 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Practical Approach to Novel Class Discovery in Tabular Data
Nov 09, 2023The problem of Novel Class Discovery (NCD) consists in extracting knowledge from a labeled set of known classes to accurately partition an unlabeled set of novel classes. While NCD has recently received a lot of attention from the community, it is often solved on computer vision problems and under unrealistic conditions. In particular, the number of novel classes is usually assumed to be known in advance, and their labels are sometimes used to tune hyperparameters. Methods that rely on these assumptions are not applicable in real-world scenarios. In this work, we focus on solving NCD in tabular data when no prior knowledge of the novel classes is available. To this end, we propose to tune the hyperparameters of NCD methods by adapting the $k$-fold cross-validation process and hiding some of the known classes in each fold. Since we have found that methods with too many hyperparameters are likely to overfit these hidden classes, we define a simple deep NCD model. This method is composed of only the essential elements necessary for the NCD problem and performs impressively well under realistic conditions. Furthermore, we find that the latent space of this method can be used to reliably estimate the number of novel classes. Additionally, we adapt two unsupervised clustering algorithms ($k$-means and Spectral Clustering) to leverage the knowledge of the known classes. Extensive experiments are conducted on 7 tabular datasets and demonstrate the effectiveness of the proposed method and hyperparameter tuning process, and show that the NCD problem can be solved without relying on knowledge from the novel classes.
An Interactive Interface for Novel Class Discovery in Tabular Data
Jun 22, 2023

Novel Class Discovery (NCD) is the problem of trying to discover novel classes in an unlabeled set, given a labeled set of different but related classes. The majority of NCD methods proposed so far only deal with image data, despite tabular data being among the most widely used type of data in practical applications. To interpret the results of clustering or NCD algorithms, data scientists need to understand the domain- and application-specific attributes of tabular data. This task is difficult and can often only be performed by a domain expert. Therefore, this interface allows a domain expert to easily run state-of-the-art algorithms for NCD in tabular data. With minimal knowledge in data science, interpretable results can be generated.
Novel Class Discovery: an Introduction and Key Concepts
Feb 22, 2023



Novel Class Discovery (NCD) is a growing field where we are given during training a labeled set of known classes and an unlabeled set of different classes that must be discovered. In recent years, many methods have been proposed to address this problem, and the field has begun to mature. In this paper, we provide a comprehensive survey of the state-of-the-art NCD methods. We start by formally defining the NCD problem and introducing important notions. We then give an overview of the different families of approaches, organized by the way they transfer knowledge from the labeled set to the unlabeled set. We find that they either learn in two stages, by first extracting knowledge from the labeled data only and then applying it to the unlabeled data, or in one stage by conjointly learning on both sets. For each family, we describe their general principle and detail a few representative methods. Then, we briefly introduce some new related tasks inspired by the increasing number of NCD works. We also present some common tools and techniques used in NCD, such as pseudo labeling, self-supervised learning and contrastive learning. Finally, to help readers unfamiliar with the NCD problem differentiate it from other closely related domains, we summarize some of the closest areas of research and discuss their main differences.
Découvrir de nouvelles classes dans des données tabulaires
Nov 28, 2022In Novel Class Discovery (NCD), the goal is to find new classes in an unlabeled set given a labeled set of known but different classes. While NCD has recently gained attention from the community, no framework has yet been proposed for heterogeneous tabular data, despite being a very common representation of data. In this paper, we propose TabularNCD, a new method for discovering novel classes in tabular data. We show a way to extract knowledge from already known classes to guide the discovery process of novel classes in the context of tabular data which contains heterogeneous variables. A part of this process is done by a new method for defining pseudo labels, and we follow recent findings in Multi-Task Learning to optimize a joint objective function. Our method demonstrates that NCD is not only applicable to images but also to heterogeneous tabular data.
