 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversary-Robust Learning from Fully Asynchronous Directional Derivative Estimates
May 10, 2026We propose FAR-SIGN (Fully Asynchronous Robust optimization via SIGNed directional projections) for adversary-resilient learning in parameter-server--worker systems. FAR-SIGN achieves robustness through sign-based updates along carefully designed directions and mitigates the resulting bias via a two-timescale mechanism. It admits both first-order and zeroth-order implementations and enables fully asynchronous execution without requiring a private reference dataset at the server. We establish almost-sure convergence of FAR-SIGN to the set of stationary points for smooth, nonconvex objectives. Moreover, we prove the near-optimal rate of $O(n^{-1/4+ε})$ in the first-order setting and the standard $O(n^{-1/6+ε})$ in the zeroth-order setting, where $n$ is the iteration count and $ε>0$ can be chosen arbitrarily small. Experiments on MNIST show that FAR-SIGN outperforms robust aggregation-based methods in both accuracy and wall-clock time.
Tight Convergence Rates for Online Distributed Linear Estimation with Adversarial Measurements
Apr 07, 2026We study mean estimation of a random vector $X$ in a distributed parameter-server-worker setup. Worker $i$ observes samples of $a_i^\top X$, where $a_i^\top$ is the $i$th row of a known sensing matrix $A$. The key challenges are adversarial measurements and asynchrony: a fixed subset of workers may transmit corrupted measurements, and workers are activated asynchronously--only one is active at any time. In our previous work, we proposed a two-timescale $\ell_1$-minimization algorithm and established asymptotic recovery under a null-space-property-like condition on $A$. In this work, we establish tight non-asymptotic convergence rates under the same null-space-property-like condition. We also identify relaxed conditions on $A$ under which exact recovery may fail but recovery of a projected component of $\mathbb{E}[X]$ remains possible. Overall, our results provide a unified finite-time characterization of robustness, identifiability, and statistical efficiency in distributed linear estimation with adversarial workers, with implications for network tomography and related distributed sensing problems.
Online Learning of Weakly Coupled MDP Policies for Load Balancing and Auto Scaling
Jun 20, 2024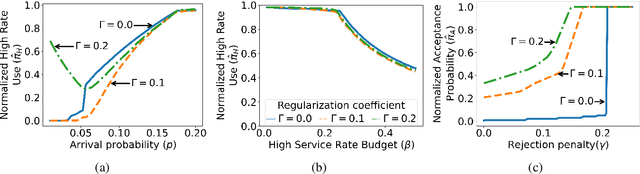
Load balancing and auto scaling are at the core of scalable, contemporary systems, addressing dynamic resource allocation and service rate adjustments in response to workload changes. This paper introduces a novel model and algorithms for tuning load balancers coupled with auto scalers, considering bursty traffic arriving at finite queues. We begin by presenting the problem as a weakly coupled Markov Decision Processes (MDP), solvable via a linear program (LP). However, as the number of control variables of such LP grows combinatorially, we introduce a more tractable relaxed LP formulation, and extend it to tackle the problem of online parameter learning and policy optimization using a two-timescale algorithm based on the LP Lagrangian.
A Practical Approach to Novel Class Discovery in Tabular Data
Nov 09, 2023The problem of Novel Class Discovery (NCD) consists in extracting knowledge from a labeled set of known classes to accurately partition an unlabeled set of novel classes. While NCD has recently received a lot of attention from the community, it is often solved on computer vision problems and under unrealistic conditions. In particular, the number of novel classes is usually assumed to be known in advance, and their labels are sometimes used to tune hyperparameters. Methods that rely on these assumptions are not applicable in real-world scenarios. In this work, we focus on solving NCD in tabular data when no prior knowledge of the novel classes is available. To this end, we propose to tune the hyperparameters of NCD methods by adapting the $k$-fold cross-validation process and hiding some of the known classes in each fold. Since we have found that methods with too many hyperparameters are likely to overfit these hidden classes, we define a simple deep NCD model. This method is composed of only the essential elements necessary for the NCD problem and performs impressively well under realistic conditions. Furthermore, we find that the latent space of this method can be used to reliably estimate the number of novel classes. Additionally, we adapt two unsupervised clustering algorithms ($k$-means and Spectral Clustering) to leverage the knowledge of the known classes. Extensive experiments are conducted on 7 tabular datasets and demonstrate the effectiveness of the proposed method and hyperparameter tuning process, and show that the NCD problem can be solved without relying on knowledge from the novel classes.
