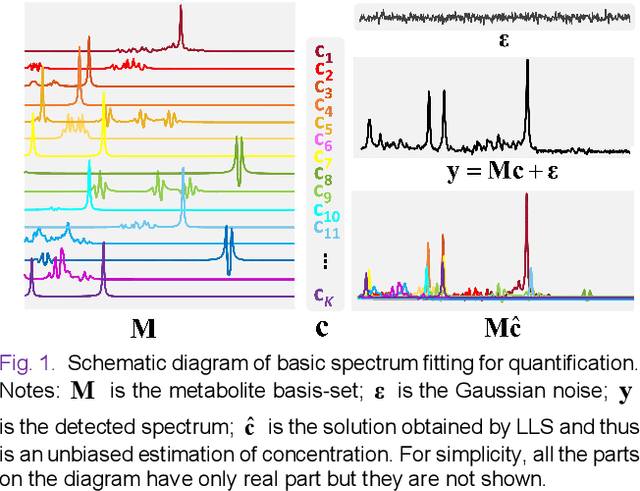
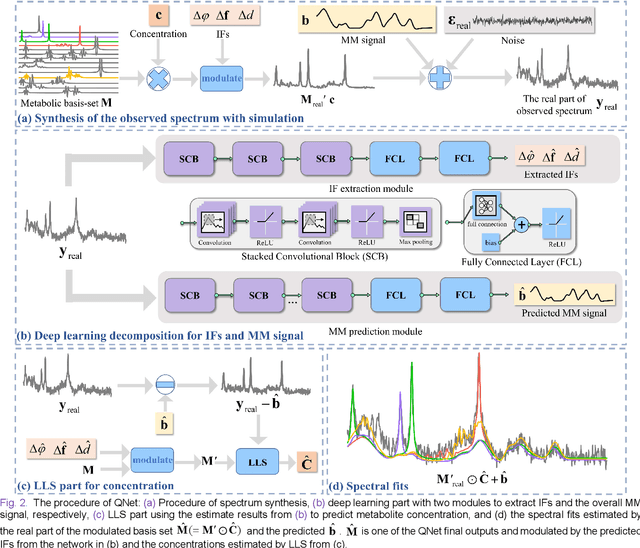
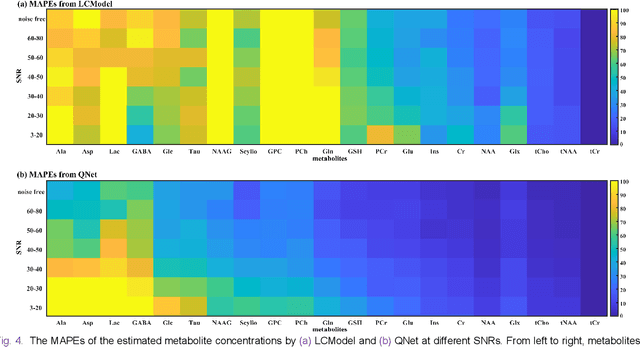
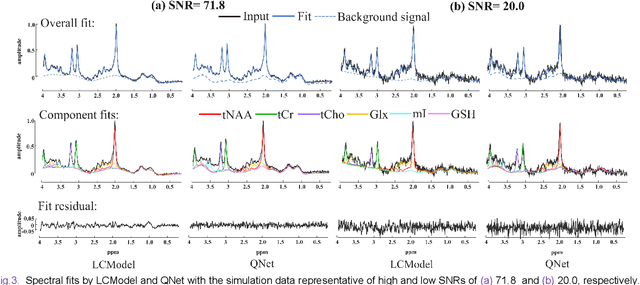
Magnetic Resonance Spectroscopy (MRS) is an important non-invasive technique for in vivo biomedical detection. However, it is still challenging to accurately quantify metabolites with proton MRS due to three problems: Serious overlaps of metabolite signals, signal distortions due to non-ideal acquisition conditions and interference with strong background signals including macromolecule signals. The most popular software, LCModel, adopts the non-linear least square to quantify metabolites and addresses these problems by introducing regularization terms, imperfection factors of non-ideal acquisition conditions, and designing several empirical priors such as basissets of both metabolites and macromolecules. However, solving such a large non-linear quantitative problem is complicated. Moreover, when the signal-to-noise ratio of an input MRS signal is low, the solution may have a large deviation. In this work, deep learning is introduced to reduce the complexity of solving this overall quantitative problem. Deep learning is designed to predict directly the imperfection factors and the overall signal from macromolecules. Then, the remaining part of the quantification problem becomes a much simpler effective fitting and is easily solved by Linear Least