 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining LayoutLM from Scratch for Efficient Named-Entity Recognition in the Insurance Domain
Dec 12, 2024



Generic pre-trained neural networks may struggle to produce good results in specialized domains like finance and insurance. This is due to a domain mismatch between training data and downstream tasks, as in-domain data are often scarce due to privacy constraints. In this work, we compare different pre-training strategies for LayoutLM. We show that using domain-relevant documents improves results on a named-entity recognition (NER) problem using a novel dataset of anonymized insurance-related financial documents called Payslips. Moreover, we show that we can achieve competitive results using a smaller and faster model.
AI and ethics in insurance: a new solution to mitigate proxy discrimination in risk modeling
Jul 25, 2023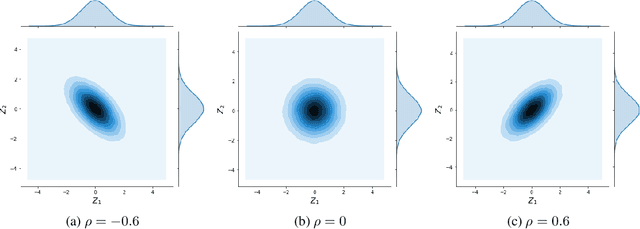



The development of Machine Learning is experiencing growing interest from the general public, and in recent years there have been numerous press articles questioning its objectivity: racism, sexism, \dots Driven by the growing attention of regulators on the ethical use of data in insurance, the actuarial community must rethink pricing and risk selection practices for fairer insurance. Equity is a philosophy concept that has many different definitions in every jurisdiction that influence each other without currently reaching consensus. In Europe, the Charter of Fundamental Rights defines guidelines on discrimination, and the use of sensitive personal data in algorithms is regulated. If the simple removal of the protected variables prevents any so-called `direct' discrimination, models are still able to `indirectly' discriminate between individuals thanks to latent interactions between variables, which bring better performance (and therefore a better quantification of risk, segmentation of prices, and so on). After introducing the key concepts related to discrimination, we illustrate the complexity of quantifying them. We then propose an innovative method, not yet met in the literature, to reduce the risks of indirect discrimination thanks to mathematical concepts of linear algebra. This technique is illustrated in a concrete case of risk selection in life insurance, demonstrating its simplicity of use and its promising performance.
Applying Machine Learning to Life Insurance: some knowledge sharing to master it
Sep 05, 2022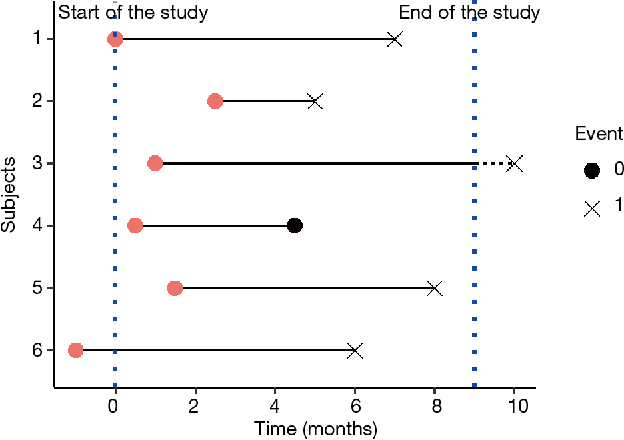
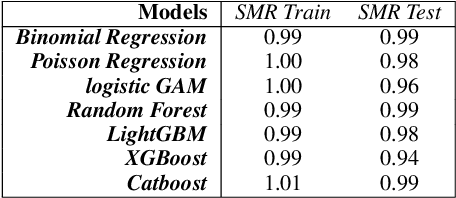