An Interactive Interface for Novel Class Discovery in Tabular Data
Jun 22, 2023

Novel Class Discovery (NCD) is the problem of trying to discover novel classes in an unlabeled set, given a labeled set of different but related classes. The majority of NCD methods proposed so far only deal with image data, despite tabular data being among the most widely used type of data in practical applications. To interpret the results of clustering or NCD algorithms, data scientists need to understand the domain- and application-specific attributes of tabular data. This task is difficult and can often only be performed by a domain expert. Therefore, this interface allows a domain expert to easily run state-of-the-art algorithms for NCD in tabular data. With minimal knowledge in data science, interpretable results can be generated.
Online Learning with Adversaries: A Differential Inclusion Analysis
Apr 04, 2023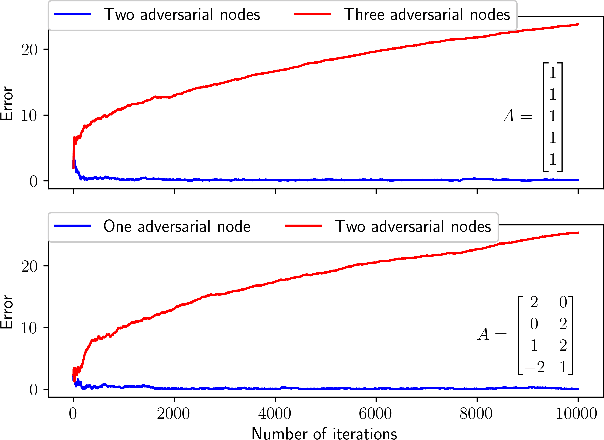
We consider the measurement model $Y = AX,$ where $X$ and, hence, $Y$ are random variables and $A$ is an a priori known tall matrix. At each time instance, a sample of one of $Y$'s coordinates is available, and the goal is to estimate $\mu := \mathbb{E}[X]$ via these samples. However, the challenge is that a small but unknown subset of $Y$'s coordinates are controlled by adversaries with infinite power: they can return any real number each time they are queried for a sample. For such an adversarial setting, we propose the first asynchronous online algorithm that converges to $\mu$ almost surely. We prove this result using a novel differential inclusion based two-timescale analysis. Two key highlights of our proof include: (a) the use of a novel Lyapunov function for showing that $\mu$ is the unique global attractor for our algorithm's limiting dynamics, and (b) the use of martingale and stopping time theory to show that our algorithm's iterates are almost surely bounded.
Novel Class Discovery: an Introduction and Key Concepts
Feb 22, 2023



Novel Class Discovery (NCD) is a growing field where we are given during training a labeled set of known classes and an unlabeled set of different classes that must be discovered. In recent years, many methods have been proposed to address this problem, and the field has begun to mature. In this paper, we provide a comprehensive survey of the state-of-the-art NCD methods. We start by formally defining the NCD problem and introducing important notions. We then give an overview of the different families of approaches, organized by the way they transfer knowledge from the labeled set to the unlabeled set. We find that they either learn in two stages, by first extracting knowledge from the labeled data only and then applying it to the unlabeled data, or in one stage by conjointly learning on both sets. For each family, we describe their general principle and detail a few representative methods. Then, we briefly introduce some new related tasks inspired by the increasing number of NCD works. We also present some common tools and techniques used in NCD, such as pseudo labeling, self-supervised learning and contrastive learning. Finally, to help readers unfamiliar with the NCD problem differentiate it from other closely related domains, we summarize some of the closest areas of research and discuss their main differences.
Découvrir de nouvelles classes dans des données tabulaires
Nov 28, 2022In Novel Class Discovery (NCD), the goal is to find new classes in an unlabeled set given a labeled set of known but different classes. While NCD has recently gained attention from the community, no framework has yet been proposed for heterogeneous tabular data, despite being a very common representation of data. In this paper, we propose TabularNCD, a new method for discovering novel classes in tabular data. We show a way to extract knowledge from already known classes to guide the discovery process of novel classes in the context of tabular data which contains heterogeneous variables. A part of this process is done by a new method for defining pseudo labels, and we follow recent findings in Multi-Task Learning to optimize a joint objective function. Our method demonstrates that NCD is not only applicable to images but also to heterogeneous tabular data.
