 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining LayoutLM from Scratch for Efficient Named-Entity Recognition in the Insurance Domain
Dec 12, 2024



Generic pre-trained neural networks may struggle to produce good results in specialized domains like finance and insurance. This is due to a domain mismatch between training data and downstream tasks, as in-domain data are often scarce due to privacy constraints. In this work, we compare different pre-training strategies for LayoutLM. We show that using domain-relevant documents improves results on a named-entity recognition (NER) problem using a novel dataset of anonymized insurance-related financial documents called Payslips. Moreover, we show that we can achieve competitive results using a smaller and faster model.
Few-Shot Domain Adaptation for Named-Entity Recognition via Joint Constrained k-Means and Subspace Selection
Nov 30, 2024



Named-entity recognition (NER) is a task that typically requires large annotated datasets, which limits its applicability across domains with varying entity definitions. This paper addresses few-shot NER, aiming to transfer knowledge to new domains with minimal supervision. Unlike previous approaches that rely solely on limited annotated data, we propose a weakly supervised algorithm that combines small labeled datasets with large amounts of unlabeled data. Our method extends the k-means algorithm with label supervision, cluster size constraints and domain-specific discriminative subspace selection. This unified framework achieves state-of-the-art results in few-shot NER on several English datasets.
A survey on natural language processing and applications in insurance
Oct 01, 2020
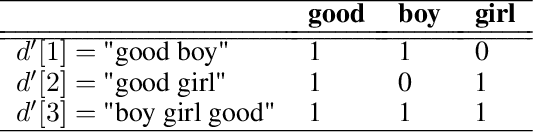

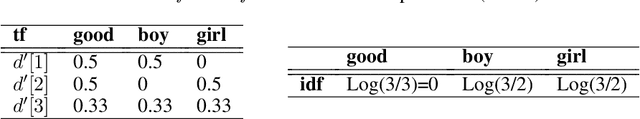
Text is the most widely used means of communication today. This data is abundant but nevertheless complex to exploit within algorithms. For years, scientists have been trying to implement different techniques that enable computers to replicate some mechanisms of human reading. During the past five years, research disrupted the capacity of the algorithms to unleash the value of text data. It brings today, many opportunities for the insurance industry.Understanding those methods and, above all, knowing how to apply them is a major challenge and key to unleash the value of text data that have been stored for many years. Processing language with computer brings many new opportunities especially in the insurance sector where reports are central in the information used by insurers. SCOR's Data Analytics team has been working on the implementation of innovative tools or products that enable the use of the latest research on text analysis. Understanding text mining techniques in insurance enhances the monitoring of the underwritten risks and many processes that finally benefit policyholders.This article proposes to explain opportunities that Natural Language Processing (NLP) are providing to insurance. It details different methods used today in practice traces back the story of them. We also illustrate the implementation of certain methods using open source libraries and python codes that we have developed to facilitate the use of these techniques.After giving a general overview on the evolution of text mining during the past few years,we share about how to conduct a full study with text mining and share some examples to serve those models into insurance products or services. Finally, we explained in more details every step that composes a Natural Language Processing study to ensure the reader can have a deep understanding on the implementation.