Squares (LLS), which greatly improves the generalization to unseen concentration of metabolites in the training data. Experimental results show that compared with LCModel, the proposed method has smaller quantification errors for 700 sets of simulated test data, and presents more stable quantification results for 20 sets of healthy in vivo data at a wide range of signal-to-noise ratio. Qnet also outperforms other deep learning methods in terms of lower quantification error on most metabolites. Finally, QNet has been deployed on a cloud computing platform, CloudBrain-MRS, which is open accessed at https://csrc.xmu.edu.cn/CloudBrain.html.
WikiLink: an encyclopedia-based semantic network for design innovation
Aug 30, 2022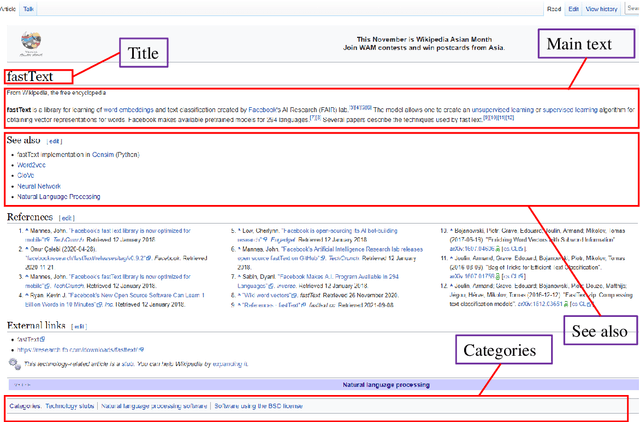
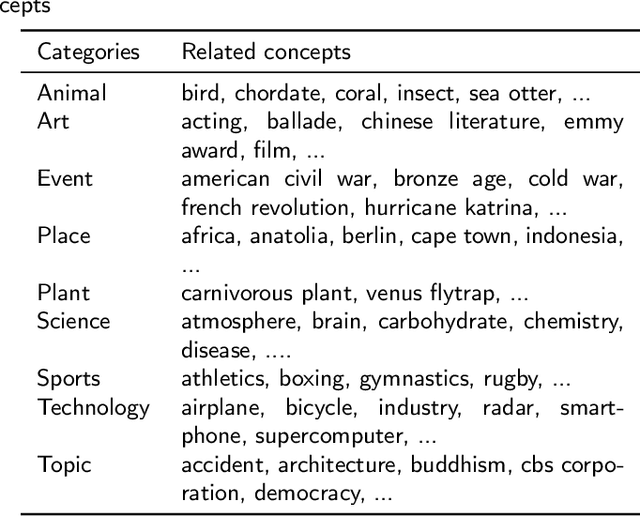
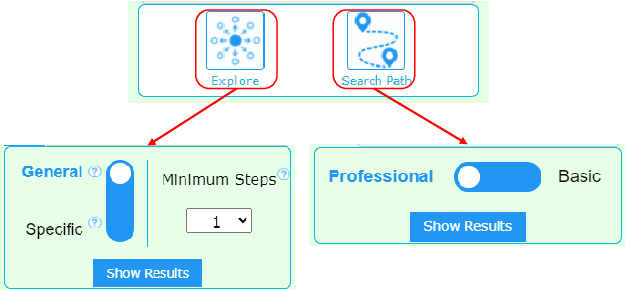
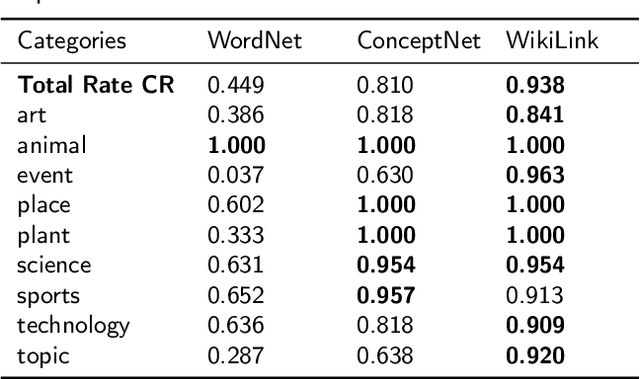
Data-driven design and innovation is a process to reuse and provide valuable and useful information. However, existing semantic networks for design innovation is built on data source restricted to technological and scientific information. Besides, existing studies build the edges of a semantic network only on either statistical or semantic relationships, which is less likely to make full use of the benefits from both types of relationships and discover implicit knowledge for design innovation. Therefore, we constructed WikiLink, a semantic