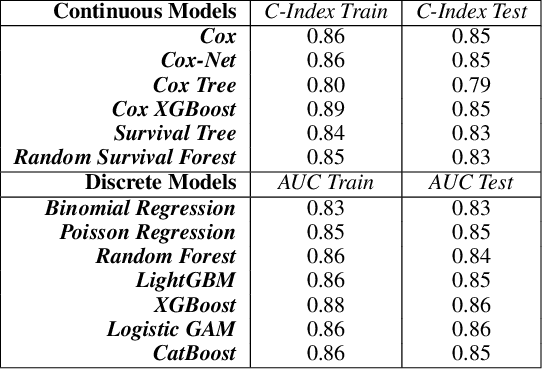
Machine Learning permeates many industries, which brings new source of benefits for companies. However within the life insurance industry, Machine Learning is not widely used in practice as over the past years statistical models have shown their efficiency for risk assessment. Thus insurers may face difficulties to assess the value of the artificial intelligence. Focusing on the modification of the life insurance industry over time highlights the stake of using Machine Learning for insurers and benefits that it can bring by unleashing data value. This paper reviews traditional actuarial methodologies for survival modeling and extends them with Machine Learning techniques. It points out differences with regular machine learning models and emphasizes importance of specific implementations to face censored data with machine learning models family.In complement to this article, a Python library has been developed. Different open-source Machine Learning algorithms have been adjusted to adapt the specificities of life insurance data, namely censoring and truncation. Such models can be easily applied from this SCOR library to accurately model life insurance risks.
Model Transparency and Interpretability : Survey and Application to the Insurance Industry
Sep 01, 2022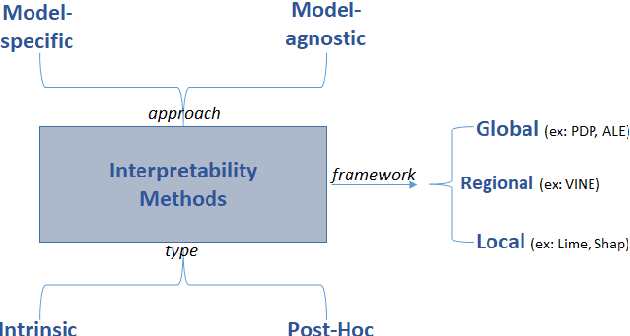

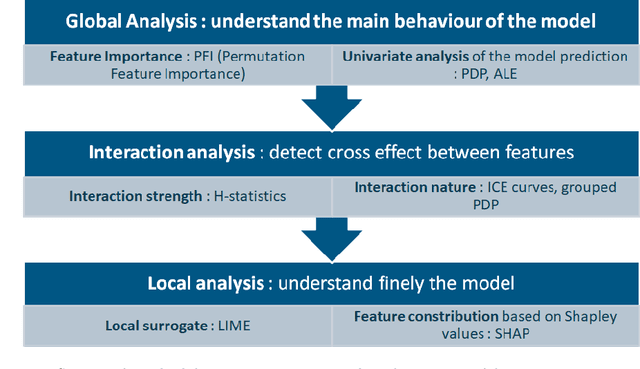
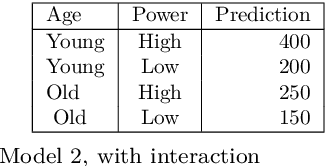
The use of models, even if efficient, must be accompanied by an understanding at all levels of the process that transforms data (upstream and downstream). Thus, needs increase to define the relationships between individual data and the choice that an algorithm could make based on its analysis (e.g. the recommendation of one product or one promotional offer, or an insurance rate representative of the risk). Model users must ensure that models do not discriminate and that it is also possible to explain their results. This paper introduces the importance of model interpretation and tackles the notion of model transparency. Within an insurance context, it specifically illustrates how some tools can be used to enforce the control of actuarial models that can nowadays leverage on machine learning. On a simple example of loss frequency estimation in car insurance, we show the interest of some interpretability methods to adapt explanation to the target audience.
A survey on natural language processing and applications in insurance
Oct 01, 2020
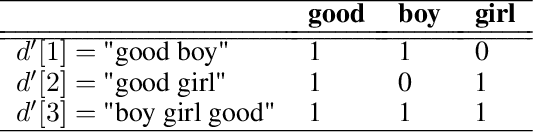