A Method for Discovering Novel Classes in Tabular Data
Sep 02, 2022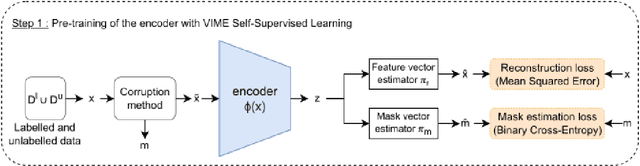
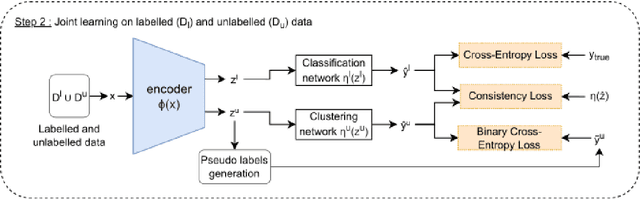
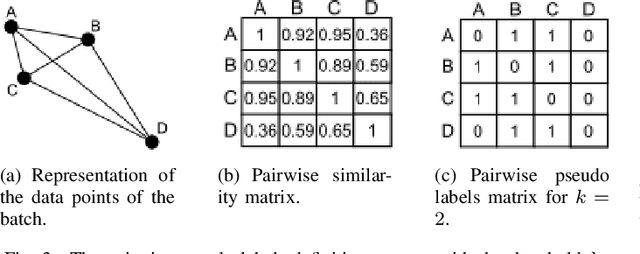
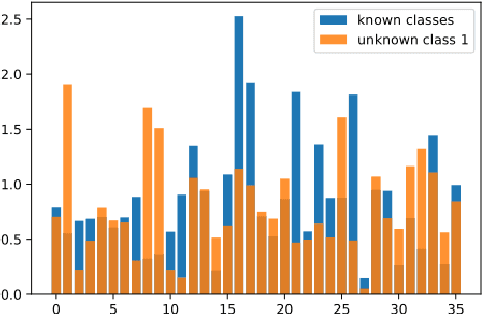
In Novel Class Discovery (NCD), the goal is to find new classes in an unlabeled set given a labeled set of known but different classes. While NCD has recently gained attention from the community, no framework has yet been proposed for heterogeneous tabular data, despite being a very common representation of data. In this paper, we propose TabularNCD, a new method for discovering novel classes in tabular data. We show a way to extract knowledge from already known classes to guide the discovery process of novel classes in the context of tabular data which contains heterogeneous variables. A part of this process is done by a new method for defining pseudo labels, and we follow recent findings in Multi-Task Learning to optimize a joint objective function. Our method demonstrates that NCD is not only applicable to images but also to heterogeneous tabular data. Extensive experiments are conducted to evaluate our method and demonstrate its effectiveness against 3 competitors on 7 diverse public classification datasets.
On the Variational Posterior of Dirichlet Process Deep Latent Gaussian Mixture Models
Jun 16, 2020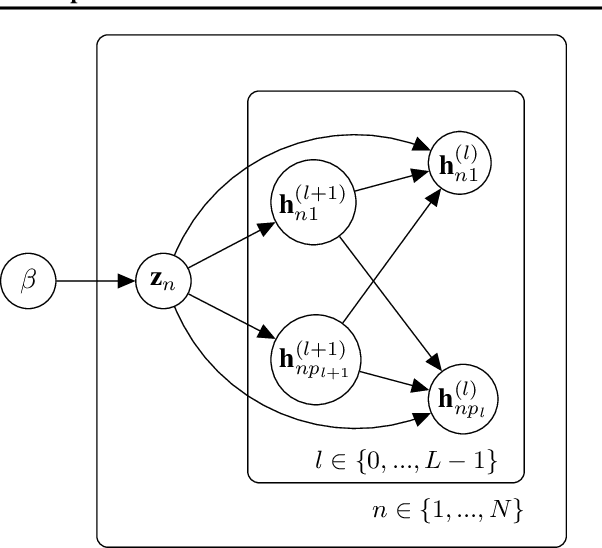

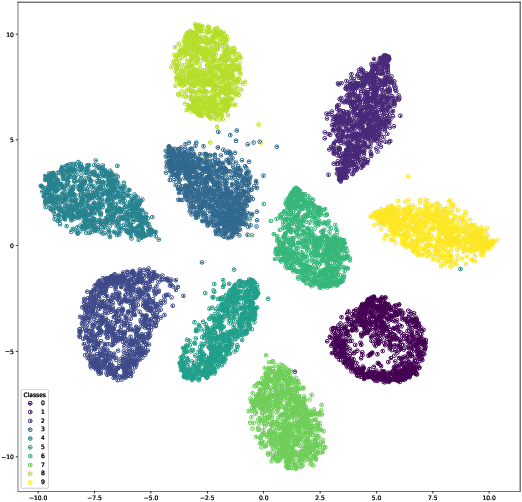
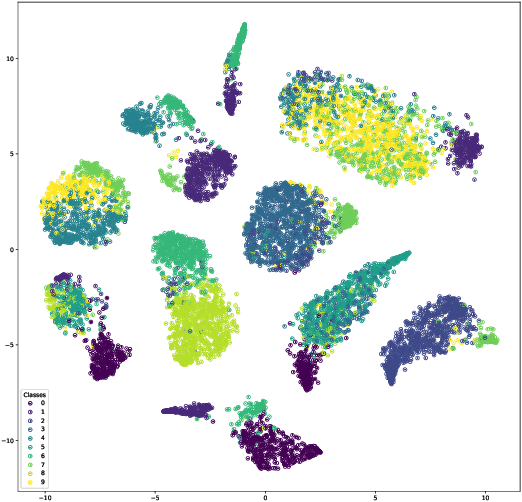
Thanks to the reparameterization trick, deep latent Gaussian models have shown tremendous success recently in learning latent representations. The ability to couple them however with nonparamet-ric priors such as the Dirichlet Process (DP) hasn't seen similar success due to its non parameteriz-able nature. In this paper, we present an alternative treatment of the variational posterior of the Dirichlet Process Deep Latent