network based on Wikipedia. Combined weight which fuses both the statistic and semantic weights between concepts is introduced in WikiLink, and four algorithms are developed for inspiring new ideas. Evaluation experiments are undertaken and results show that the network is characterised by high coverage of terms, relationships and disciplines, which proves the network's effectiveness and usefulness. Then a demonstration and case study results indicate that WikiLink can serve as an idea generation tool for innovation in conceptual design. The source code of WikiLink and the backend data are provided open-source for more users to explore and build on.
Model Stability with Continuous Data Updates
Jan 14, 2022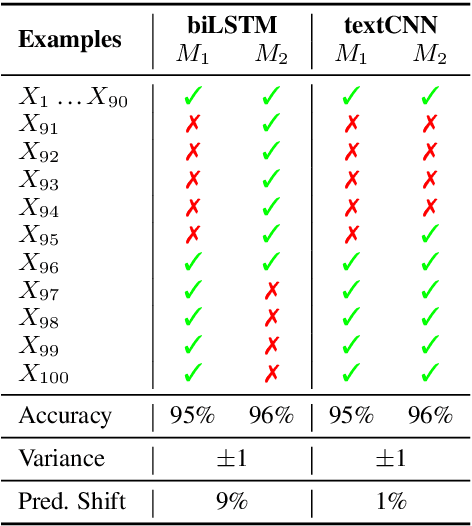
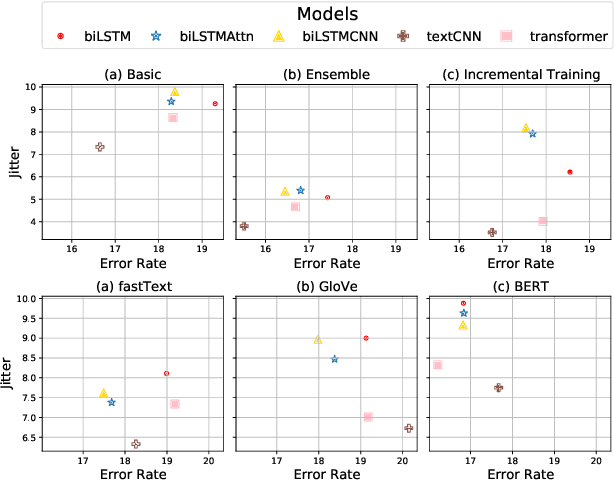
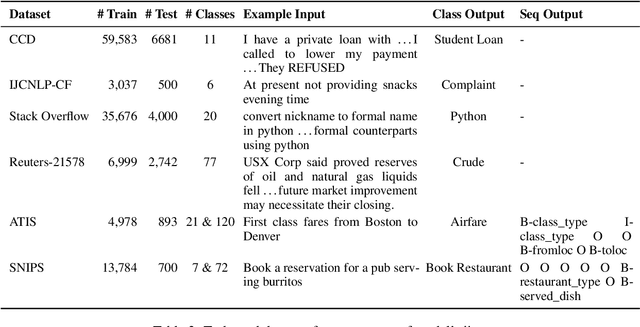
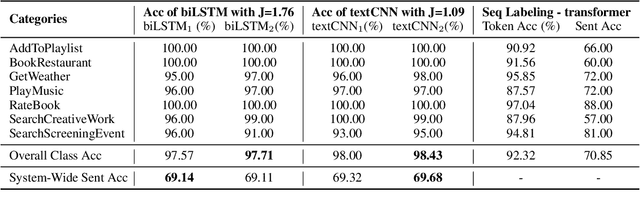
In this paper, we study the "stability" of machine learning (ML) models within the context of larger, complex NLP systems with continuous training data updates. For this study, we propose a methodology for the assessment of model stability (which we refer to as jitter under various experimental conditions. We find that model design choices, including network architecture and input representation, have a critical impact on stability through experiments on four text classification tasks and two sequence labeling tasks. In classification tasks, non-RNN-based