 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn associative neural networks for sparse patterns with huge capacities
Mar 27, 2026Generalized Hopfield models with higher-order or exponential interaction terms are known to have substantially larger storage capacities than the classical quadratic model. On the other hand, associative memories for sparse patterns, such as the Willshaw and Amari models, already outperform the classical Hopfield model in the sparse regime. In this paper we combine these two mechanisms. We introduce higher-order versions of sparse associative memory models and study their storage capacities. For fixed interaction order $n$, we obtain storage capacities of polynomial order in the system size. When the interaction order is allowed to grow logarithmically with the number of neurons, this yields super-polynomial capacities. We also discuss an analogue in the Gripon--Berrou architecture which was formulated for non-sparse messages (see \cite{griponc}). Our results show that the capacity increase caused by higher-order interactions persists in the sparse setting, although the precise storage scale depends on the underlying architecture.
FlowKac: An Efficient Neural Fokker-Planck solver using Temporal Normalizing flows and the Feynman Kac-Formula
Mar 14, 2025Solving the Fokker-Planck equation for high-dimensional complex dynamical systems remains a pivotal yet challenging task due to the intractability of analytical solutions and the limitations of traditional numerical methods. In this work, we present FlowKac, a novel approach that reformulates the Fokker-Planck equation using the Feynman-Kac formula, allowing to query the solution at a given point via the expected values of stochastic paths. A key innovation of FlowKac lies in its adaptive stochastic sampling scheme which significantly reduces the computational complexity while maintaining high accuracy. This sampling technique, coupled with a time-indexed normalizing flow, designed for capturing time-evolving probability densities, enables robust sampling of collocation points, resulting in a flexible and mesh-free solver. This formulation mitigates the curse of dimensionality and enhances computational efficiency and accuracy, which is particularly crucial for applications that inherently require dimensions beyond the conventional three. We validate the robustness and scalability of our method through various experiments on a range of stochastic differential equations, demonstrating significant improvements over existing techniques.
Training LayoutLM from Scratch for Efficient Named-Entity Recognition in the Insurance Domain
Dec 12, 2024



Generic pre-trained neural networks may struggle to produce good results in specialized domains like finance and insurance. This is due to a domain mismatch between training data and downstream tasks, as in-domain data are often scarce due to privacy constraints. In this work, we compare different pre-training strategies for LayoutLM. We show that using domain-relevant documents improves results on a named-entity recognition (NER) problem using a novel dataset of anonymized insurance-related financial documents called Payslips. Moreover, we show that we can achieve competitive results using a smaller and faster model.
Oops, I Sampled it Again: Reinterpreting Confidence Intervals in Few-Shot Learning
Sep 04, 2024



The predominant method for computing confidence intervals (CI) in few-shot learning (FSL) is based on sampling the tasks with replacement, i.e.\ allowing the same samples to appear in multiple tasks. This makes the CI misleading in that it takes into account the randomness of the sampler but not the data itself. To quantify the extent of this problem, we conduct a comparative analysis between CIs computed with and without replacement. These reveal a notable underestimation by the predominant method. This observation calls for a reevaluation of how we interpret confidence intervals and the resulting conclusions in FSL comparative studies. Our research demonstrates that the use of paired tests can partially address this issue. Additionally, we explore methods to further reduce the (size of the) CI by strategically sampling tasks of a specific size. We also introduce a new optimized benchmark, which can be accessed at https://github.com/RafLaf/FSL-benchmark-again
Time-changed normalizing flows for accurate SDE modeling
Jan 15, 2024



The generative paradigm has become increasingly important in machine learning and deep learning models. Among popular generative models are normalizing flows, which enable exact likelihood estimation by transforming a base distribution through diffeomorphic transformations. Extending the normalizing flow framework to handle time-indexed flows gave dynamic normalizing flows, a powerful tool to model time series, stochastic processes, and neural stochastic differential equations (SDEs). In this work, we propose a novel variant of dynamic normalizing flows, a Time Changed Normalizing Flow (TCNF), based on time deformation of a Brownian motion which constitutes a versatile and extensive family of Gaussian processes. This approach enables us to effectively model some SDEs, that cannot be modeled otherwise, including standard ones such as the well-known Ornstein-Uhlenbeck process, and generalizes prior methodologies, leading to improved results and better inference and prediction capability.
Measuring and Mitigating Biases in Motor Insurance Pricing
Nov 20, 2023