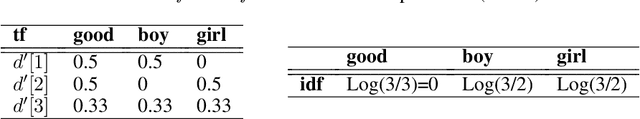
Text is the most widely used means of communication today. This data is abundant but nevertheless complex to exploit within algorithms. For years, scientists have been trying to implement different techniques that enable computers to replicate some mechanisms of human reading. During the past five years, research disrupted the capacity of the algorithms to unleash the value of text data. It brings today, many opportunities for the insurance industry.Understanding those methods and, above all, knowing how to apply them is a major challenge and key to unleash the value of text data that have been stored for many years. Processing language with computer brings many new opportunities especially in the insurance sector where reports are central in the information used by insurers. SCOR's Data Analytics team has been working on the implementation of innovative tools or products that enable the use of the latest research on text analysis. Understanding text mining techniques in insurance enhances the monitoring of the underwritten risks and many processes that finally benefit policyholders.This article proposes to explain opportunities that Natural Language Processing (NLP) are providing to insurance. It details different methods used today in practice traces back the story of them. We also illustrate the implementation of certain methods using open source libraries and python codes that we have developed to facilitate the use of these techniques.After giving a general overview on the evolution of text mining during the past few years,we share about how to conduct a full study with text mining and share some examples to serve those models into insurance products or services. Finally, we explained in more details every step that composes a Natural Language Processing study to ensure the reader can have a deep understanding on the implementation.
Interpretabilité des modèles : état des lieux des méthodes et application à l'assurance
Jul 25, 2020

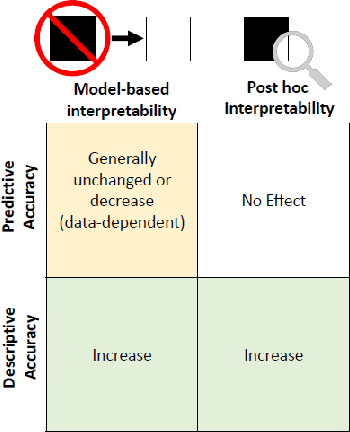
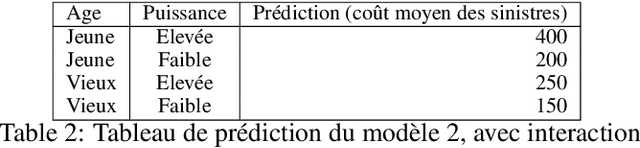
Since May 2018, the General Data Protection Regulation (GDPR) has introduced new obligations to industries. By setting a legal framework, it notably imposes strong transparency on the use of personal data. Thus, people must be informed of the use of their data and must consent the usage of it. Data is the raw material of many models which today make it possible to increase the quality and performance of digital services. Transparency on the use of data also requires a good understanding of its use through different models. The use of models, even if efficient, must be accompanied by an understanding at all levels of the process that transform data (upstream and downstream of a model), thus making it possible to define the relationships between the individual's data and the choice that an algorithm could make based on the analysis of the latter. (For example, the recommendation of one product or one promotional offer or an insurance rate representative of the risk.) Models users must ensure that models do not discriminate against and that it is also possible to explain its result. The widening of the panel of predictive algorithms - made possible by the evolution of computing capacities -- leads scientists to be vigilant about the use of models and to consider new tools to better understand the decisions deduced from them . Recently, the community has been particularly active on model transparency with a marked intensification of publications over the past three years. The increasingly frequent use of more complex algorithms (\textit{deep learning}, Xgboost, etc.) presenting attractive performances is undoubtedly one of the causes of this interest. This article thus presents an inventory of methods of interpreting models and their uses in an insurance context.