Geometry-preserving lie group integrators for differential equations on the manifold of symmetric positive definite matrices
Oct 17, 2022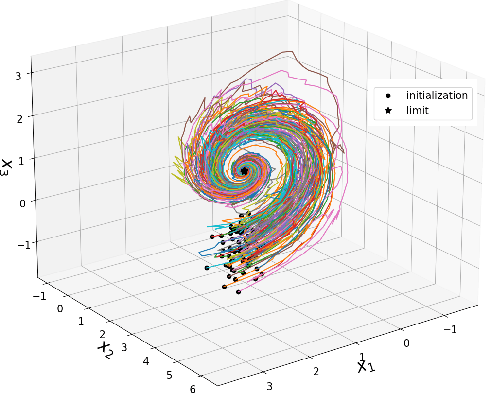
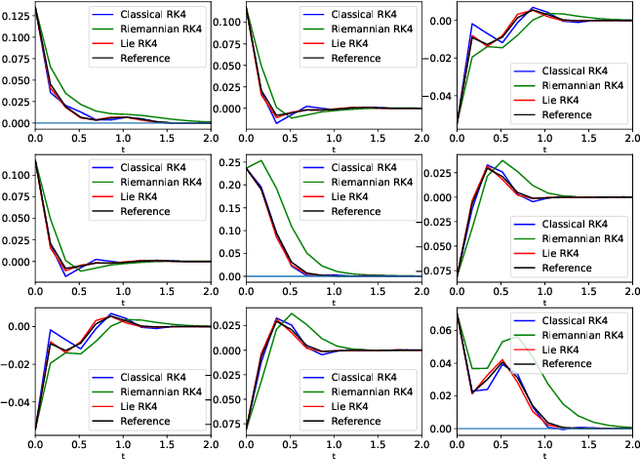
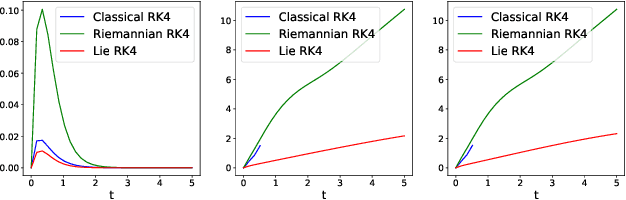
In many applications, one encounters signals that lie on manifolds rather than a Euclidean space. In particular, covariance matrices are examples of ubiquitous mathematical objects that have a non Euclidean structure. The application of Euclidean methods to integrate differential equations lying on such objects does not respect the geometry of the manifold, which can cause many numerical issues. In this paper, we propose to use Lie group methods to define geometry-preserving numerical integration schemes on the manifold of symmetric positive definite matrices. These can be applied to a number of differential equations on covariance matrices of practical interest. We show that they are more stable and robust than other classical or naive integration schemes on an example.
Online Multi-Agent Decentralized Byzantine-robust Gradient Estimation
Sep 30, 2022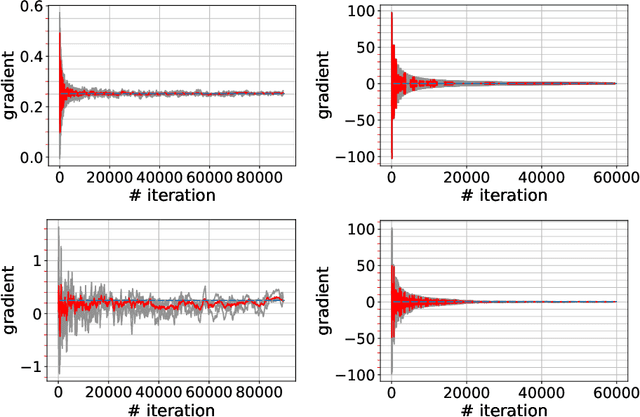
In this paper, we propose an iterative scheme for distributed Byzantineresilient estimation of a gradient associated with a black-box model. Our algorithm is based on simultaneous perturbation, secure state estimation and two-timescale stochastic approximations. We also show the performance of our algorithm through numerical experiments.