 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReliable Model Compression via Label-Preservation-Aware Loss Functions
Paper and Code
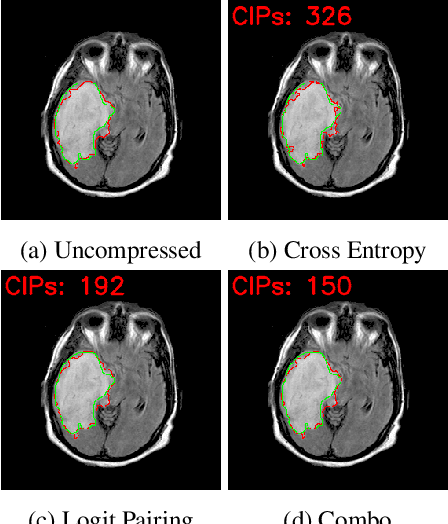
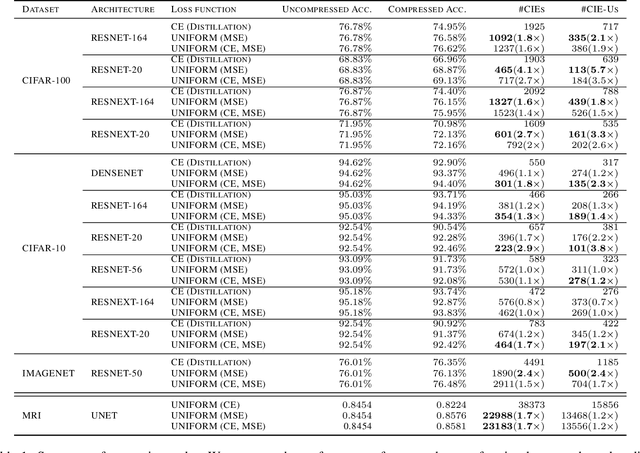
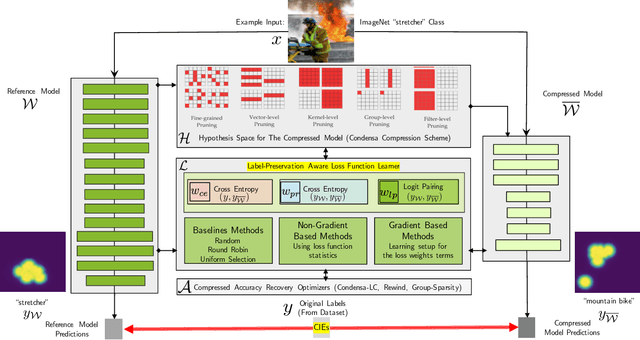
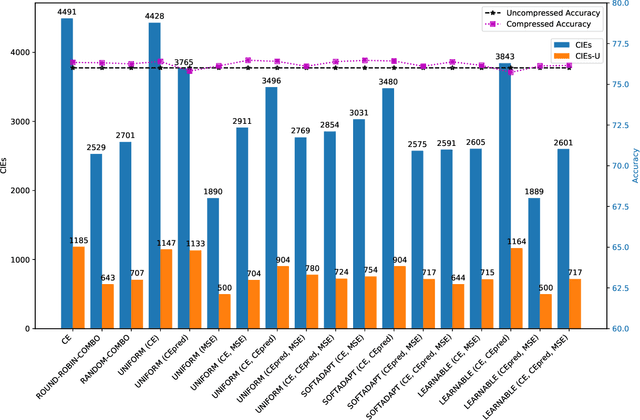
Model compression is a ubiquitous tool that brings the power of modern deep learning to edge devices with power and latency constraints. The goal of model compression is to take a large reference neural network and output a smaller and less expensive compressed network that is functionally equivalent to the reference. Compression typically involves pruning and/or quantization, followed by re-training to maintain the reference accuracy. However, it has been observed that compression can lead to a considerable mismatch in the labels produced by the reference and the compressed models, resulting in bias and unreliability. To combat this, we present a framework that uses a teacher-student learning paradigm to better preserve labels. We investigate the role of additional terms to the loss function and show how to automatically tune the associated parameters. We demonstrate the effectiveness of our approach both quantitatively and qualitatively on multiple compression schemes and accuracy recovery algorithms using a set of 8 different real-world network architectures. We obtain a significant reduction of up to 4.1X in the number of mismatches between the compressed and reference models, and up to 5.7X in cases where the reference model makes the correct prediction.