 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Transparency and Interpretability : Survey and Application to the Insurance Industry
Sep 01, 2022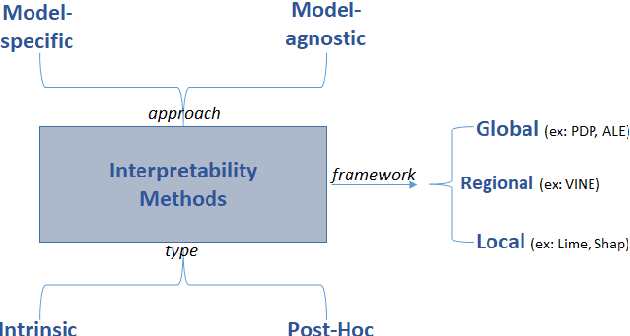

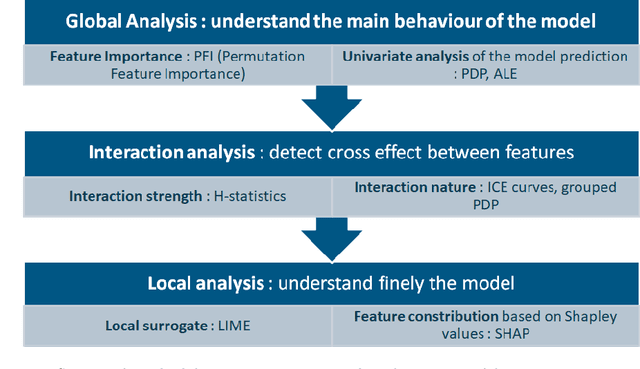
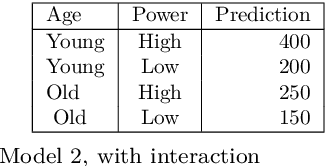
The use of models, even if efficient, must be accompanied by an understanding at all levels of the process that transforms data (upstream and downstream). Thus, needs increase to define the relationships between individual data and the choice that an algorithm could make based on its analysis (e.g. the recommendation of one product or one promotional offer, or an insurance rate representative of the risk). Model users must ensure that models do not discriminate and that it is also possible to explain their results. This paper introduces the importance of model interpretation and tackles the notion of model transparency. Within an insurance context, it specifically illustrates how some tools can be used to enforce the control of actuarial models that can nowadays leverage on machine learning. On a simple example of loss frequency estimation in car insurance, we show the interest of some interpretability methods to adapt explanation to the target audience.
Interpretabilité des modèles : état des lieux des méthodes et application à l'assurance
Jul 25, 2020

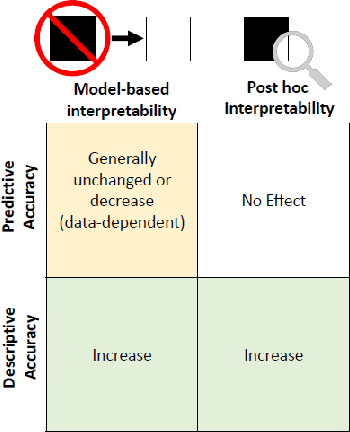
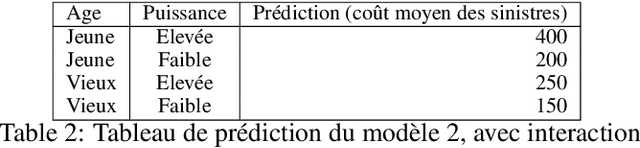
Since May 2018, the General Data Protection Regulation (GDPR) has introduced new obligations to industries. By setting a legal framework, it notably imposes strong transparency on the use of personal data. Thus, people must be informed of the use of their data and must consent the usage of it. Data is the raw material of many models which today make it possible to increase the quality and performance of digital services. Transparency on the use of data also requires a good understanding of its use through different models. The use of models, even if efficient, must be accompanied by an understanding at all levels of the process that transform data (upstream and downstream of a model), thus making it possible to define the relationships between the individual's data and the choice that an algorithm could make based on the analysis of the latter. (For example, the recommendation of one product or one promotional offer or an insurance rate representative of the risk.) Models users must ensure that models do not discriminate against and that it is also possible to explain its result. The widening of the panel of predictive algorithms - made possible by the evolution of computing capacities -- leads scientists to be vigilant about the use of models and to consider new tools to better understand the decisions deduced from them . Recently, the community has been particularly active on model transparency with a marked intensification of publications over the past three years. The increasingly frequent use of more complex algorithms (\textit{deep learning}, Xgboost, etc.) presenting attractive performances is undoubtedly one of the causes of this interest. This article thus presents an inventory of methods of interpreting models and their uses in an insurance context.