 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAitchison Geometry on the Simplex for Uncertainty Quantification in Bayesian Hyperspectral Image Unmixing
Mar 25, 2026Most algorithms for hyperspectral image unmixing produce point estimates of fractional abundances of the materials to be separated. However, in the absence of reliable ground truth, the ability to perform abundance uncertainty quantification (UQ) should be an important feature of algorithms, e.g. to evaluate how hard the unmixing problem is and how much the results should be trusted. The usual modeling assumptions in Bayesian models for unmixing rely heavily on the Euclidean geometry of the simplex and typically disregard spatial information. In addition, to our knowledge, abundance UQ is close to nonexistent. In this paper, we propose to leverage Aitchinson geometry from the compositional data analysis literature to provide practitioners with alternative tools for modeling prior abundance distributions. In particular we show how to design simplex-valued Gaussian Process priors using this geometry. Then we link Aitchinson geometry to constrained sampling algorithms in the literature, and propose UQ diagnostics that comply with the constraints on abundance vectors. We illustrate these concepts on real and simulated data.
A fast Multiplicative Updates algorithm for Non-negative Matrix Factorization
Mar 31, 2023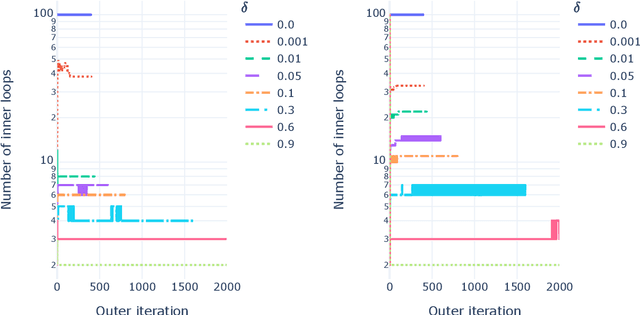



Nonnegative Matrix Factorization is an important tool in unsupervised machine learning to decompose a data matrix into a product of parts that are often interpretable. Many algorithms have been proposed during the last three decades. A well-known method is the Multiplicative Updates algorithm proposed by Lee and Seung in 2002. Multiplicative updates have many interesting features: they are simple to implement and can be adapted to popular variants such as sparse Nonnegative Matrix Factorization, and, according to recent benchmarks, is state-of-the-art for many problems where the loss function is not the Frobenius norm. In this manuscript, we propose to improve the Multiplicative Updates algorithm seen as an alternating majorization minimization algorithm by crafting a tighter upper bound of the Hessian matrix for each alternate subproblem. Convergence is still ensured and we observe in practice on both synthetic and real world dataset that the proposed fastMU algorithm is often several orders of magnitude faster than the regular Multiplicative Updates algorithm, and can even be competitive with state-of-the-art methods for the Frobenius loss.
Large-Scale Characterization and Segmentation of Internet Path Delays with Infinite HMMs
Oct 28, 2019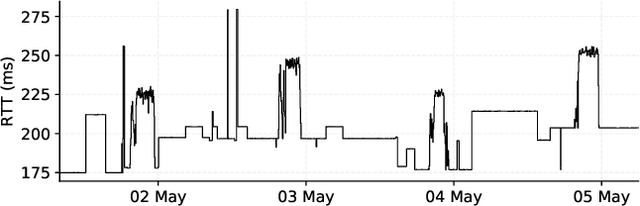
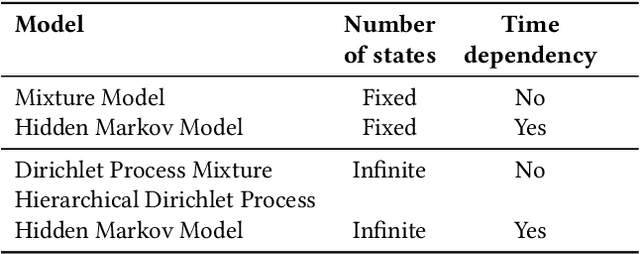
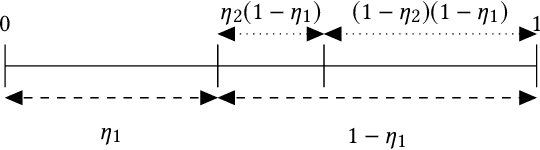

Round-Trip Times are one of the most commonly collected performance metrics in computer networks. Measurement platforms such as RIPE Atlas provide researchers and network operators with an unprecedented amount of historical Internet delay measurements. It would be very useful to automate the processing of these measurements (statistical characterization of paths performance, change detection, recognition of recurring patterns, etc.). Humans are pretty good at finding patterns in network measurements but it can be difficult to automate this to enable many time series being processed at the same time. In this article we introduce a new model, the HDP-HMM or infinite hidden Markov model, whose performance in trace segmentation is very close to human cognition. This is obtained at the cost of a greater complexity and the ambition of this article is to make the theory accessible to network monitoring and management researchers. We demonstrate that this model provides very accurate results on a labeled dataset and on RIPE Atlas and CAIDA MANIC data. This method has been implemented in Atlas and we introduce the publicly accessible Web API.