The non-life insurance sector operates within a highly competitive and tightly regulated framework, confronting a pivotal juncture in the formulation of pricing strategies. Insurers are compelled to harness a range of statistical methodologies and available data to construct optimal pricing structures that align with the overarching corporate strategy while accommodating the dynamics of market competition. Given the fundamental societal role played by insurance, premium rates are subject to rigorous scrutiny by regulatory authorities. These rates must conform to principles of transparency, explainability, and ethical considerations. Consequently, the act of pricing transcends mere statistical calculations and carries the weight of strategic and societal factors. These multifaceted concerns may drive insurers to establish equitable premiums, taking into account various variables. For instance, regulations mandate the provision of equitable premiums, considering factors such as policyholder gender or mutualist group dynamics in accordance with respective corporate strategies. Age-based premium fairness is also mandated. In certain insurance domains, variables such as the presence of serious illnesses or disabilities are emerging as new dimensions for evaluating fairness. Regardless of the motivating factor prompting an insurer to adopt fairer pricing strategies for a specific variable, the insurer must possess the capability to define, measure, and ultimately mitigate any ethical biases inherent in its pricing practices while upholding standards of consistency and performance. This study seeks to provide a comprehensive set of tools for these endeavors and assess their effectiveness through practical application in the context of automobile insurance.
Geometry-preserving lie group integrators for differential equations on the manifold of symmetric positive definite matrices
Oct 17, 2022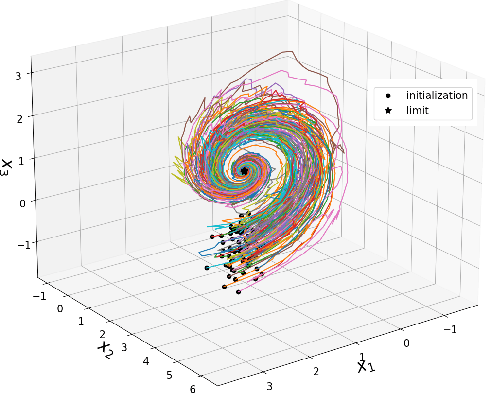
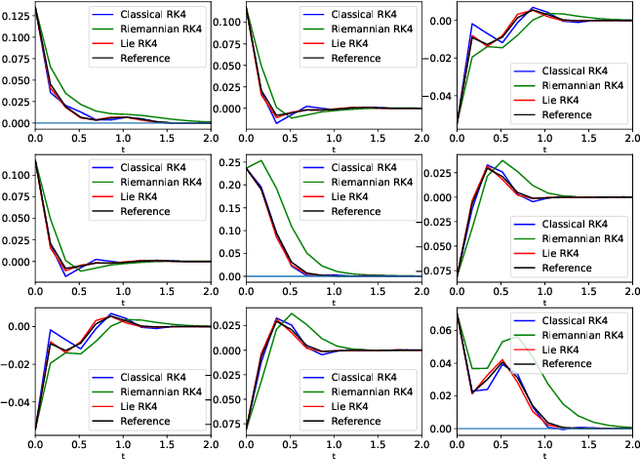
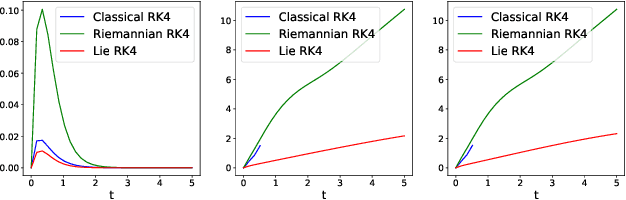
In many applications, one encounters signals that lie on manifolds rather than a Euclidean space. In particular, covariance matrices are examples of ubiquitous mathematical objects that have a non Euclidean structure. The application of Euclidean methods to integrate differential equations lying on such objects does not respect the geometry of the manifold, which can cause many numerical issues. In this paper, we propose to use Lie group methods to define geometry-preserving numerical integration schemes on the manifold of symmetric positive definite matrices. These can be applied to a number of differential equations on covariance matrices of practical interest. We show that they are more stable and robust than other classical or naive integration schemes on an example.
Evaluation of importance estimators in deep learning classifiers for Computed Tomography
Sep 30, 2022Deep learning has shown superb performance in detecting objects and classifying images, ensuring a great promise for analyzing medical imaging. Translating the success of deep learning to medical imaging, in which doctors need to understand the underlying process, requires the capability to interpret and explain the prediction of neural networks. Interpretability of deep neural networks often relies on estimating the importance of input features (e.g., pixels) with respect to the outcome (e.g., class probability). However, a number of importance estimators (also known as saliency maps) have been developed and it is unclear which ones are more relevant for medical imaging applications. In the present work, we investigated the performance of several importance estimators in explaining the classification of computed tomography (CT) images by a convolutional deep network, using three distinct evaluation metrics. First, the model-centric fidelity measures a decrease in the model accuracy when certain inputs are perturbed. Second, concordance between importance scores and the expert-defined segmentation masks is measured on a pixel level by a receiver operating characteristic (ROC) curves. Third, we measure a region-wise overlap between a XRAI-based map and the segmentation mask by Dice Similarity Coefficients (DSC). Overall, two versions of SmoothGrad topped the fidelity and ROC rankings, whereas both Integrated Gradients and SmoothGrad excelled in DSC evaluation. Interestingly, there was a critical discrepancy between model-centric (fidelity) and human-centric (ROC and DSC) evaluation. Expert expectation and intuition embedded in segmentation maps does not necessarily align with how the model arrived at its prediction. Understanding this difference in interpretability would help harnessing the power of deep learning in medicine.
* 4th International Workshop on EXplainable and TRAnsparent AI and Multi-Agent Systems (EXTRAAMAS 2022) - International Conference on Autonomous Agents and Multi-Agent Systems (AAMAS)
Model Transparency and Interpretability : Survey and Application to the Insurance Industry
Sep 01, 2022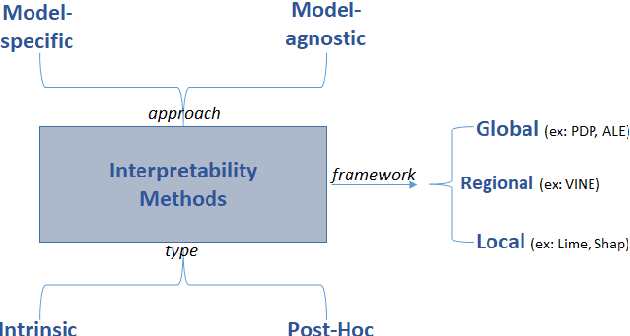