models are observed to be more stable than RNN-based ones, while the encoder-decoder model is less stable in sequence labeling tasks. Moreover, input representations based on pre-trained fastText embeddings contribute to more stability than other choices. We also show that two learning strategies -- ensemble models and incremental training -- have a significant influence on stability. We recommend ML model designers account for trade-offs in accuracy and jitter when making modeling choices.
RubyStar: A Non-Task-Oriented Mixture Model Dialog System
Dec 16, 2017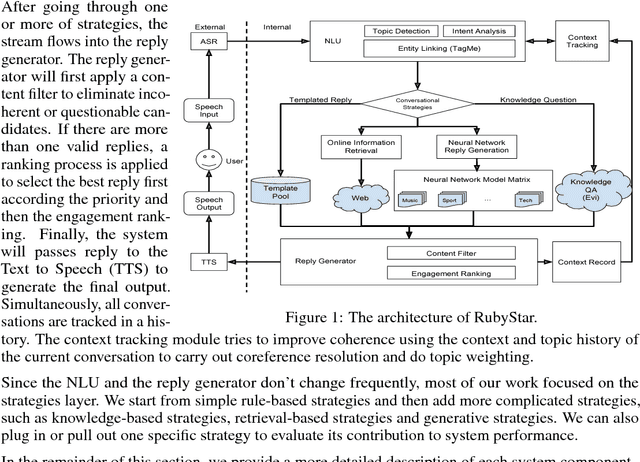


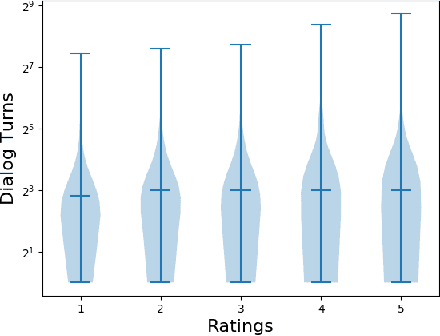
RubyStar is a dialog system designed to create "human-like" conversation by combining different response generation strategies. RubyStar conducts a non-task-oriented conversation on general topics by using an ensemble of rule-based, retrieval-based and generative methods. Topic detection, engagement monitoring, and context tracking are used for managing interaction. Predictable elements of conversation, such as the bot's backstory and simple question answering are handled by separate modules. We describe a rating scheme we developed for evaluating response generation. We find that character-level RNN is an effective generation model for general responses, with proper parameter settings; however other kinds of conversation topics might benefit from using other models.