Gaussian Mixture Model (DP-DLGMM), where we show that the prior cluster parameters and the variational posteriors of the beta distributions and cluster hidden variables can be updated in closed-form. This leads to a standard reparameterization trick on the Gaussian latent variables knowing the cluster assignments. We demonstrate our approach on standard benchmark datasets, we show that our model is capable of generating realistic samples for each cluster obtained, and manifests competitive performance in a semi-supervised setting.
Large-Scale Characterization and Segmentation of Internet Path Delays with Infinite HMMs
Oct 28, 2019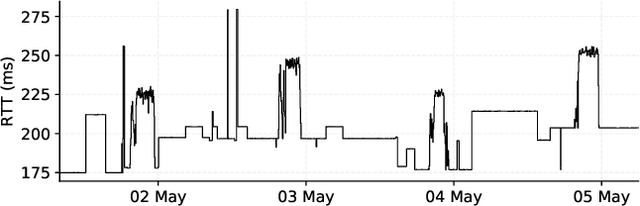
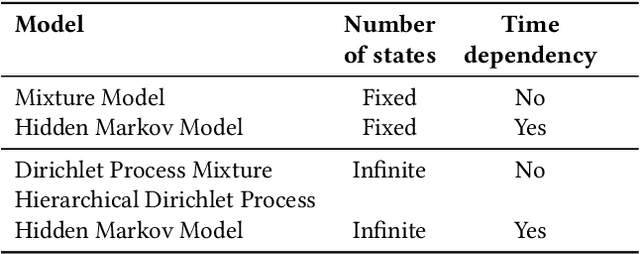
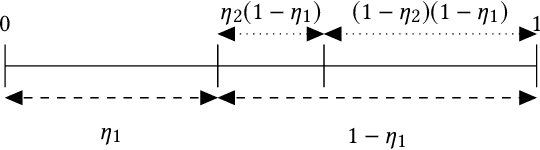

Round-Trip Times are one of the most commonly collected performance metrics in computer networks. Measurement platforms such as RIPE Atlas provide researchers and network operators with an unprecedented amount of historical Internet delay measurements. It would be very useful to automate the processing of these measurements (statistical characterization of paths performance, change detection, recognition of recurring patterns, etc.). Humans are pretty good at finding patterns in network measurements but it can be difficult to automate this to enable many time series being processed at the same time. In this article we introduce a new model, the HDP-HMM or infinite hidden Markov model, whose performance in trace segmentation is very close to human cognition. This is obtained at the cost of a greater complexity and the ambition of this article is to make the theory accessible to network monitoring and management researchers. We demonstrate that this model provides very accurate results on a labeled dataset and on RIPE Atlas and CAIDA MANIC data. This method has been implemented in Atlas and we introduce the publicly accessible Web API.