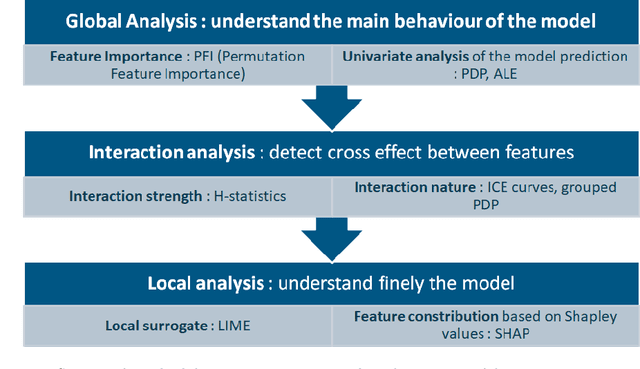
The use of models, even if efficient, must be accompanied by an understanding at all levels of the process that transforms data (upstream and downstream). Thus, needs increase to define the relationships between individual data and the choice that an algorithm could make based on its analysis (e.g. the recommendation of one product or one promotional offer, or an insurance rate representative of the risk). Model users must ensure that models do not discriminate and that it is also possible to explain their results. This paper introduces the importance of model interpretation and tackles the notion of model transparency. Within an insurance context, it specifically illustrates how some tools can be used to enforce the control of actuarial models that can nowadays leverage on machine learning. On a simple example of loss frequency estimation in car insurance, we show the interest of some interpretability methods to adapt explanation to the target audience.
Some Remarks on Replicated Simulated Annealing
Sep 30, 2020


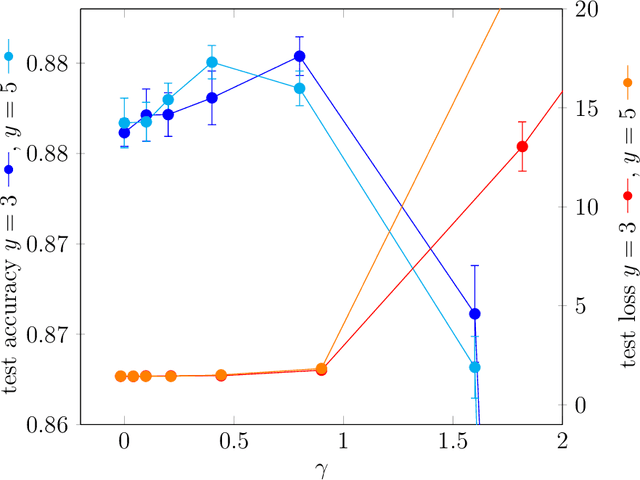
Recently authors have introduced the idea of training discrete weights neural networks using a mix between classical simulated annealing and a replica ansatz known from the statistical physics literature. Among other points, they claim their method is able to find robust configurations. In this paper, we analyze this so-called "replicated simulated annealing" algorithm. In particular, we explicit criteria to guarantee its convergence, and study when it successfully samples from configurations. We also perform experiments using synthetic and real data bases.